






目录
8.swin-transformer(iccv -2021-引用16631)
相关vit系列代码综合:
vit:transfomer应用到图像处理的开山之作
Deit :蒸馏模型的应用,使transformer可以在一个gpu上跑出来
Levit :前两个模型的结合,deit是纯transformer结构,levit是cnn+transformer结合,利用多种手段加快运行速度
Localvit:改进transformer中的前馈神经网络,加入深度卷积模块使其具有cnn的局部注意力属性
Cait :通过对残差块和特别设计的类别注意力层,实现更深层次的网络结构
Pvt :设计的纯transformer金字塔结构既保证全局特征获取也使计算量减少,可作为主干框架使用。
T2T-vit :
swin-transfomer:pvt的进阶版,不仅仅是金字塔结构,还设计的局部注意力模块使计算量进一步减少。
1.vit(arvix-2020-引用34204)
AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
推出背景
transformer在NLP自然语言上大获成功,但是对于图像处理这块还没合适的应用
模型结构


Layers就是Transformer Encoder中重复堆叠Encoder Block的次数 L。
Hidden Size就是对应通过Embedding层(Patch Embedding + Class Embedding + Position Embedding)后每个token的dim(序列向量的长度)
MLP Size是Transformer Encoder中MLP Block第一个全连接的节点个数(是token长度的4倍)
Heads代表Transformer中Multi-Head Attention的heads数
实验结果
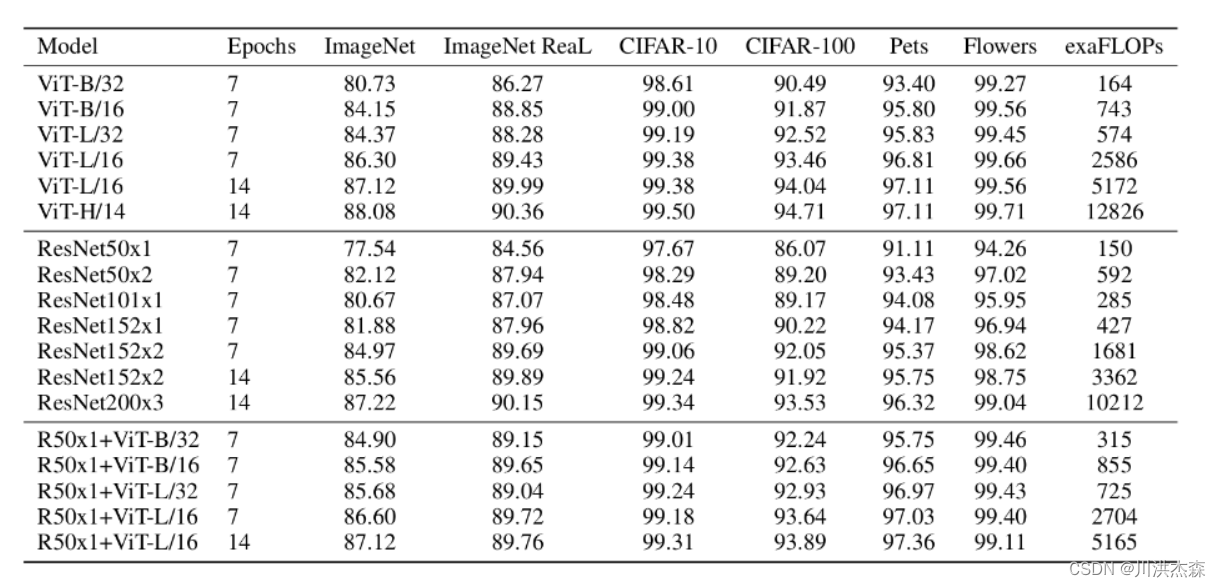
上表是论文用来对比ViT,Resnet(和刚刚讲的一样,使用的卷积层和Norm层都进行了修改)以及Hybrid模型的效果。通过对比可得出结论:
在训练epoch较少时Hybrid优于ViT -> Epoch小选Hybrid
当epoch增大后ViT优于Hybrid -> Epoch大选Vit
2.Deit(ICML-2021-引用5540)
Training data-efficient image transformers & distillation through attention
推出背景
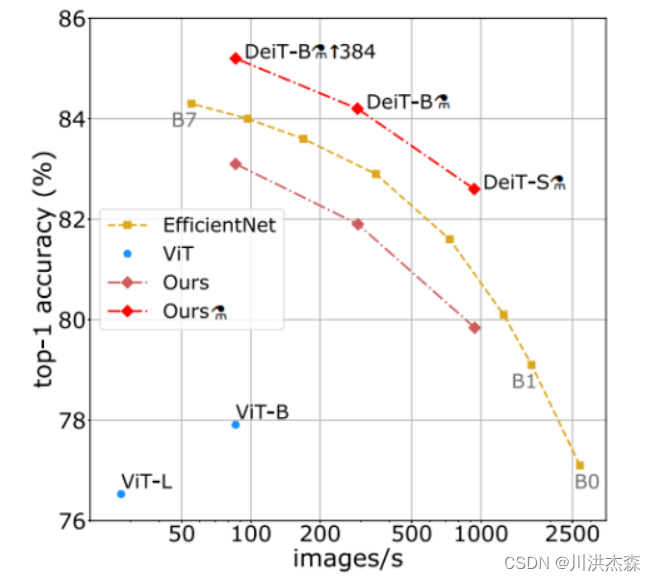
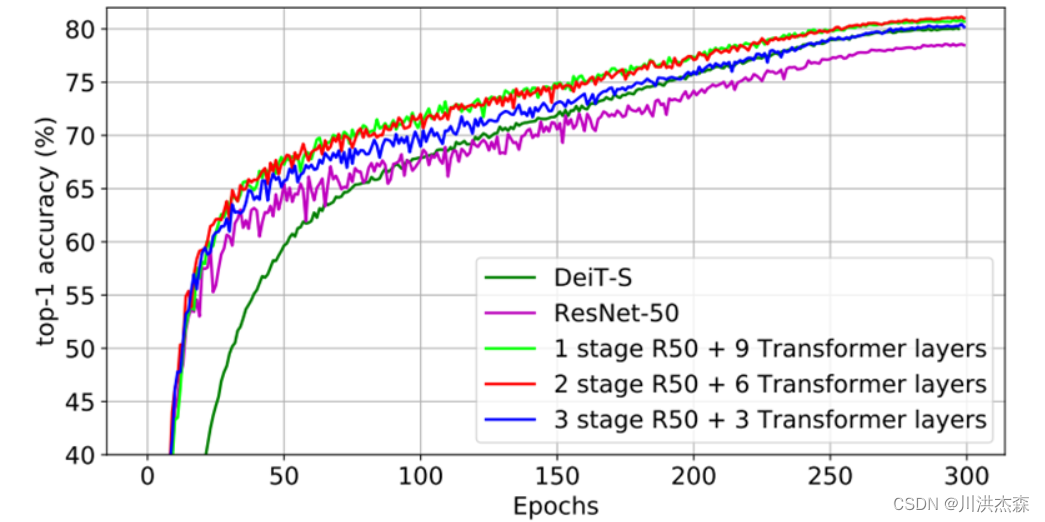
对于普通开发者,要想利用ViT获得理想的泛化能力,需要庞大的计算资源和数以亿计的图像进行预训练,成本昂贵,而Facebook的DeiT模型(8600万参数)仅用3天时间在一台 8-GPU 的服务器上进行训练,即可在ImageNet数据集上取得比ViT性能更为优秀的效果。在此基础上,加入蒸馏(Distillation)操作,能使性能进一步提升。如下图所示,横轴代表ImageNet数据集上的吞吐量(即throughout, 一秒内可以处理的最大输入实例数),⚗表示加上了特定蒸馏操作的DeiT模型。
结构模型
1)带温度的softmax函数 通过这个带温度参数的softmax函数,类别间概率分布中存在的相似性信息通过升温被放大,这样才能对损失函数产生更大的影响。也即汽车被误认为垃圾车的概率在升温之后其相对值会变大。
通过这个带温度参数的softmax函数,类别间概率分布中存在的相似性信息通过升温被放大,这样才能对损失函数产生更大的影响。也即汽车被误认为垃圾车的概率在升温之后其相对值会变大。
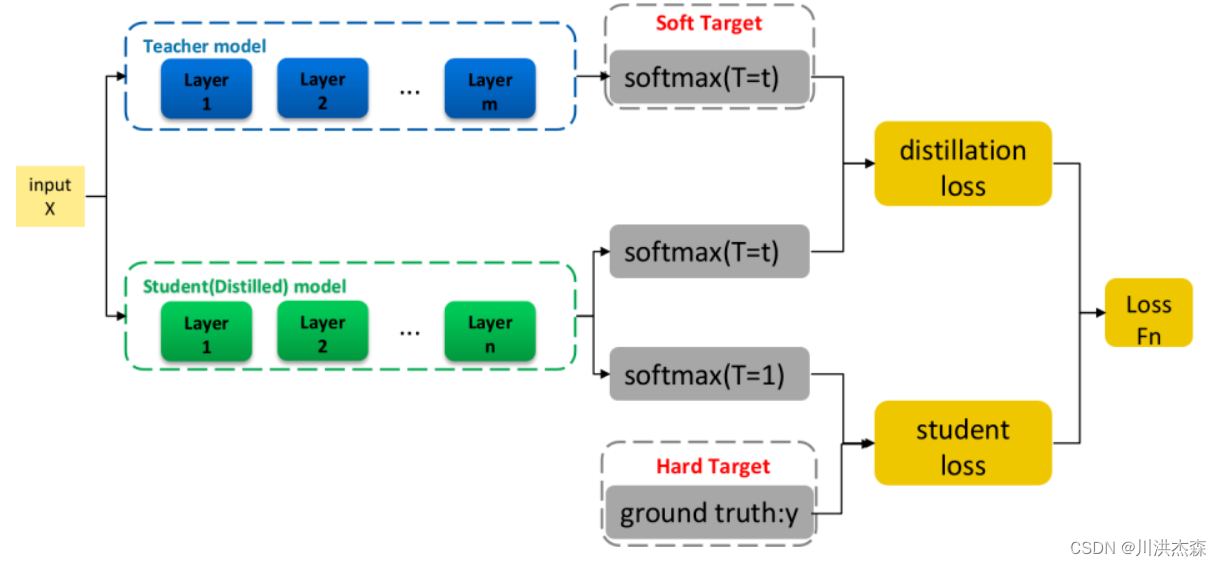
2)损失函数 最终损失函数是软目标函数和硬目标函数的结合: 知识蒸馏的过程,简单而言,第一,利用大规模数据训练一个教师网络;第二,利用数据和教师网络指导训练一个学生网络。算法的整体流程如图所示:
知识蒸馏的过程,简单而言,第一,利用大规模数据训练一个教师网络;第二,利用数据和教师网络指导训练一个学生网络。算法的整体流程如图所示:
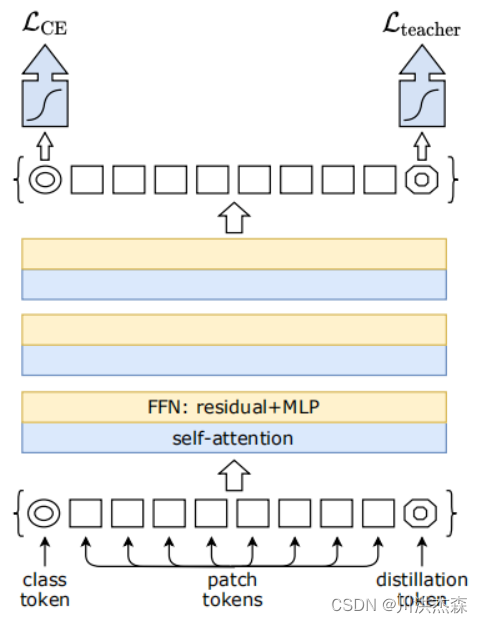
蒸馏分为两种,一种是软蒸馏(soft distillation),一种是硬蒸馏(hard-label distillation)。
软蒸馏 以交叉熵为分类损失,KL散度为蒸馏损失,用教师网络的softmax输出为标签,也即是常规蒸馏方式:
硬蒸馏 以交叉熵为蒸馏损失,以教师网络的硬输出为标签:
实验结果
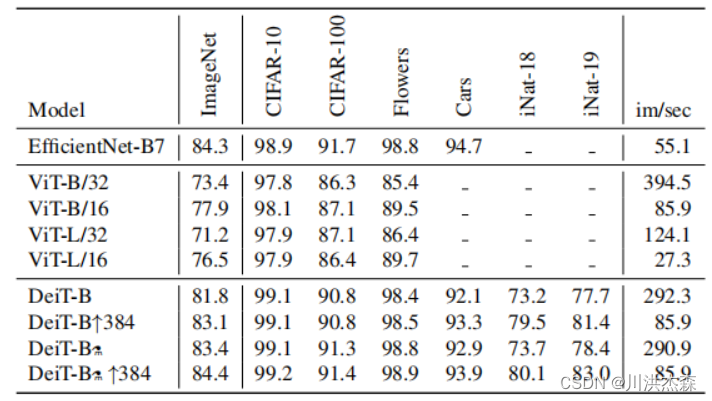
