







 本文提出了一种名为KGAT的模型,它利用图神经网络技术在推荐系统中显式地建模高阶关系,通过递归的嵌入传播机制和基于注意力的聚合,解决传统推荐系统在捕捉复杂用户偏好和解释推荐结果方面的问题。
本文提出了一种名为KGAT的模型,它利用图神经网络技术在推荐系统中显式地建模高阶关系,通过递归的嵌入传播机制和基于注意力的聚合,解决传统推荐系统在捕捉复杂用户偏好和解释推荐结果方面的问题。
阅读日期:2020.5.14
论文地址:Paper in ACM DL
gitHub地址:KGAT
研究目的
本文主要利用 协同过滤 的思想,通过 图神经网络 的技术,研究了在推荐任务中引入 知识图谱 和用户行为数据,发掘高阶信息作为边信息,进而增强根据用户与物品的交互来预测用户偏好的问题,从而提供更加准确、更多样和更易于解释的推荐。
发现问题
目前,利用协同知识图谱(CKG, collaborative knowledge graph)进行推荐的工作可以分为两大类:
-
Path-based methods
在KG中提取携带高阶信息(high-order relation)的路径,并将其输入预测模型。为了解决两个节点间存在大量路径的问题,有两种方法:
①应用路径选择算法来选择突出的路径。
缺点:没有针对推荐问题进行路径选择算法的优化
②自定义元路径模式来约束路径
缺点:需领域知识来定义元路径,工作量很大 -
Regularization-based methods
设计附加的损失项来捕获KG结构,使推荐模型学习规范化。
缺点:由于这些方法是通过隐式编码的方式将高阶信息(high-order relations)引入推荐模型中,缺乏显式的建模。因此既不能保证捕获远距离连通性(long-range connectivity),也不能解释高阶建模(high-order modeling)的结果。
针对目前存在的问题,该研究提出了KGAT模型。其主要有两个特点:
①递归的Embedding传播机制
通过邻居节点来更新当前节点的表示,并且该算法能够在线性的时间复杂度上进行递归来捕获高阶连接性(high-order connectivities)。
②基于注意的聚合
利用注意力机制来学习传播过程中每个邻居的权重,使得这种权重可以揭示不同高阶连通的重要程度。
优越性:
避免了Path-based中提取路径工作量大的问题
避免了高阶相关性无法捕获的问题:显式地将高阶关系纳入预测模型,对所有相关参数进行定制以优化推荐目标。
重要术语定义
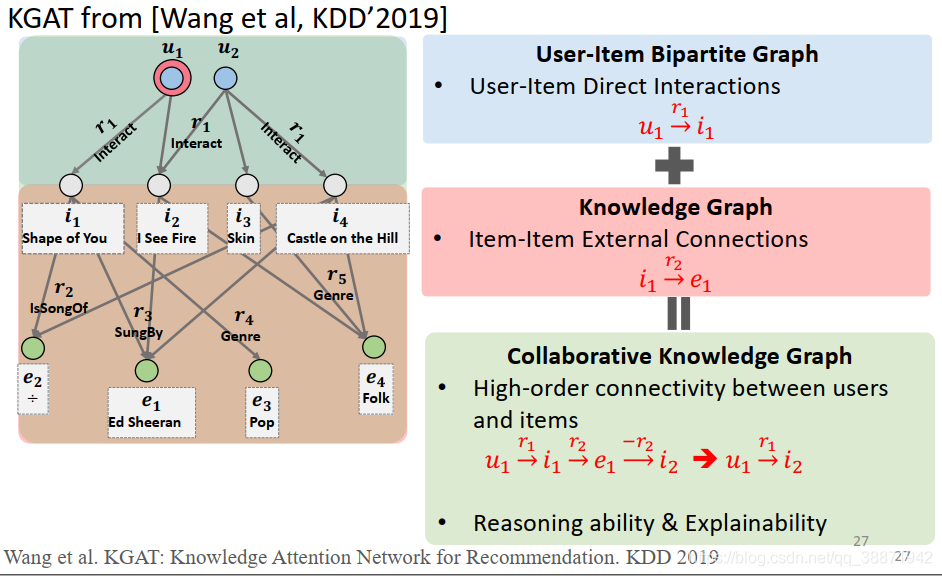
1.Collaborative Knowledge Graph
CKG可以视为知识图谱(物品间的连接)和用户-物品二部图(主要是用户和物品的交互)的统一。这里选用该论文作者在“推荐系统前沿进展”学术会议中的PPT进行图示:
2.High-Order Connectivity
