







📮 求内推
👩 个人简介:听障人,96年,计算机专业(本科),从事数据分析工作
🛠 语言与工具:包括但不限于Python、SQL、tableaubi、finebi、powerbi。
💻 期望岗位:数据分析、数据运营、报表开发等(hc偏技术方向)
📍 期望城市:杭州
背景描述
在竞技体育中,运动员的健康和安全是至关重要的。运动损伤不仅可能会对运动员的职业生涯造成严重影响,还可能影响到团队的整体表现。因此,预防和减少运动员的伤病风险成为了许多体育组织和教练团队的首要任务。通过深入了解运动员的身体状况、训练情况以及过往的伤病历史,我们可以更好地预测未来的伤病情况,从而采取相应的措施来保障运动员的健康。
问题描述
运动员受伤风险的影响因素分析
特征相关性分析
特征重要性分析
数据来源
和鲸社区(搜运动员之类关键词)
数据处理及预览
import pandas as pd
import plotly.express as px
import plotly.graph_objects as go
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
# 随机森林模型(Random Forest)
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
df = pd.read_csv(r'D:\pythonbag\Datas\injury_data.csv')
print('-'*80)
print('数据集存在重复值个数:')
print(df.duplicated().sum())
print('数据集存在缺失值个数:')
print(df.isna().sum())
print('-'*80)
print(df.info())
print('-'*80)
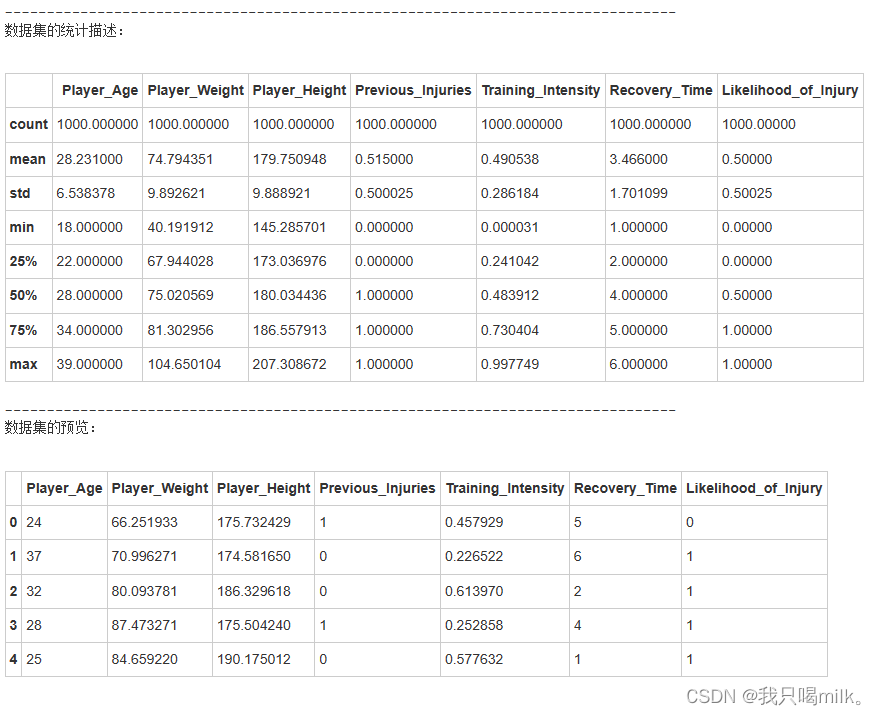
print('数据集的统计描述:')
display(df.describe())
print('-'*80)
print('数据集的预览:')
display(df.head(5))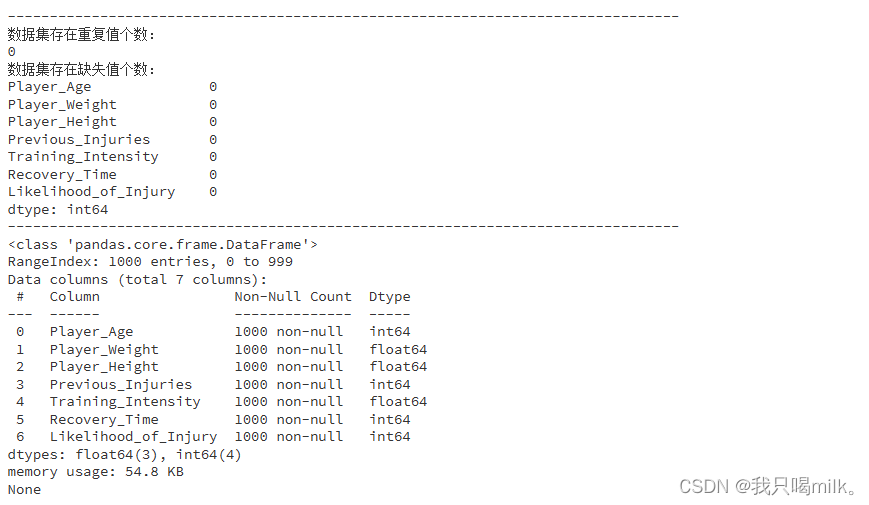
step1.受伤风险的影响因素分析¶
探索各个特征对受伤可能性的影响大小,例如年龄、体重、身高、曾受过伤与否、身体恢复时长、训练强度
avg_df = df.groupby(by='Likelihood_of_Injury').mean()
display(avg_df)
my_palette=['#C6E3A1','#FF6F61','#362F80']
sns.set_palette(my_palette)
plt.rcParams['font.sans-serif']=['SimHei']
fig,axes=plt.subplots(nrows=2,ncols=3,figsize=(12,10))
sns.barplot(x='Likelihood_of_Injury',y='Player_Age',data=avg_df,ax=axes[0,0],hue='Likelihood_of_Injury',legend=False,width=0.3)
axes[0,0].set_title('受伤与否的年龄平均分布',fontsize=12)
sns.barplot(x='Likelihood_of_Injury',y='Player_Weight',data=avg_df,ax=axes[0,1],hue='Likelihood_of_Injury',legend=False,width=0.3)
axes[0,1].set_title('受伤与否的体重平均分布',fontsize=12)
sns.barplot(x='Likelihood_of_Injury',y='Player_Height',data=avg_df,ax=axes[0,2],hue='Likelihood_of_Injury',legend=False,width=0.3)
axes[0,2].set_title('受伤与否的身高平均分布',fontsize=12)
sns.barplot(x='Likelihood_of_Injury',y='Previous_Injuries',data=avg_d 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 776
776

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