DeiT相比于ViT,在结构上添加了蒸馏token。为了便于比较,构建了与ViT类似的三种不同规模的对照组DeiT,其详细参数如下表所示:
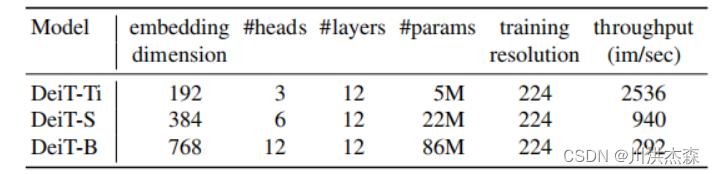
利用CNN做教师网络 蒸馏出的学生模型在准确率和吞吐量之间的权衡胜过其教师网络,有趣的是,卷积网络作为教师网络的结果要比用Transformer作为教师网络的结果更佳。
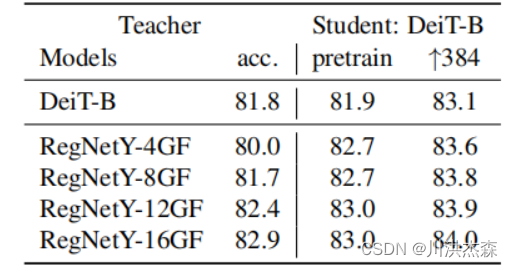
不同蒸馏策略的比较 从实验结果得出,硬蒸馏显著优于软蒸馏,且class+distillation联合token的效果优于单一token
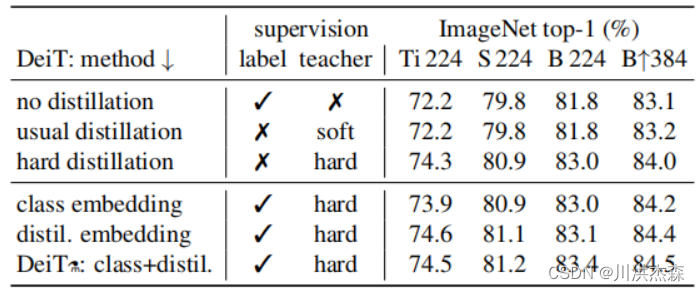
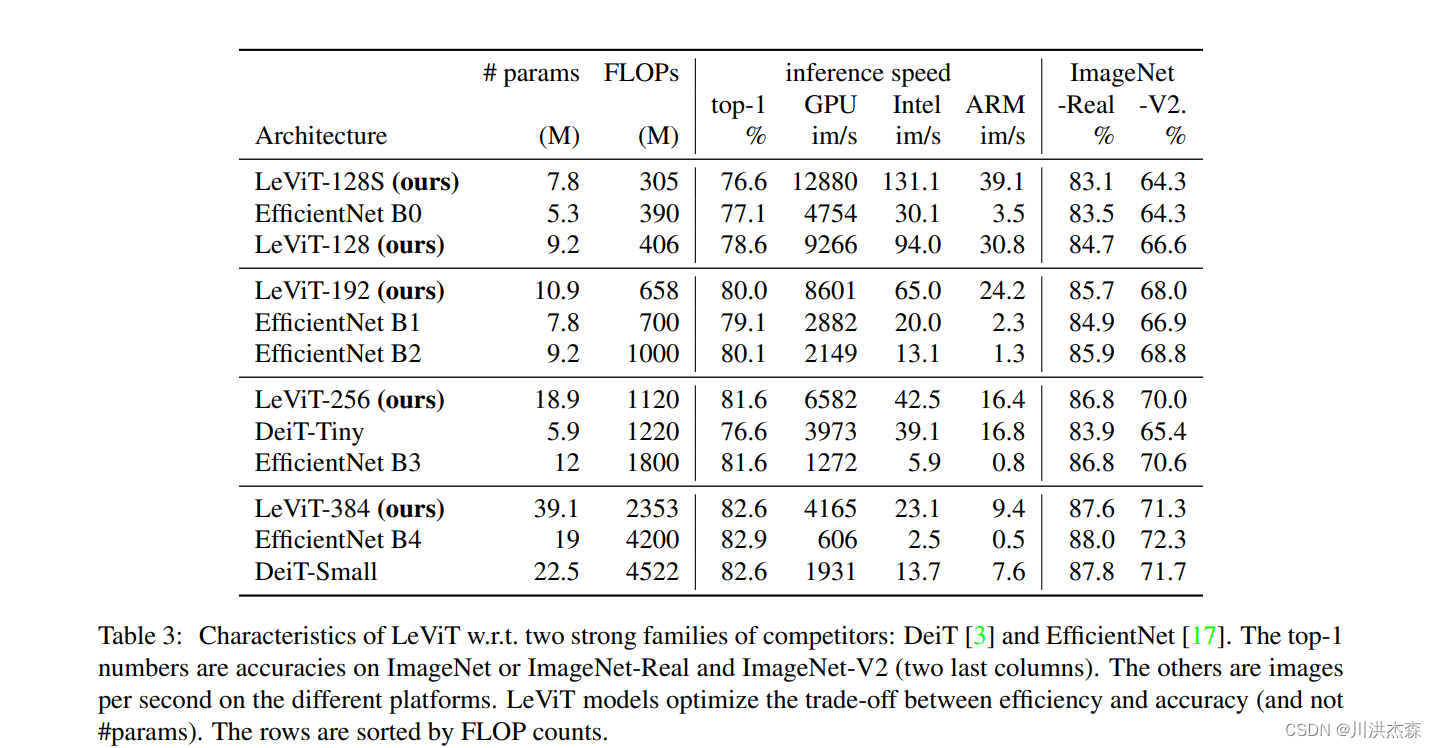
下游任务的迁移 已知DeiT在ImageNet上表现良好,为了衡量它的泛化能力,在不同数据集上进行迁移学习。下表将DeiT迁移学习结果与ViT和EfficientNet进行了比较,DeiT与CNN模型的表现相当
3.Levit(ICCV-2021-引用467)
LeViT: a Vision Transformer in ConvNet’s Clothing for Faster Inference
参考链接:轻量级Visual Transformer模型——LeViT(ICCV2021)-CSDN博客
推出背景
大多数硬件加速器(gpu,TPUs)被优化以用来执行大型矩阵乘法。在Transformer中,注意力机制和MLP块主要依靠这些操作。相比之下,卷积需要复杂的数据访问模式,因此它们的操作通常受io约束。这些考虑对于我们探索速度/精度的权衡是很重要的
作者提出这种用于快速推理的混合神经网络。考虑在不同的硬件平台上采用不同的效率衡量标准,以最好地反映各种应用场景。作者通过广泛的实验表明该方法适用于大多数体系结构。总体而言,在速度/准确性的权衡方面,LeViT明显优于现有的卷积网络和视觉Transformer。例如,在ImageNet Top-1精度为80%的情况下,LeViT比CPU上的EfficientNet快3.3倍。
模型结构
LeViT的结构如上图所示,很像一个火箭形状。这也是LeViT的特点之一:快速缩小特征图。这里的关键点在“特征图”,对,LeViT的思想里淡化了transformer中“token”的概念,引入了CNN中activation map(特征图)的概念。所以,大致按对待CNN的思路来对待LeViT会更有助于理解这个模型,比如最后加的那个average pooling。
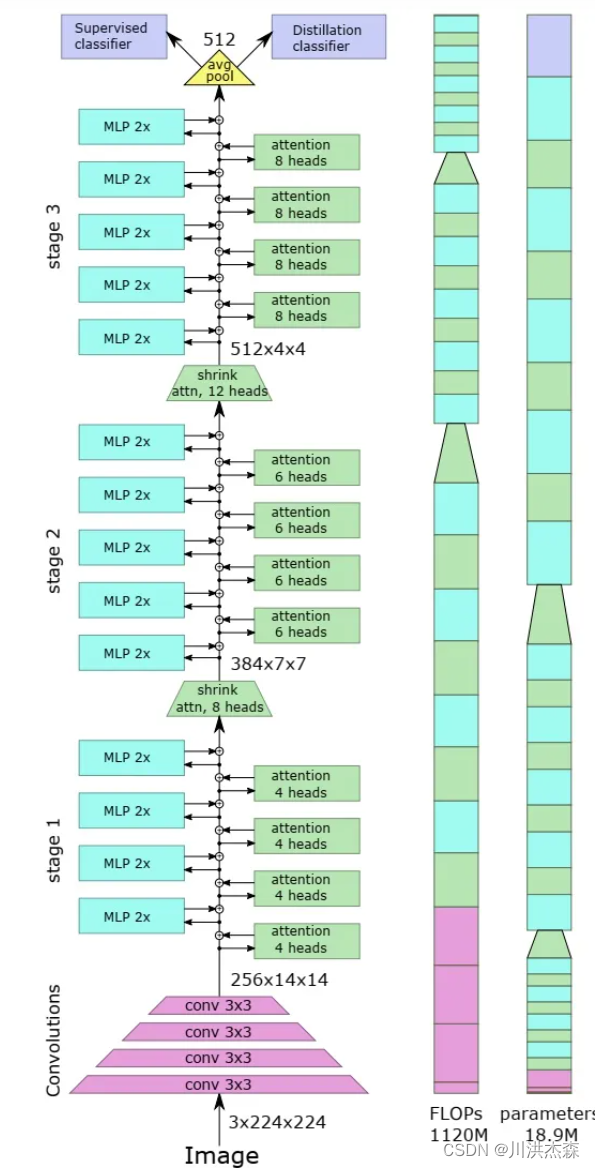

快速的原因:
1. 用CNN代替“划片”
这里用到了4层卷积层,每层的步长都是2,这样不需要使用pooling也能完成特征图下缩。在这一步,下缩幅度非常sharp,用4层就缩小了16倍的边长。而ResNet-18缩小到这个尺寸用了10层。如此sharp的尺寸下缩,使得送到self-attention模块的size就非常小了,有助于加速模型。
3x224x224 -> 256x14x14
输出为256x14x14的特征图,咱们用attention的角度理解:256个通道,每个通道14x14个token。咱们要知道self-attention的计算次数跟token数呈二次线性相关(知识点),所以token数太大对自注意力计算非常unfriendly。所以,轻量级ViT的思路肯定是尽量减小输入到self-attention模块之前的token数的。
用Conv layers代替无交集划片有几个优势:1. 可以进行初步的特征提取;2. 保留相对位置信息,可以不用在这个部分进行位置编码。
2. 用BN代替LN
transformer里最流行的norm方法就是LN,在很多论文的实验中都表明用LN比BN可以带来更多的准确率提升。而LeViT作者认为,LN比BN在准确率提升的作用上很有限,但LN比BN在计算上慢一些。
文章里对BN为何更快的解释如下:在inference的时候,BN计算可以融合到卷积里,几乎不会额外带来计算负担。
3. 多分辨率金字塔
这个trick就描述了LeViT整个火箭型的结构,每过一个block,activation maps的尺寸都会减小,从开始的14x14到后面的4x4。
4.具有收缩特征图尺寸作用的self-attention模块
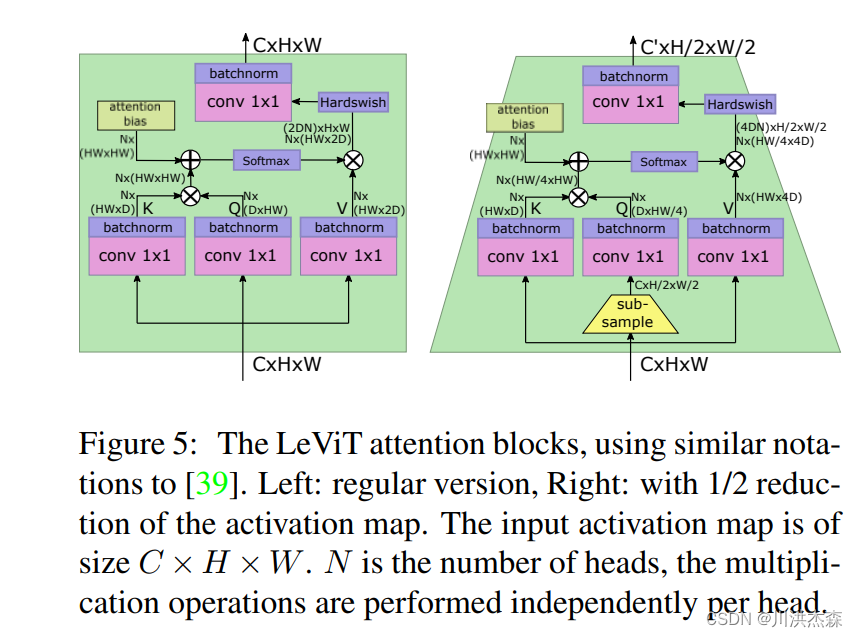
如Figure 5所示,咱们只需要关注输入输出的size,左边是正常的自注意力模块,右边是带特征图下缩的自注意力模块。通过在Q的计算里引入下采样来实现。
5. 采用维度更小的key