high-order relations通过一个或多个属性来连接两个item(用户或物品)。利用high-order relation,对于执行高质量推荐非常重要。
将节点之间的 L阶连接 定义为一个多跳关系路径:
e
0
→
r
1
e
1
→
r
2
…
→
r
L
e
L
e_0\xrightarrow{r_1}e_1\xrightarrow{r_2}…\xrightarrow{r_L}e_L
e0r1e1r2…rLeL
现有的CF和监督学习方法不能挖掘出这种高阶连接。
如下图所示,当用户
u
1
u_1
u1和电影
i
1
i_1
i1之间有交互时,协同过滤的方法关注也观看过该电影
i
1
i_1
i1的相似用户,即
u
4
u_4
u4和
u
5
u_5
u5;而监督学习方法(如FM、NFM等)则强调具有属性
e
1
e_1
e1的相似物品,即
i
2
i_2
i2。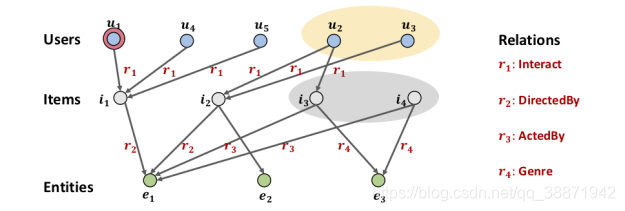
那么高阶连接是什么呢?如图中黄色圆圈内的用户,他们观看了同一个导演
e
1
e_1
e1指导的电影
i
2
i_2
i2;或灰色圆圈内的物品,与
e
1
e_1
e1有其他相关关系。那么高阶链接就是这种长距离的连接:
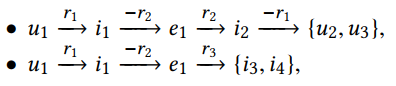
研究方法
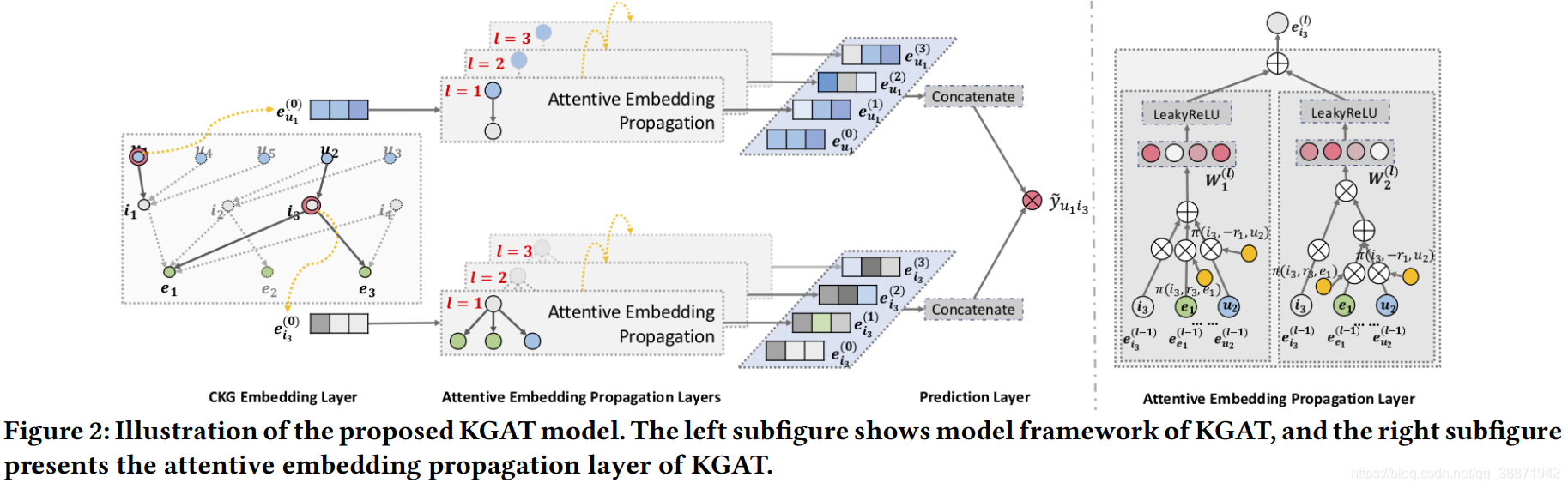
KGAT模型如下图所示,主要包含三个部分:
1、Embedding Layer:通过保留CKG的结构将每个节点参数化为一个向量
2、Attentive Embedding Propagation Layer:递归地传播节点邻居的Embedding信息以更新其表示,并利用知识感知的注意力机制在传播过程中学习每个邻居的权值
3、Prediction Layer:集成来自所有传播层的用户和物品的表示,并输出相应的预测评分
1. Embedding Layer
知识图谱的嵌入,是参数化实体和关系作为向量表示的一种有效方法,同时能够保留图的结构信息。
常用的知识表示方法可以分为两类: 基于结构的方法和 基于语义的方法。基于结构的嵌入表示方法包括TransE, TransH, TransR&CTransR, TransD等,这类方法从三元组的结构出发学习KG的实体和联系的表示;基于语义的嵌入表示方法包括NTN、 SSP和 DKRL等,这类方法从文本语义的角度出发学习KG的实体和联系的表示。
关于Trans系列的方法可参考:《基于结构的知识表示学习》
作者:孙天祥
来源:知乎
KGAT采用了TransR方法,对于三元组
(
h
,
r
,
t
)
(h,r, t)
(h,r,t)的似然得分如下:
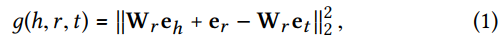
通过有效三元组和无效三元组进行区分的思想,训练成对损失函数如下。该层相当于知识表示的regularizar,提升了模型的表示能力。(实验4.4.3部分将进行验证)
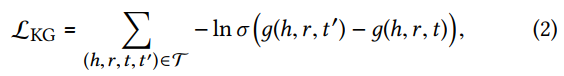
