







该文参考某大神:https://cuijiahua.com/blog/2017/11/ml_2_decision_tree_1.html
使用决策树做预测需要以下流程:
- 收集数据:从公开的数据源或者其他方式获取 。
- 准备数据:使用numpy等工具处理数据,按照一定的格式存储起来。
- 分析数据:可以使用任何方法,决策树构造完成之后,我们可以检查决策树图形是否符合预期。
- 训练算法:最为重要的阶段。这个过程就是决策树构建阶段,也可以说是决策树学习,就是构造一个决策树的数据结构。
- 测试算法:使用模型去预测测试数据,计算错误率。当错误率达到可接受范围内,这个决策树就可以投放使用了。
- 使用算法:将模型运用到实际业务场景中。
从算法方面看,决策树构建是核心。分为三个步骤:特征选择、决策树的生成和决策树的修剪。
一. 特征选择
特征选择在于选取对训练数据具有分类能力的特征。如果利用一个特征进行分类的结果与随机分类的结果没有很大差别,则这个特征是没有分类能力的。经验上扔掉这样的特征对决策树学习的精度影响并不大。通常特征选择的标准是信息增益。
特征选择就是决定用哪个特征来划分特征空间。让我们看一组实例,贷款申请样本数据表。

希望通过所给的训练数据学习一个贷款申请的决策树,用于对未来的贷款申请进行分类,即当新的客户提出贷款申请时,根据申请人的特征利用决策树决定是否批准贷款申请。
特征选择就是决定用哪个特征来划分特征空间。比如,我们通过上述数据表得到两个可能的决策树,分别由两个不同特征的根结点构成。

图(a)所示的根结点的特征是年龄,有3个取值,对应于不同的取值有不同的子结点。图(b)所示的根节点的特征是工作,有2个取值,对应于不同的取值有不同的子结点。两个决策树都可以从此延续下去。问题是:究竟选择哪个特征更好些?这就要求确定选择特征的准则。如果一个特征将训练集分割成子集,使得各个子集在当前条件下有最好的分类,那么久更应该选择该特征作为划分条件。信息增益可以很好的帮我们数值化特征的分类效果,我们每次计算每个特征的信息增益,选取信息增益最高的特征就是最好的选择。
在计算信息増益前我们需要先了解信息的度量方式------香农熵(或简称熵)
1. 香农熵
熵(entropy)定义为信息的期望值。它表示随机变量不确定性的度量。符号xi的信息定义为:
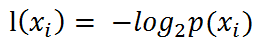
其中p(xi)是选择该分类的概率。该式是公理定义(等同于1+1=2的原始法则)。
为了计算熵,我们需要计算所有类别中所有可能值的数学期望,通过下面公式得到:

其中n是分类的数目。熵越大,随机变量的不确定性就越大。
当熵中的概率p(xi)由参数估计(矩估计、最大似然估计等)得到时,所对应的熵称为经验熵(empirical entropy)。对于该例来说,概率是我们根据数据计算得出的(因为样本可数)。我们定义贷款申请样本数据表中的数据为训练数据集D,则训练数据集D的经验熵为H(D),|D|表示其样本个数。
设有K个类Ck= 1,2,3,…,K,|Ck|为属于类Ck的样本个数,因此经验熵公式可以写为 :
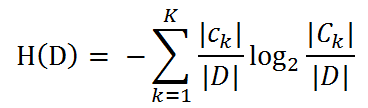
根据此公式计算经验熵H(D),分析贷款申请样本数据表中的数据。最终分类结果只有两类,即放贷和不放贷。根据表中的数据统计可知,在15个数据中,9个数据的结果为放贷,6个数据的结果为不放贷。所以数据集D的经验熵H(D)为:
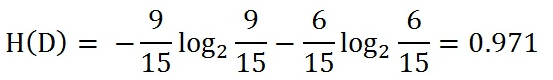
2. 代码实现经验熵
在编写代码之前,先对特征进行数字化
- 年龄:0代表青年,1代表中年,2代表老年;
- 有工作:0代表否,1代表是;
- 有自己的房子:0代表否,1代表是;
- 信贷情况:0代表一般,1代表好,2代表非常好;
- 类别(是否给贷款):no代表否,yes代表是。
确定这些之后,我们就可以创建数据集,并计算经验熵了,代码如下:
def createDataSet():
"""
创建测试数据集
:return:
"""
dataSet = [[0, 0, 0, 0, 'no'], # 数据集
[0, 0, 0, 1, 'no'],
[0, 1, 0, 1, 'yes'],
[0, 1, 1, 0, 'yes'],
[0, 0, 0, 0, 'no'],
[1, 0, 0, 0, 'no'],
[1, 0, 0, 1, 'no'],
[1, 1, 1, 1, 'yes'],
[1, 0, 1, 2, 'yes'],
[1, 0, 1, 2, 'yes'],
[2, 0, 1, 2, 'yes'],
[2, 0, 1, 1, 'yes'],
[2, 1, 0, 1, 'yes'],
[2, 1, 0, 2, 'yes'],
[2, 0,  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3341
3341











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