在原始ViT里面,K、Q、V都有一样的维度。实际上V可以保持大一点的维度,我们可以认为V承载了token的主要信息。而key可以看做是更高层的抽象,所以采用更小的key维度也并不影响模型效果。另外,我们看self-attention计算公式,会发现K × Q K \times QK×Q才是self-attention计算的大头,如果shrink一下key的维度,那自注意力模块的计算效率将会大大提升
6. 采用注入attention的可学习位置编码
这就是LeViT一个很优秀的创新了。传统的ViT位置编码只在划片时候,以人工定义的位置矩阵来进行位置编码。但是LeViT作者认为,token的相对位置不仅在最开始很重要,在每一层attention模块都很重要。所以,采用一种注入self-attention计算的位置编码,咱们看图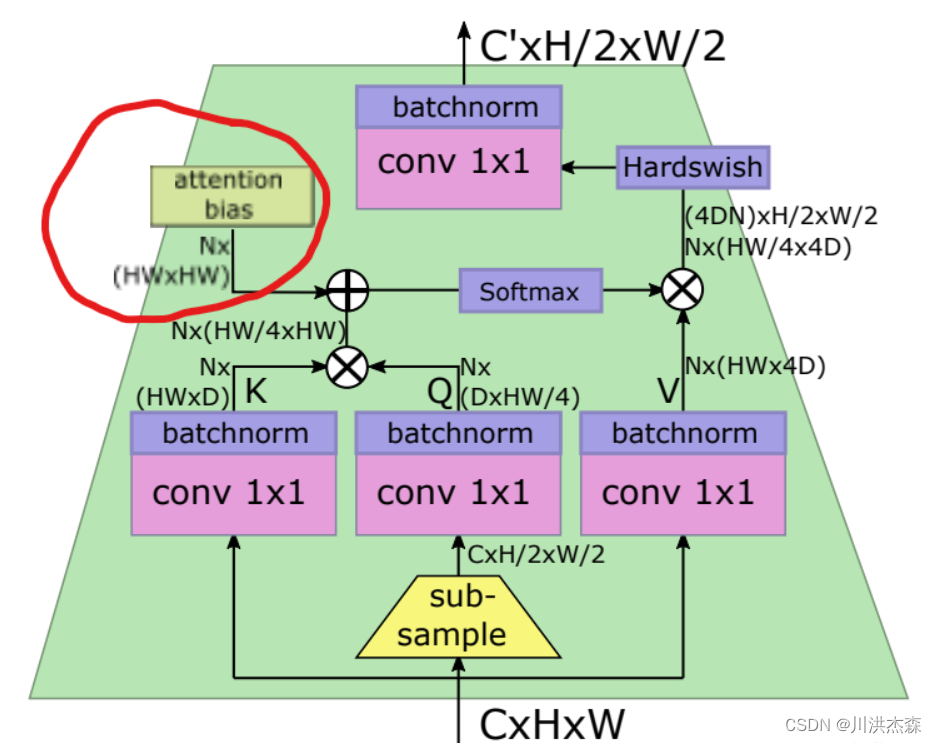
就是这个位置,用Attention Bias来代替Position Embedding(划重点)。
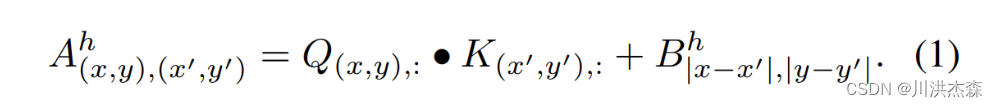
就是在QK乘法之后加上一个bias常数,这个bias是对称的、可学习的。
7. 蒸馏学习
蒸馏学习是指采用一个teacher模型来训练student模型。最开始将distillation思想用到ViT的模型是DeiT,而LeViT就是DeiT的改进版。
transformer引入CV领域之后有个很大的缺点迟迟没有被解决,那就是transformer不够Data Efficient。相比CNN,ViT对训练数据更加依赖,要达到CNN的SOTA,ViT需要用更多的数据以及需要更多的训练周期。
卷积的优势是自带对neighbors的归纳偏执,所以收敛更快,但缺乏global性;
self-attention的优势是global性,但本身处理单元时,在初始状态下会对所有token“一视同仁”。如上图所示,self-attention比Conv天生有更大的解空间。
于是,引入蒸馏训练就很有必要了。
蒸馏训练是找个well-trained的CNN当做teacher model,然后用LeViT一方面跟Ground Truth做CE loss,一方面跟CNN的输出distribution做一个CE loss。这样可以用CNN来引导LeViT来加快收敛,这样就可以做到data-efficient了。
实验结果
在ImageNet Top-1精度为80%的情况下,LeViT比CPU上的EfficientNet快3.3倍。
4.Localvit(arvix-2021-引用464)
LocalViT: Bringing Locality to Vision Transformer
推出背景
transfomer更加注重全局特征,通过在前馈网络中引入深度卷积来为视觉Transformer添加局部性。这个看似简单的解决方案来自于前馈网络和反向残差块之间的比较。局部性机制的重要性通过两种方式得到验证:
1)广泛的设计选择(激活函数、层布局、扩展比率)可用于合并局部性机制,并且所有正确的选择都可以导致性能超过基线;
2)相同的局部性机制成功应用于4个视觉Transformer,这显示了局部性概念的泛化。
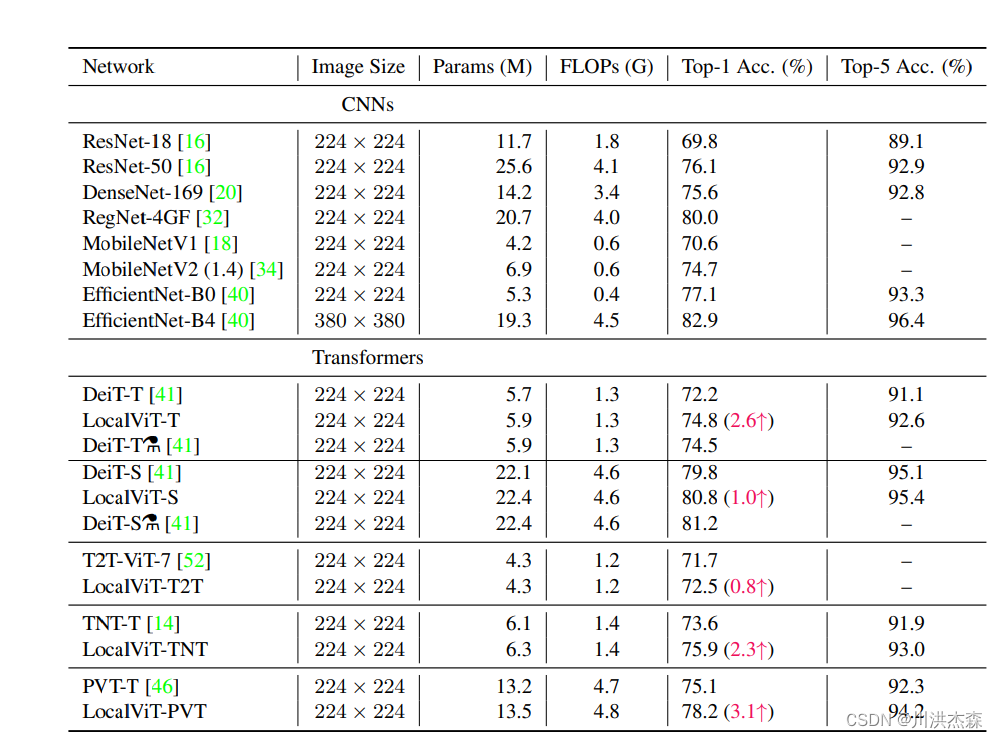
特别是,对于ImageNet2012分类,局部增强型Transformer的性能优于基线DeiT-T和PVT-T2.6%和3.1%,而参数数量和计算量的增加可以忽略不计。
模型结构
(1)通过引入深度卷积为视觉Transformer带来了局部性机制。新的 Transformer 架构结合了用于全局关系建模的自注意力机制和用于本地信息聚合的局部性机制。
(2)我们分析了引入的局部性机制的基本属性。每个组件(深度卷积、非线性激活函数、层放置和隐藏维度扩展比率)的影响都被单独列出。
(3)我们将这些想法应用于视觉Transformer,包括 DeiT、T2T-ViT、PVT 和 TNT。实验表明,本文提出的简单技术可以很好地推广到各种Transformer架构。
transformer结构
里面的前馈神经网络
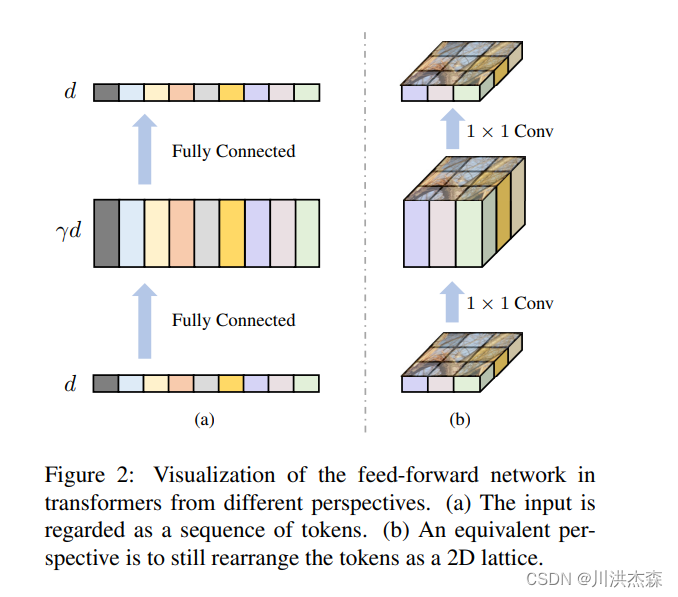
transformer 的前馈网络由两个完全连接的层组成,它们之间的隐藏维度被扩展(通常为 4 倍)以提取更丰富的特征。类似地,在反向残差块中,两个1×1卷积之间的隐藏通道也被扩展。它们之间的主要区别在于反转残差块中的高效深度卷积。这种深度卷积可以精确地提供局部信息聚合的机制,而这在视觉变换器的前馈网络中是缺失的。此外,深度卷积在参数和计算复杂度方面都很高效。
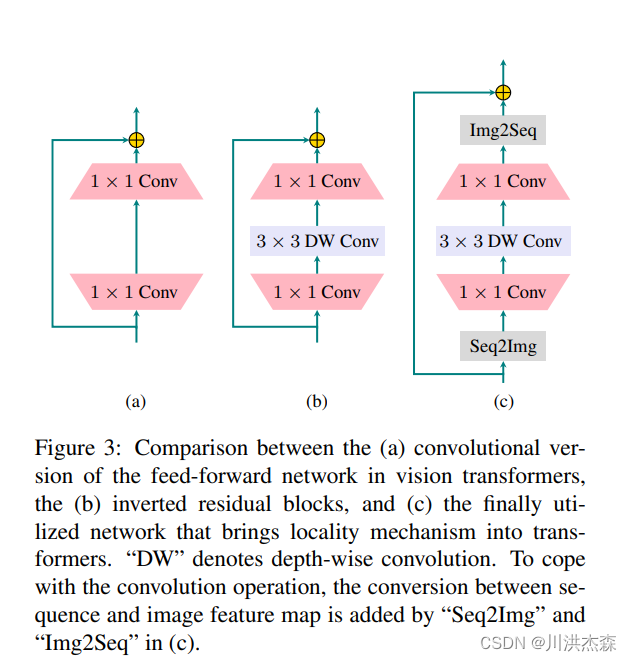
进行改进:(dw为深度卷积模块)
实验结果
5.Cait(ICCV-2021-引用896)
Going deeper with Image Transformers
推出背景
