






本文创新点:
(1)基于resnet101改进了backbone

bottleneck指的是残差块
(2)介绍了三种attention模块

基于通道模块、空间模块 和自注意力模块 下图为CASM SASM SSM


第二部分回顾了前科研者的工作
A.backbone with dilated strategy
如 PSPNet、HDC、PSPNet、DPC
B.encoder-decoder architecture、SegNet [24], U-Net [25], RefineNet [27], and ParseNet
state-of-the-art works, such as GCN [37], DFN [15], and PAN ENet [26] and ERFNet [29]
C.Context Embedding
ContextNet 意思差不多是将deep branch融入low resolution 和shallow branch 融入high resolution
GCN DFN
D. ATTENTION MECHANISM
文献 8 9 12-18 20
后边补充阐释了 新backbone的原因 使用分类的预训练模型虽然包含了大量的语义信息 但是缺乏丰富的空间信息 语义信息能够很好地帮助分类 但是分割的任务需要清晰边界 因此提出两个启发性方面:主框架需要拥有丰富的语义信息和空间信息 以及该框架能完成端对端的训练并且减少计算量。
该框架设想是基于空洞卷积出发的 空洞卷积能结合到多层的文本信息并没有增大计算量 然后不同的空洞卷积策略可以产生跟多的空间信息 并且能提高分辨率和增大接收域
基本框架手绘了一下

具体的衔接作者没有给出
然后是attention部分
首先往往接近输入的卷积层包含有更多的空间信息,更高层包含的是语义信息 也就是说低层高分辨率往往含有更丰富的空间信息而不是语义信息 受到论文1和8的启发 we argued that high-level features can highlight and select low-level features by embedding more semantic information into low-level features(我们认为高级特性可以通过嵌入突出和选择低级特性将更多的语义信息转化为低级特征??)
然后给出三种注意力机制的公式
1、CASM

2、SASM

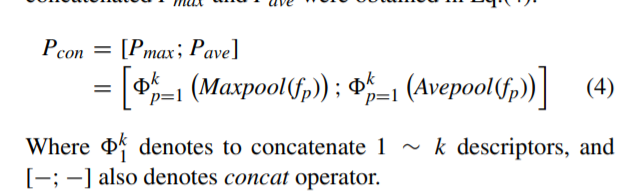
然后进行7*7卷积和激活函数 最后将权重赋值在原始像素上

3、SSM
fp是高特征特征图中的一个像素

Architecture
 实验
实验
数据集

训练优化器采用SGD(LR=0.01,MOMENTUM=0.99,DECAY=0.0001) 学习率采用poly政策 loss函数还是采用交叉熵(一些论文为了解决样本不平衡以及训练阶段的硬目标等adopted Focal Loss [51], Center Loss [4], and Online Hard Example Mining (OHEM) [21] as the optimization target)
然后对不同层的输出进行精度测试

实验表明 resnet101第三层输出后 进行双线性上采样效果优于第4层输出 使用卷积策略效果最好
论文的主干全输出效果最好
然后是对注意力机制一些细节进行测试

SASM的精度最高,其中k的取值为3的时候miou精度最高

















 1436
1436











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