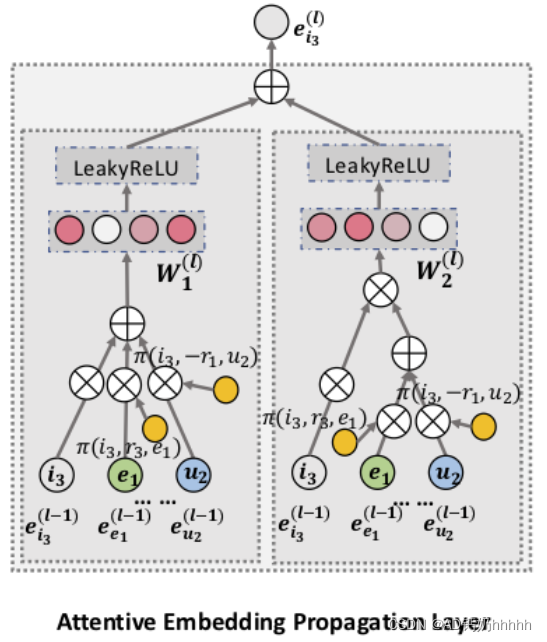
2. Attentive Embedding Propagation Layers —— 重点部分
这个部分首先在单层上(如模型图中Attentive Embedding Propagation Layer部分是通过三个叠加layer组成,这里为了便于理解先从单层的角度出发)介绍其三个组成部分,再将其推广到多层上。
<1> Information Propagation
对于实体
h
h
h(head entity),通过
N
h
=
{
(
h
,
r
,
t
)
∣
(
h
,
r
,
t
)
∈
G
}
N_h = \{(h,r, t)|(h,r, t) ∈ G\}
Nh={(h,r,t)∣(h,r,t)∈G}表示三元组集合,称为ego-network。通过如下公式,这种线性组合的思想刻画了实体
h
h
h的一阶连接结构。
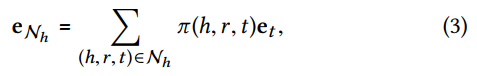
其中
π
(
h
,
r
,
t
)
π(h, r, t)
π(h,r,t)控制在关系(h, r, t)中实体间传播的衰减系数,其作用是:显示出通过关系
r
r
r有多少信息能够从
t
t
t传播到
h
h
h。
<2> Knowledge-aware Attention
通过注意力机制对
π
(
h
,
r
,
t
)
π(h, r, t)
π(h,r,t)公式化如下。在relation上距离更近的实体间会传递更多的信息。
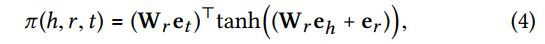
通过softmax函数对所有与
h
h
h相连的三元组的系数进行归一化:
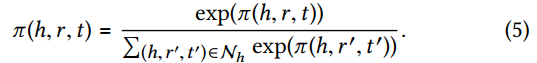
softmax函数的理解
函数的主要作用是将多分类的结果以概率的形式(非负数;大小在0~1之间,且各概率之和为1)展现。此处通过softmax函数对 π ( h , r , t ) π(h, r, t) π(h,r,t)进行处理,目的是定量显示出应该给予哪个邻居更多的注意力。
<3> Information Aggregation
该模块的作用:将前两层的结果(实体表示
e
h
e_h
eh 和 ego-network表示
e
N
h
e_{N_h}
eNh)进行集成,作为实体
h
h
h新的表示形式:
e
h
(
1
)
=
f
(
e
h
,
e
N
h
)
e_h^{(1)} =f(e_h, e_{N_h})
eh(1)=f(eh,eNh)
其中
f
(
⋅
)
f(·)
f(⋅)有三种不同的集成方式
- GCN Aggregator:
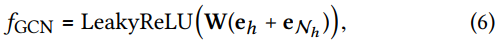
- GraphSage Aggregator:
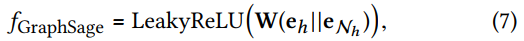