vit推出后有各种衍生版本,针对数据问题和计算开销后续论文给出了不少改进,这篇论文则是在思考如何加深网络。
根据以前的经验,增加模型的深度可以使得网络学习更复杂的表征,比如 ResNet 从18 层到 152 层,随着层数的增加其精度逐渐提高。
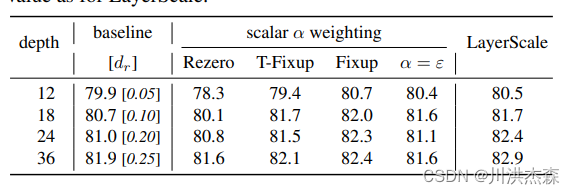
但是在 Transformer 中,当我们扩展架构时,模型变得越来越难训练,其中深度是不稳定的主要来源之一,例如 DeiT-S 在不调整超参数情况下不能正确收敛到 18 层以上,尽管结合一些调参技巧如线性调整 drop rate,DeiT-S 依然在36层达到饱和(实验均在 ImageNet 1K 下进行)
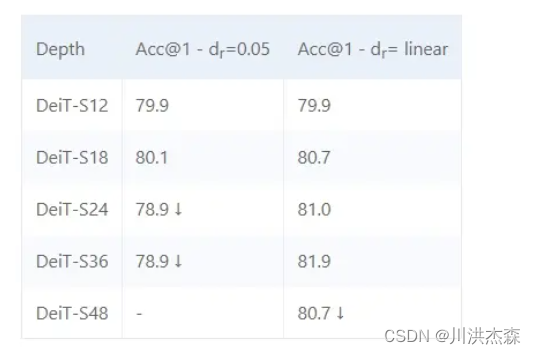
模型结构
为了解决深度问题,CaiT 提出了两个改进,一个是 LayerScale,一个是 Class-Attention
LayerScale 在每个残差块的输出上添加一个可学习的对角矩阵,该矩阵被初始化为接近0。在每个残差块之后添加这个简单的层可以提高训练的动态性,使我们能够训练更深层次的大容量 Transformer
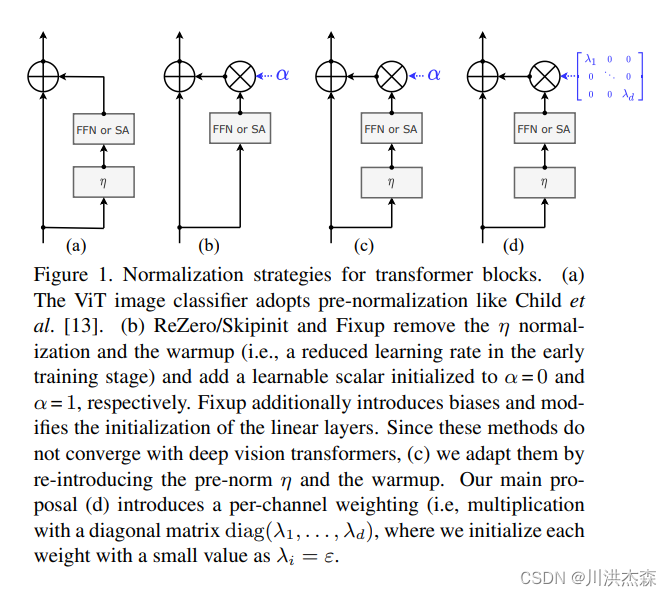
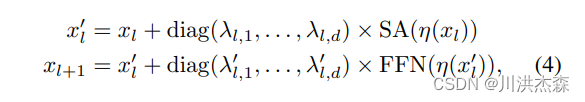
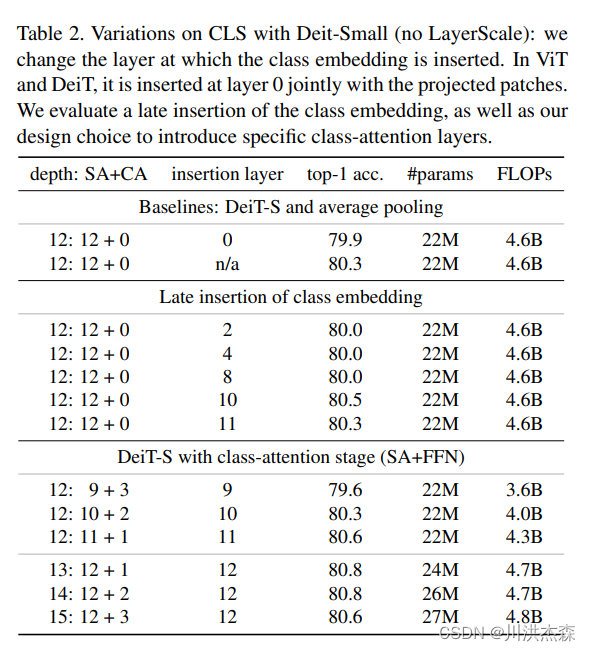
lass-Attention 是一个类似于 Encode/Decode 的结构,和 Self-Attention 不同,Class-Attention 更注重从处理过的 patches token 中提取信息,相比 SA 主要是 Q(query)的自变量 z 变成 xclass,而 K(keys)、V(value)则保持不变

左边是 ViT 网络结构,CLS(classes token)与 Patch Embedding 一起被送进网络,最后输出 CLS 做分类
右边则是 CaiT 网络结构,相对于左边的 ViT 结构而言,最直观的变化是 CLA 被放入网络更深的层。
作者认为是 clas token 在网络前期使用的任务的矛盾,一方面它要用于最后概括总信息的类别预测,一方面又要在每层辅助全图特征的更新,这两个任务加在一起会让 clas token 的优化变得迷茫,实验结果也很好证明了 CLS 放在后面有助于性能的提高。
实验结果
6.Pvt(ICCV-2021-引用3021)
Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions
推出背景
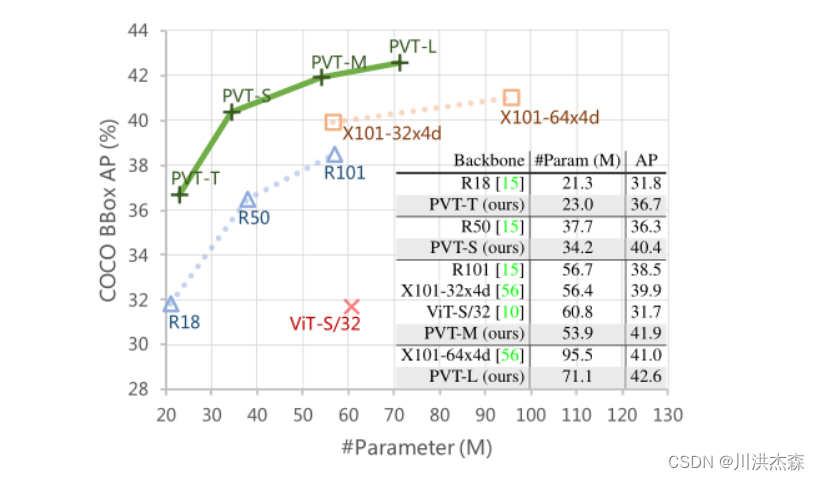
尽管基于CNNs的backbone在多种视觉任务中取得重大进展,但本文提出了一个用于密集预测任务的、无CNN的的简单backbone——Pyramid Vision Transformer(PVT)。相比于ViT专门用于图像分类的设计,PVT将金字塔结构引入到transformer,使得可以进行下游各种密集预测任务,如检测、分割等。与现有技术相比,PVT有如下优点:(1)相比于ViT的低分辨率输出、高计算复杂度、高内存占用,PVT不仅可以对图像进行密集划分训练以达到搞输出分辨率的效果(这对密集预测很重要),还可以使用一个逐渐缩小的金字塔来降低大feature maps的计算量;(2)PVT兼具了CNNs和Transformer的优点,使其成为一个通用的无卷积backbone,可以直接替换基于CNN的backbone;(3)大量实验表明,PVT可以提高多种下游任务的性能,如目标检测、语义/实例分割等。比如,参数量相当的情况下, RetinaNet+PVT可以在COCO上达到40.4AP,而RetinNet+ResNet50只有36.3AP。作者希望PVT能够成为像素级预测任务的一种可供选择的backbone,并促进后续的研究。
模型结构
受NLP领域的启发,一些研究尝试基于Transformer进行计算机视觉任务,如ViT、DETR、SETR、 Deformable detr、Transtrack等。
ViT是首次利用transformer替代CNNbackbone进行图像分类的工作,如图1(b)所示,其backbone为柱状结构,输入为一组粗糙的图像patchs。
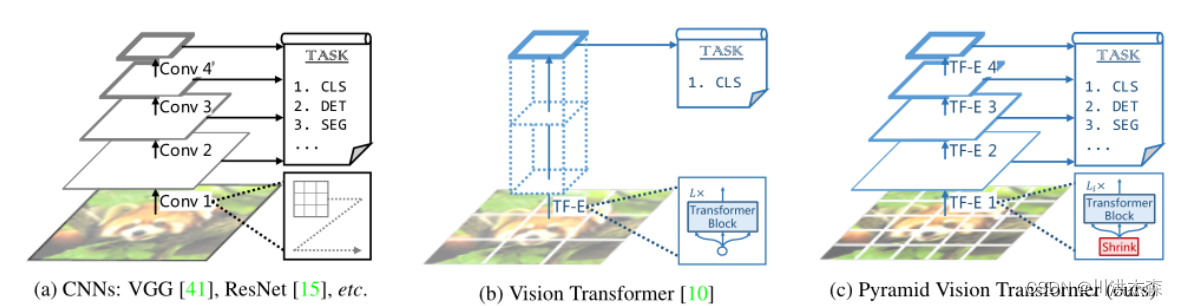
尽管ViT在图像分类上得以应用,但在密集的像素级预测任务(如目标检测、分割等)上却并不适合使用,主要原因有:
(1)其输出分辨率比较低,且只有一个单一尺度,输出步幅为32或者16;
(2)输入尺寸即使增大一点,也会造成计算复杂度和内存消耗的大幅增加。
为了解决ViT的上述缺陷,本文提出了金字塔视觉Transformer(Pyramid Vision Transformer,PVT),可以作为密集预测任务的backbone来使用,相比ViT,PVT主要克服了以下难点:
(1)使用了细粒度的图像patch(如:每个patch大小为4*4)作为输入,来学习高分辨率的特征表示,而这对密集预测任务来说比较重要;
(2)引入一种逐级收缩的金字塔,随着网络深度增加,逐渐减小Transformer的序列长度,显著降低了计算量;
(3)使用空间缩减注意力(SRA)层来进一步降低学习高分辨率表示的资源消耗。
总体来说,PVT的优点有:
(1)传统CNN backbone的感受野随着深度增加而逐渐增大,而PVT始终保持全局感受野(受益于Transformer中的自注意力机制,在所有patchs中执行注意力),这对检测、分割任务更为合适;
(2)相比ViT,引入了金字塔结构的PVT可以嵌入到很多经典的piplines中,如RetinaNet、Mask-RCNN等;
(3)可以和其他Transformer Decoder结合,组成无卷积的框架,如PVT+DETR进行端到端目标检测。
整体构架
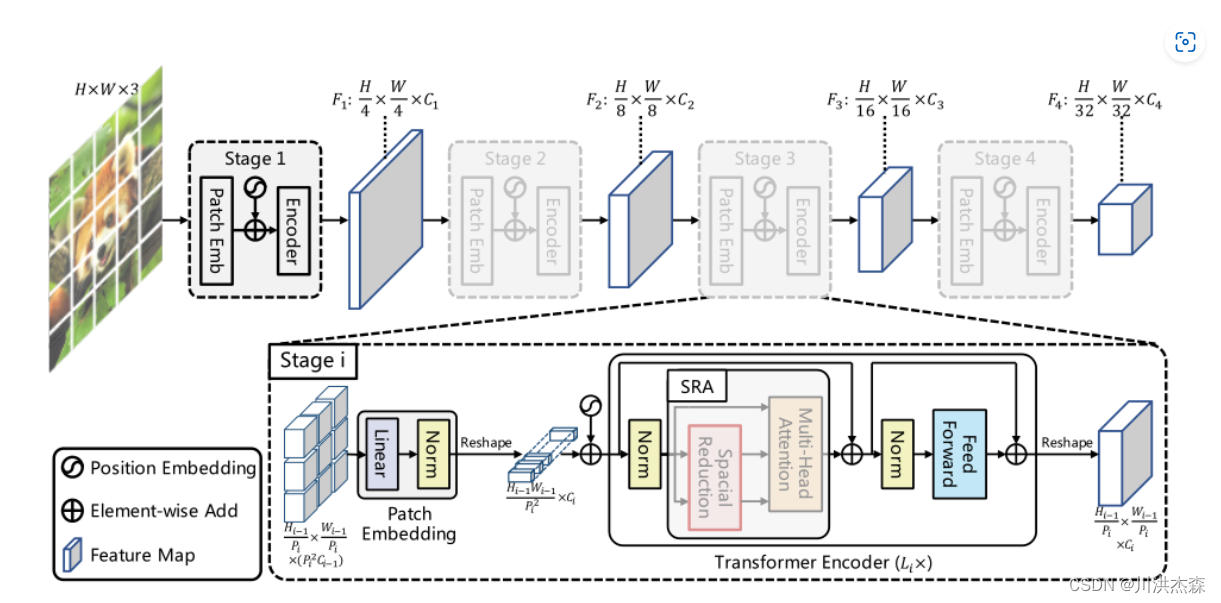
PVT的目的是在Transformer中引入特征金字塔,因此可以生成多尺度的feature maps用于密集预测任务。与CNN的backbone相似,PVT也有四个stage,每个stage生成不同尺度的feature maps,且每个stage结构相似,都由patch embedding 层和个Transformer Encoder层组成。
在第一个stage,输入图像的尺寸为,首先将其分解为个
patchs,每个patch大小为4*4*3。然后,将这些patchs拉直,进行线性投影得到嵌入后的patchs,其尺寸为
.接着,将嵌入后的patchs和位置嵌入一同送到一个L1层的Transformer Encoder,将输出reshape后得到 F1,尺寸为
,其中宽和高均比输入小4倍。
按照与第一个stage相似的方式,可以得到stage2~4的输出F2,F3,F4,其输出步幅分别为8,16,32。于是便得到了特征金字塔{F1,F2,F3,F4},其可以轻松用于各种下游任务,如分类、检测、分割等。
Transformer Encoder
针对stage i,其中的Transformer Encoder具有个Encoder层,每个Encoder层由注意力层和前馈层组成。由于所提出的PVT需要处理高分辨率的feature maps(如:4步长),因此提出了一个空间缩减注意力(SRA)层,替代传统的多头注意力(MHA)层。
与MHA相似,所提出的SRA同样接受query Q、key K、value V作为输入,不同之处在于SRA将K和V的宽高分别降低为原来的倍,如图4所示:
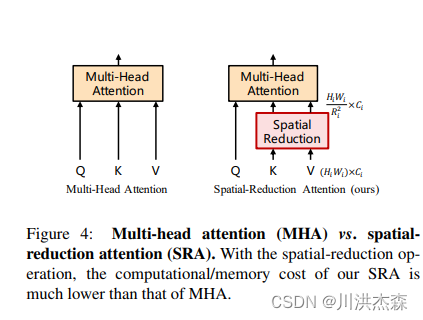
SRA的公式表示如下:

 实验结果
实验结果
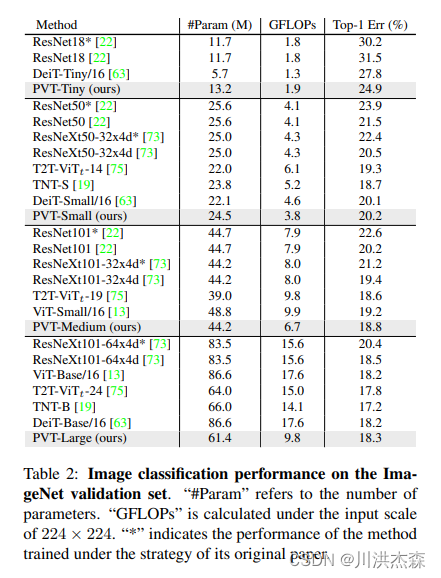
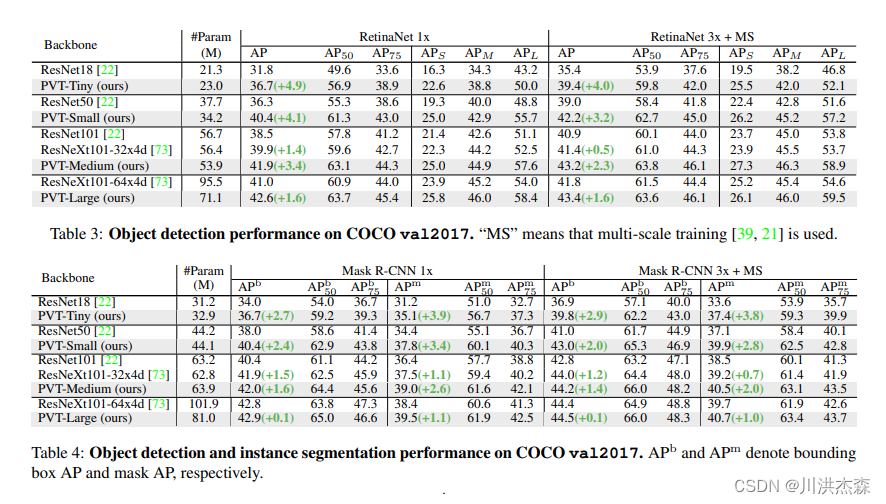
本文主要提出了一个纯Transformer的模型——PVT,可以作为下游密集预测的backbone使用。还设计了一个渐进缩减金字塔和一个空间缩减注意力层,在有限的资源下获取多尺度的、更高分辨率的输出。大量实验表明,PVT比一些设计良好的CNN backbone效果更好。
尽管PVT可以作为替代CNN backbone的一个选择,但是那些专门针对CNN设计的一些模块却不能用到PVT中,如SE、SK、空洞卷积、NAS等。此外,经过多年发展,CNN backbone也有很多优秀的设计,如Res2Net、EfficientNet、ResNeSt等。与之相反,在CV领域基于Transformer的模型研究仍处于初级阶段,这还需要未来持续不断的研究。
7.T2T-vit(ICCV-2021-引用1664)
推出背景
在像 ImageNet 这样的中等规模数据集上从头开始训练时,ViT 的表现要低于卷积神经网络 (CNN)。ViT 的局限性包括其对输入图像进行简单的分词,未能建模包括边缘和线条在内的局部结构,以及具有冗余的注意力骨干设计,从而导致功能丰富性有限并且模型训练存在困难。

本文首先分析了 Resnet50、Vision Transformer 和 T2T Transformer 的特征可视化。其中,绿框标注的是浅层特征,如边缘和线条;红框标注的是零值或过大值。
我们首先来看看熟悉的 CNN。在比较浅的层中,网络学习到更多的是结构信息,比如对这只小狗边缘的刻画。随着层数加深,通道数变深,特征也越来越抽象。
vit问题可以总结为两个方面:
1.输入图片的简单标记化(tokenization),无法很好的对局部特征进行建模
2.vit的self-attention的backbone设计的不好,信息冗余,计算量高,丰富度不够.
本文针对这两点分别提出T2T模块和更深窄的结构解决问题1和2
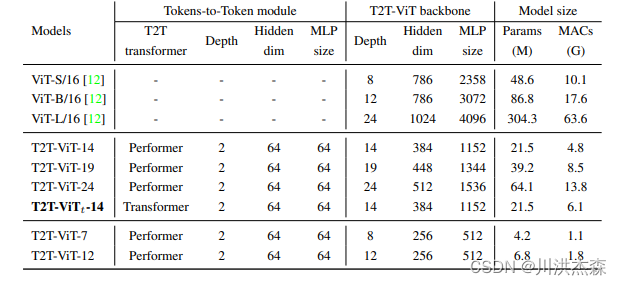
模型结构
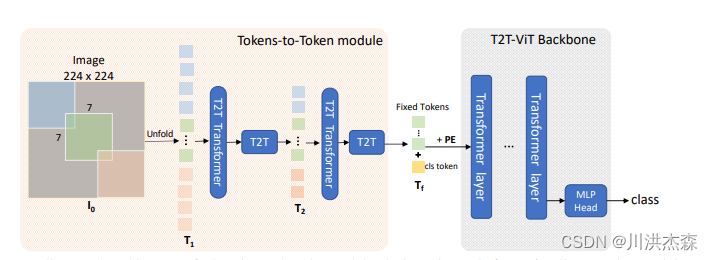
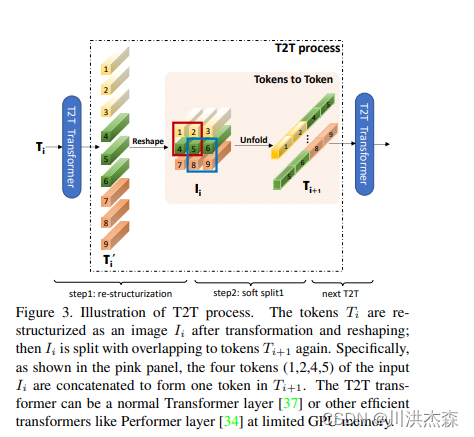
re-structurization: Tokens-to-Token 模块的输入是image patches 序列,这个序列通过一个 Transformer Block,即T‘=MLP(MSA(T)),得到了一个(l,c)维的T‘,对T‘进行reshape,还原成原来的image结构,T‘是带有self-attention信息的embedding,此时还原已经相当于带有全局信息的图像结构,从全流程图中看一开始224X224的图的patches是通过unfold操作产生的(没有用linear做映射的),l=hxw。
soft split:在re-constructurization中将transformer后的image patches重新reshape成了hxwxc,这一步是为了加强局部信息,用unfold采样了一部分重叠的patches。
可以这样理解:先是将reshape类似图像那种一张平面,然后再利用卷积操作,卷积能够获取到局部信息。通过t2t模块使输入信息融合局部信息。
使用 Deep-narrow 架构,即更少的通道数、更深的层数。并减少 embedding dimension 更适合视觉 Transformer,可以增加特征的丰富程度。同时减少 embedding dimension 也可以降低计算量。也就是加了T2T变成更深层数,更少通道数。
从图中我们看到,T2T 模块只有2层,按照前面的描述,这就意味着有3次 Soft Split (SS) 操作和2次 Restructurization 操作。3次 Soft Split (SS) 操作会有3次 torch.unfold 操作,使用的卷积核的大小分别是P=[7,3,3] ,patches 之间重叠的大小分别是[3,1,1] 。也就是说 stride 的大小分别是s=[4,2,2] 。这样一来,T2T 模块就会把 224×224 大小的图片变成 14×14 大小。(减少了通道数)
实验结果
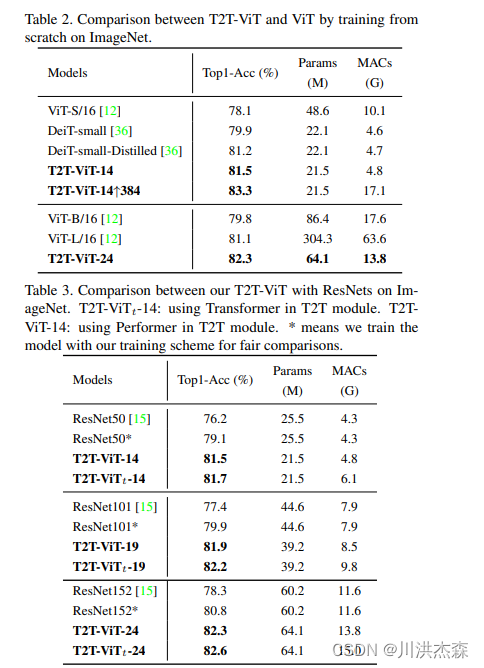
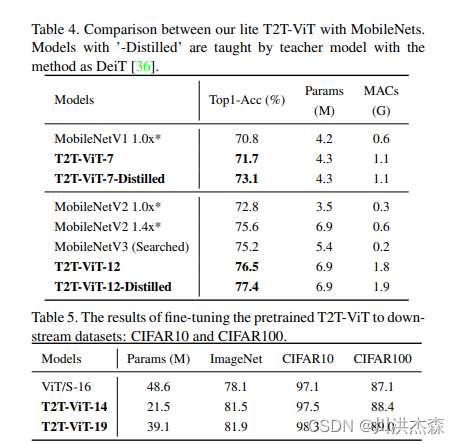
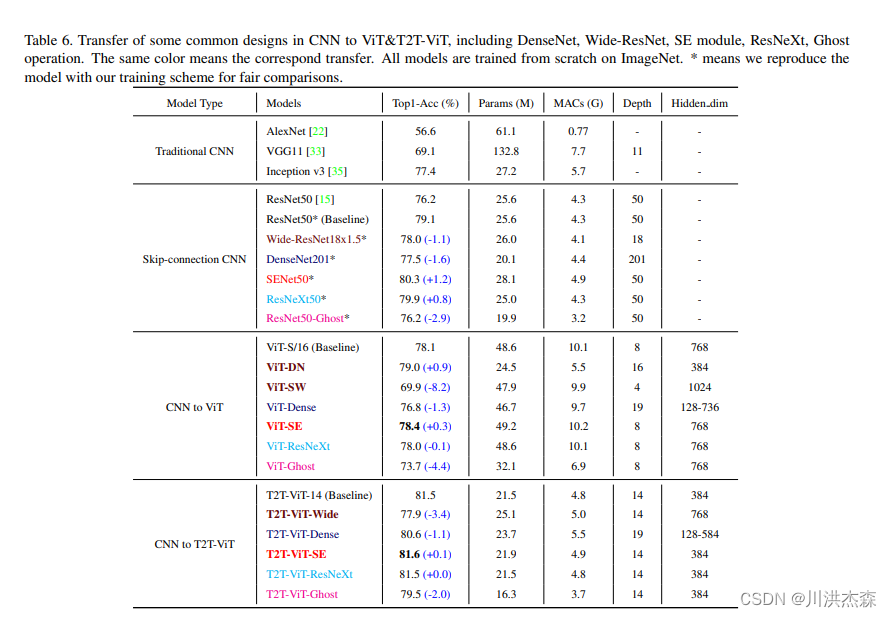
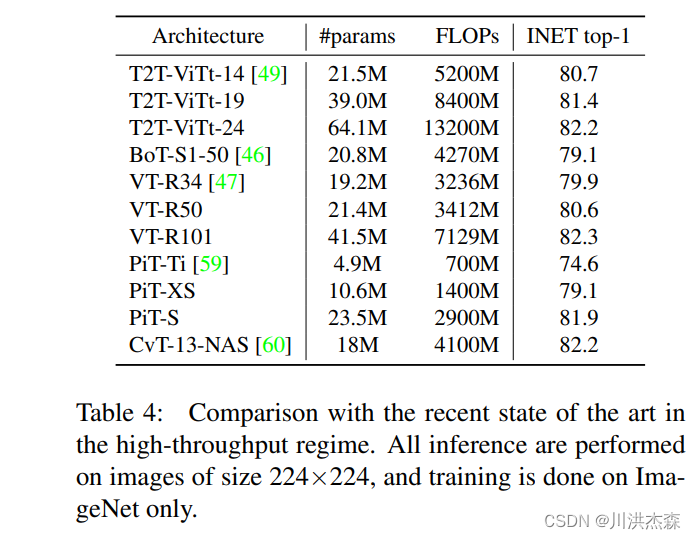
在这项工作中,提出了一种新的T2T-ViT模型,可以从头开始在ImageNet上进行训练,并达到与CNN甚至更好的性能。T2T-ViT有效地对图像的结构信息进行建模,并增强特征丰富性,克服了ViT的局限性。它引入了新的token到token(T2T)过程,逐步将图像token化为token并结构化聚合token。我们还探索了来自CNN的各种架构设计选择,以改善T2T-ViT的性能,并实证发现深窄的架构比浅宽的结构表现更好。当从头开始在ImageNet上进行训练时,我们的T2TViT在模型大小相似的情况下,比ResNets的性能更好,比MobileNets的性能相当。它为进一步开发基于变压器的视觉任务模型铺平了道路。
8.swin-transformer(iccv -2021-引用16631)
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
推出背景
虽然Vision Transformer (ViT)在图像分类方面的结果令人鼓舞,但是由于其低分辨率特性映射和复杂度随图像大小的二次增长,其结构不适合作为密集视觉任务或高分辨率输入图像的通过骨干网路。为了最佳的精度和速度的权衡,提出了Swin-Transformer结构。