- Bi-Interaction Aggregator:(实验部分证明了该形式效果更好,由于其加入了feature-interaction,对实体间关系的敏感性更强)
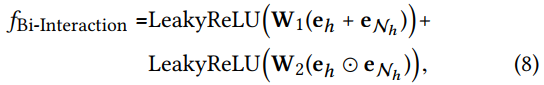
对应的示意图:左半部分代表 L e a k y R e L U ( W 1 ( e h + e N h ) ) LeakyReLU(W_1(e_h + e_{N_h})) LeakyReLU(W1(eh+eNh)),右半部分代表 L e a k y R e L U ( W 1 ( e h ⊙ e N h ) ) LeakyReLU(W_1(e_h⊙e_{N_h})) LeakyReLU(W1(eh⊙eNh))
多层传播
通过多层传播可以捕获更多信息(多跳邻居所传播的)。在步骤
l
l
l 处,递归地将一个实体表示如下:
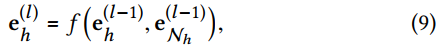
f
f
f计算的
e
h
(
l
−
1
)
e_h^{(l-1)}
eh(l−1)是实体
h
h
h在
l
−
1
l-1
l−1层中的表示:通过上一步的信息传播,在
l
−
1
l-1
l−1层中获取到的邻居信息得到的实体表示。
而
e
N
h
(
l
−
1
)
e_{N_h}^{(l-1)}
eNh(l−1)表示:对于实体
h
h
h,在
l
l
l层的ego-network上传播的信息:
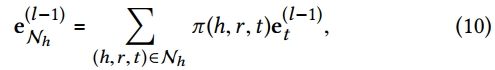
3. Model Prediction
预测评分:

其中,用户和物品表示是通过layer-aggregation机制,将不同层的输出所强调的连接信息进行集成:

4. Optimization
通过BPR损失函数对推荐模型进行优化。优化的intuition是:观察到的交互表示出用户的偏好,那么相应就应该有更高的预测评分。
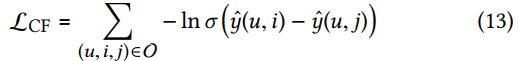
将该损失项与公式(2)结合,定义最终的目标优化函数:

总结与展望
本文主要贡献
- 强调了在协同知识图谱(CKG)中显式建模高阶关系(high-order relation)的重要性,以通过项目的边信息来提供更好的推荐
- 提出KGAT方法,在图神经网络框架下,以显式地、端到端的方式实现了high-order relation的建模
- 在三个公开的benchmark上对该方法进行了大量实验,证明了KGAT的有效性及其在理解高阶关系的重要性方面的可解释性。
展望
本文探讨了图神经网络在推荐中领域的潜力,并代表了利用信息传播机制挖掘结构化知识的初步尝试。其他的结构化知识可以考虑:社交网络、物品上下文等。而信息传播机制和决策过程的集成,有助于推进可解释推荐研究的进展。

















 1103
1103

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