模型结构
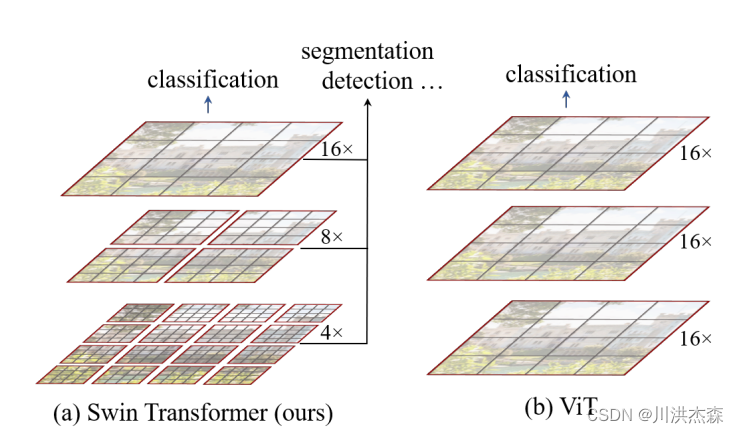
从上图中可以看出两种网络结构的部分区别:
- 采样方式
- Swin-Transformer开始采用4倍下采样的方式,后续采用8倍下采样,最终采用16倍下采样
- ViT则一开始就使用16倍下采样
- 目标检测机制
- Swin-Transformer中,通过
4倍、8倍、16倍下采样的结果分别作为目标检测所用数据,可以使网络以不同感受野训练目标检测任务,实现对大目标、小目标的检测 - ViT则只使用
16倍下采样,只有单一分辨率特征
- Swin-Transformer中,通过
1。swin-Transformer结构框架
接下来,简单看下原论文中给出的关于Swin Transformer(Swin-T)网络的架构图。其中,图(a)表示Swin Transformer的网络结构流程,图(b)表示两阶段的Swin Transformer Block结构。注意:在Swin Transformer中,每个阶段的Swin Transformer Block结构都是2的倍数,因为里面使用的都是两阶段的Swin Transformer Block结构。
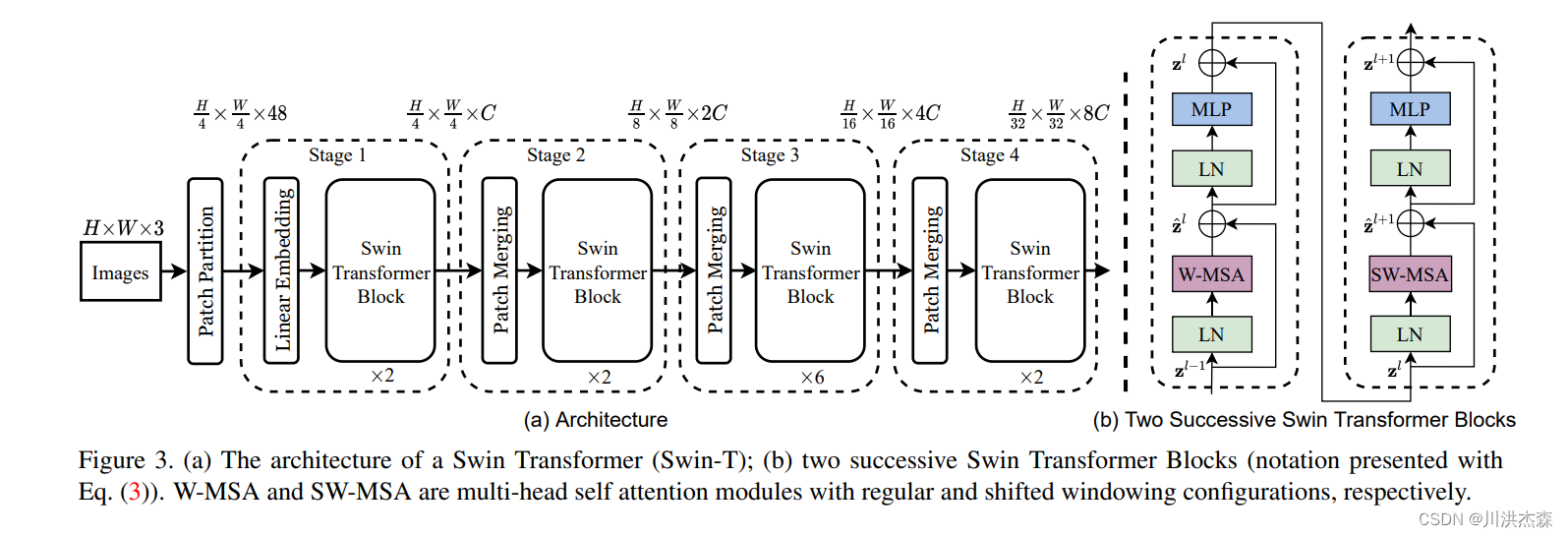
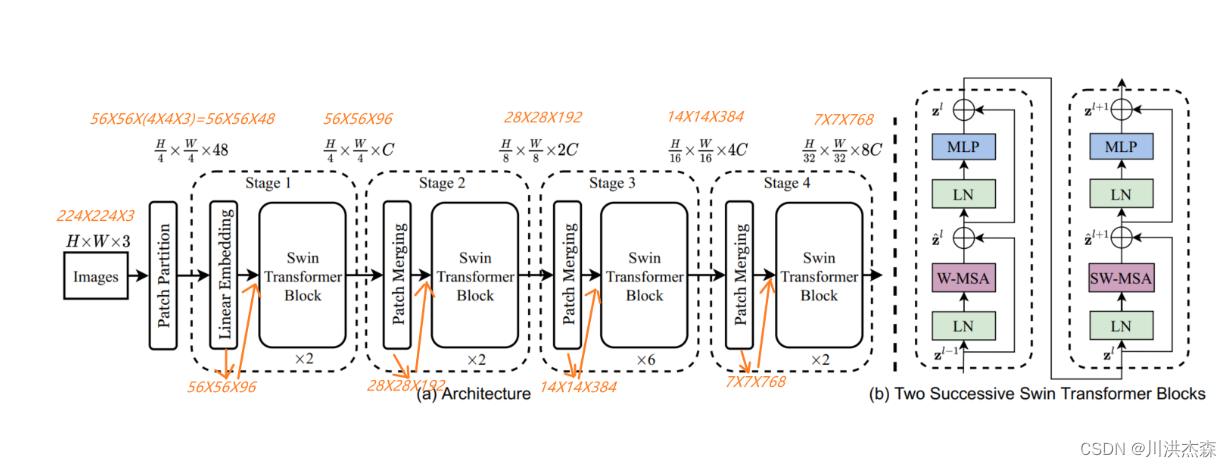 2.Swin-Transformer结构详解
2.Swin-Transformer结构详解
首先,介绍Swin-Transformer的基础流程。
- 输入一张图片 [ H ∗ W ∗ 3 ] [H*W*3] [H∗W∗3]
- 图片经过
Patch Partition层进行图片分割 - 分割后的数据经过
Linear Embedding层进行特征映射 - 将特征映射后的数据输入具有改进的自关注计算的
Transformer块(Swin Transformer块),并与Linear Embedding一起被称为第1阶段。 - 与阶段1不同,阶段2-4在输入模型前需要进行
Patch Merging进行下采样,产生分层表示。 - 最终将经过阶段4的数据经过输出模块(包括一个
LayerNorm层、一个AdaptiveAvgPool1d层和一个全连接层)进行分类。
2.1 Patch Partition
Patch Partition结构是将图片数据进行分割成不重叠的M*M补丁。每个补丁被视为一个“标记”,其特征被设置为原始像素RGB值的串联。在论文中,使用4 × 4的patch大小,因此每个patch的特征维数为4 × 4 × 3 = 48。在此原始值特征上应用线性嵌入层(Linear Embedding),将其投影到任意维度(记为C)。
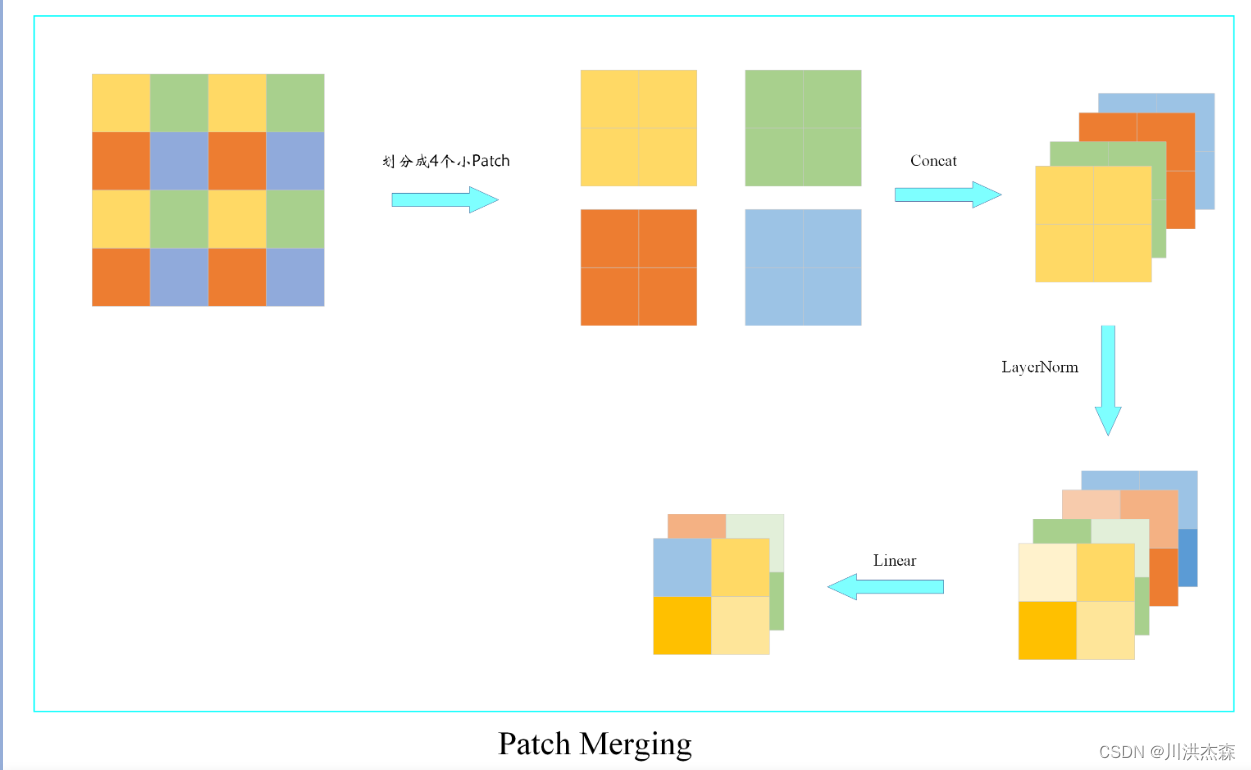
2.2 Patch Merging
Patch Merging层主要是进行下采样,产生分层表示。随着网络的深入,通过Patch Merging层来减少令牌的数量。第一个补丁合并层将每组2 × 2相邻补丁的特征进行拼接,并在拼接后的4c维特征上应用线性层。这将令牌的数量减少2×2 = 4的倍数(分辨率的2倍降采样,长和宽分别变为原来的1/2),并将输出维度设置为2C。之后使用Swin Transformer块进行特征变换,分辨率保持在h8 × w8。这第一个块的补丁合并和特征转换被称为“第二阶段”。该过程重复两次,作为“阶段3”和“阶段4”,输出分辨率分别为h16 × w16和h32 × w32。由上述的说明,可以得知:数据在经过Patch Merging层后,长宽变为原来的1/2,深度变为原来的2倍----特征图分辨率减半,通道数翻倍。
2.3 Swin Transformer Block
Swin Transformer Block 一般以2阶段的串联结构出现,在第一阶段使用Window based Multi-headed Self-Attention(W-MSA),第二阶段使用 Shifted Window based Multi-headed Self-Attention(SW-MSA),根据当前是奇数还是偶数的Swin Transformer Block来选择不同的自关注计算方式。
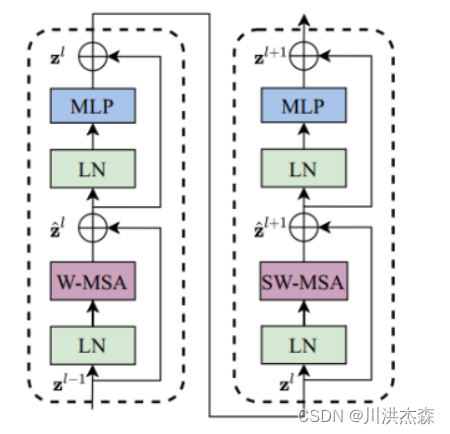
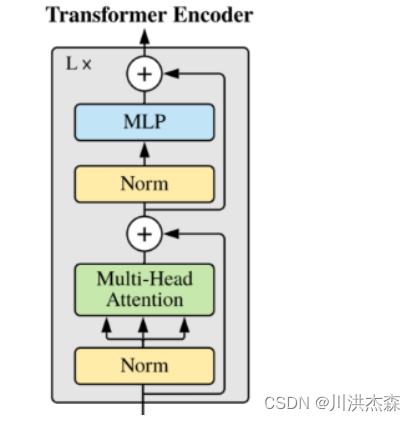
对照这两个图,你可能会发现结构基本是一样的。主要区别只在一个地方,即ViT Encoder绿框中的Multi-Head Attention和Swin Transformer Block紫框中的W-MSA(Windows Multi-Head Attention) \SW-MSA(Shifted Windows Multi-Head Attention)。Swin Transformer Block中的两个结构的区别也只在这里有所不同,下面我就重点来为大家讲讲W-MSA和SW-MSA。
2.3.1 W-MSA
W-MSA全称为:Window based Multi-headed Self-Attention。从名字可以看出,W-MSA是一个窗口化的多头自注意力,与全局自注意力相比,减少了大量的计算量。直观上来说:假如说是4*4的数据,划分后每个窗口包括 M ∗ M M*M M∗M 块,这里假设 M = 2 M=2 M=2。如果进行MSA计算大概需要 ( 4 ∗ 4 ) 2 (4*4)^2 (4∗4)2的计算量,而进行W-MSA则大概需要 ( 2 ∗ 2 ) ∗ ( 2 ∗ 2 ) 2 (2*2)*(2*2)^2 (2∗2)∗(2∗2)2。这样一对比瞬间计算的复杂度就降低了很多(当然上述只是为了方便简单的理解,下面就详细介绍W-MSA降低了多少复杂度)。即只计算红色小窗口内部的多头注意力,而不是整个所有的图像块的像素,这样计算量减少。如下图:
MSA计算量
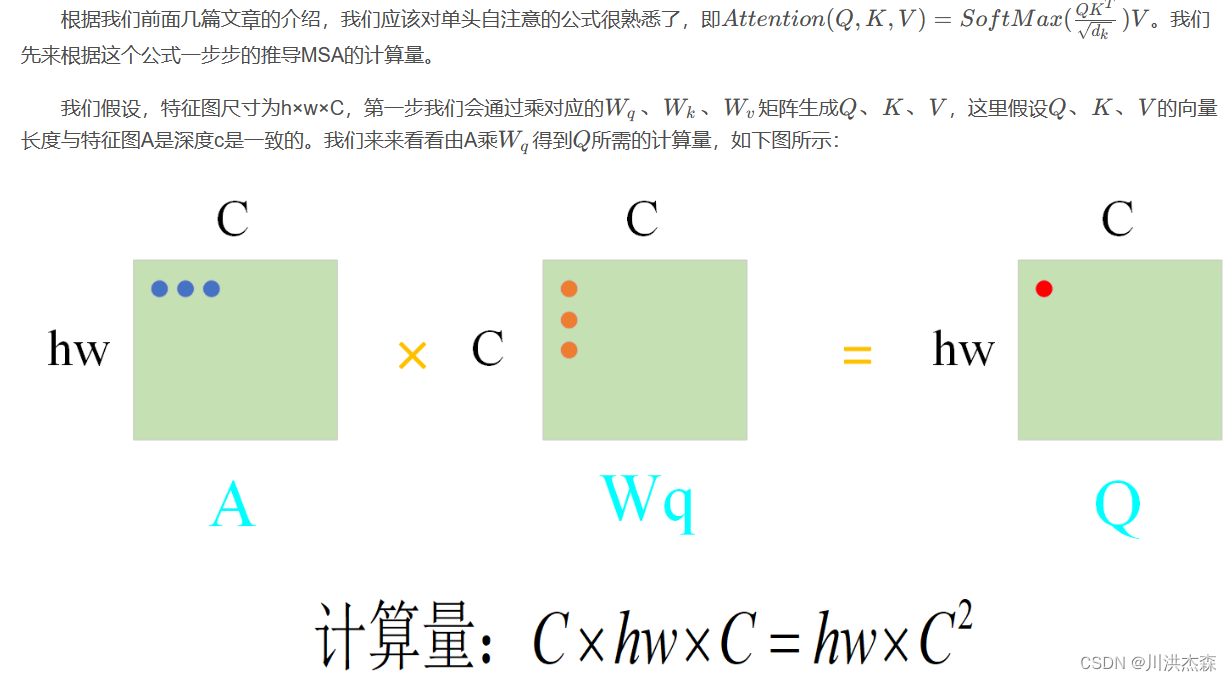

W-MSA计算量

SW-MSA
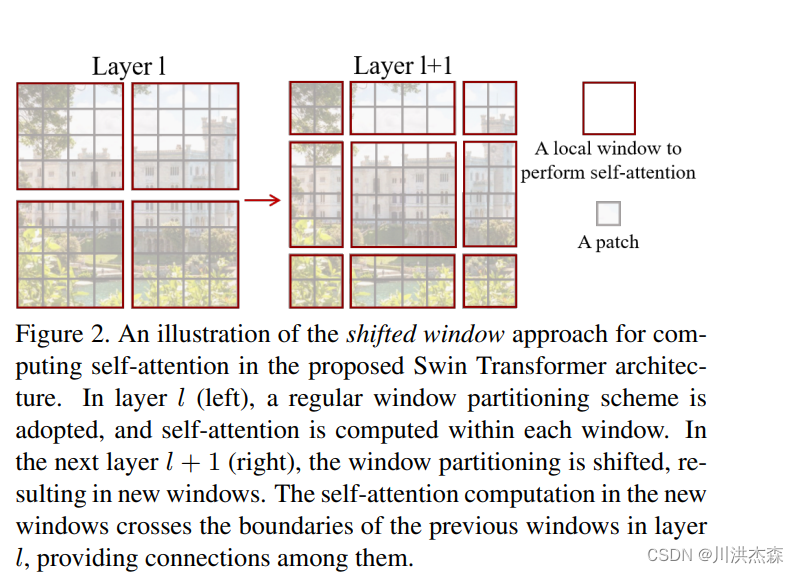
我认为这可以理解为一个小技巧。何为SW-MSA,即shifted Windows Multi-Head Attention。我们先来想想我们为何要使用SW-MSA,这是由于W-MSA将原始特征图分成一个个小窗口,然后分别送入MSA中,这会导致各个窗口之前没有任何的联系,都是独立的,这显然不是我们期望看到的。而SW-MSA的出现就是为了解决这个问题,SW-MSA具体是怎么设计的,我们来看论文中的图片解释:
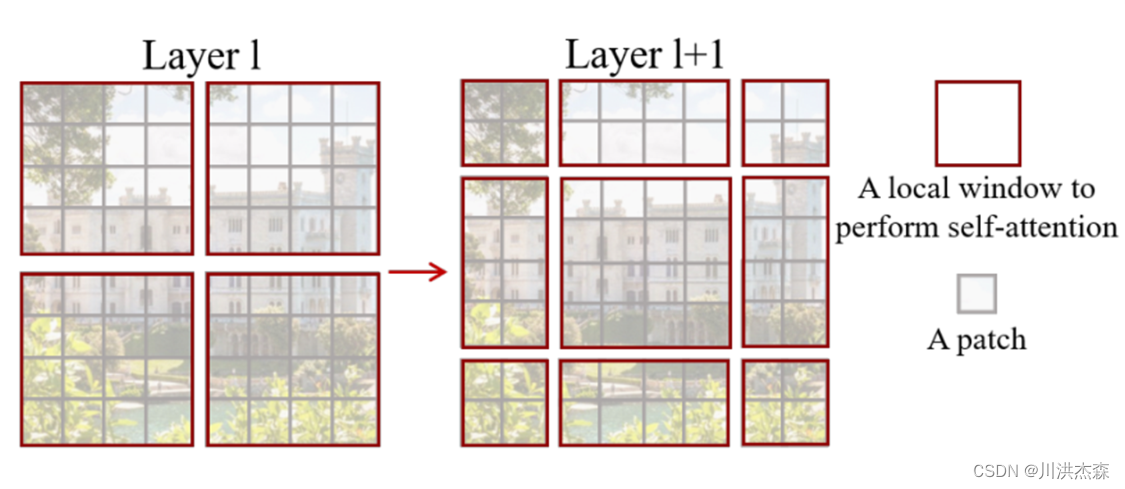
左图是W-MSA,右图是SW-MSA,它们分别出现在Swin Transformer Block的相邻两层中。若W-MSA在Layer1层使用,则SW-MSA在Layer1+1层使用。
再来看看SW-MSA做了什么?SW-MSA会重新划分窗口,即由上图左侧变成上图右侧,这样划分过后会形成9个大小形状不同的窗口,这样就解决了窗口直接无法进行信息传递的问题。我们以上图右侧第二行第二列中间4×4的窗口为例,这一个窗口结合了Layer1层中四个窗口的信息,是不是很巧妙呢!至于这个窗口怎么划分,这部分不作太细讲,也是一套流程,但论文的核心我觉得在于MSA这块。
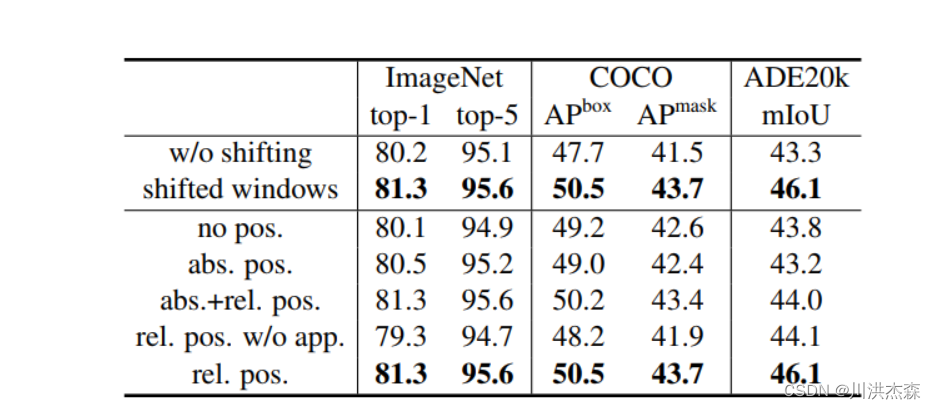
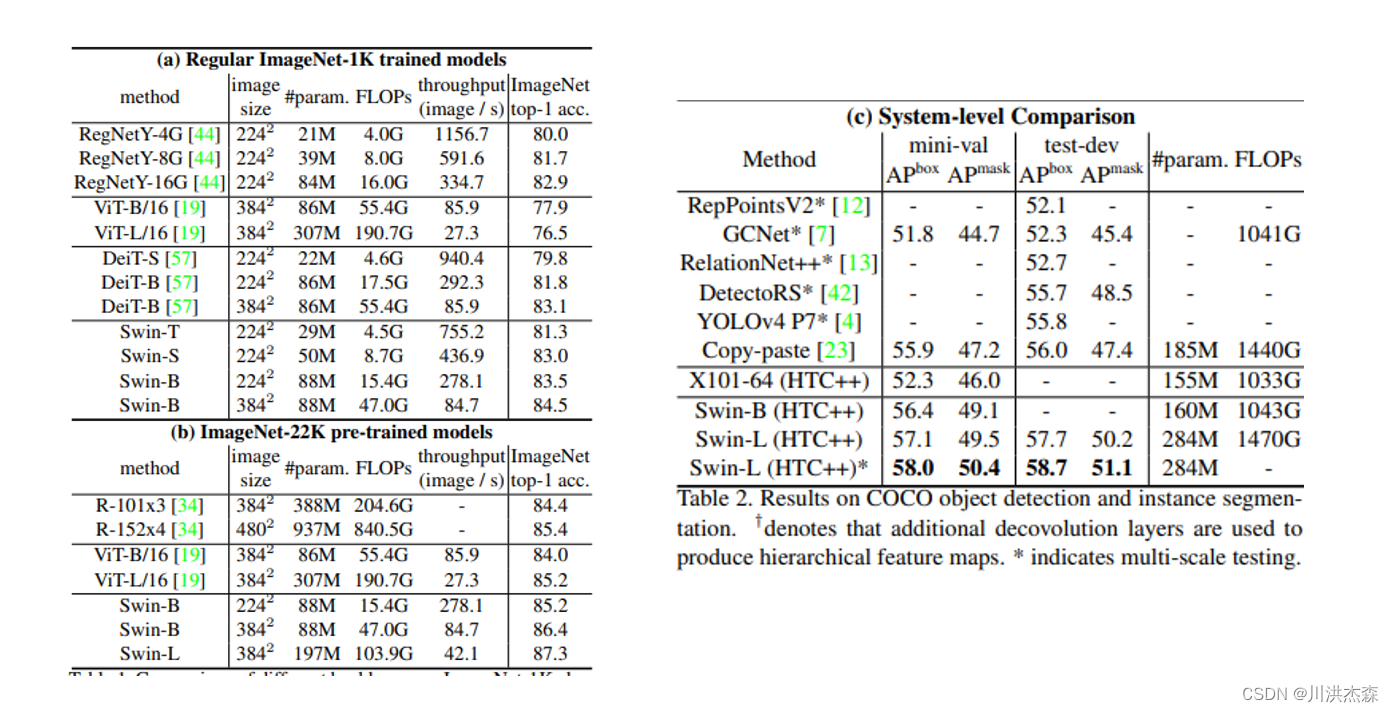
实验结果
消融实验:

















 626
626

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









