







前言
1. 专有名词
SRAM:Static Random-Access Memory,静态随机存储器
之所以叫静态,是因为只要有电,数据就可以保持存在,而一旦断电,数据就会丢失。
DRAM:Dynamic Random Access Memory,动态随机存取存储器
之所以叫动态,是因为数据存储在电容里,电容会不断漏电,需要定时刷新电容,才能保证数据不会丢失
SSD:Solid-state disk,固态硬盘
HDD:Hard Disk Drive,机械硬盘
TLB:Transaction Lookaside Buffer,页表缓存,快表
MMU:Memory Management Unit,内存管理单元,用来完成地址转换和TLB的访问与交互
PCB:Process Control Block,进程控制块
TCB:Thread Control Block,线程控制块
FCFS:First Come First Serverd,先来先服务
SJF:Shortest Job First,短作业优先
HRRN:Highest Response Ratio Next,高响应比优先
RR:Round Robin,时间片轮转
HPF:Highest Priority First,最高优先级
MFQ:Multilevel Feedback Queue,多级反馈队列
2. 计算机结构
(1)图灵机的工作方式
图灵机基本组成:
1. 一条纸带,由一个个连续的格子组成,格子可以写入字符。
纸带好比内存,存入格子的字符好比内存中的数据或程序。
2. 一个读写头,可以读取纸带上任意格子的字符,也可以把字符写入格子
读写头的组成:
1. 存储单元:存放数据
2. 控制单元:用于识别字符是数据还是指令,以及控制程序的流程等
3. 运算单元:用于执行运算指令
工作原理:
以1+2作为例子
1. 首先,读写头把1、2、+这三个字符分别写入纸带上的3个格子,然后读写头先停在1字符对英国的格子上
2. 读写头读入1到存储设备中,这个存储设备称为图灵机的状态
3. 然后读写头向右移动一个格,用同样的方式把2读入图灵机的状态
4. 再向右,碰到+号,将+号传输给控制单元;控制单元发现不是数字就没有存入到状态中,于是通知运算单元。
运算单元收到要加和状态中的值的通知后,就会把状态中的1和2读入并计算,再将计算的结果3存入到状态中。
(2)冯诺依曼模型
* 规定了二进制进行计算和存储
* 定义了计算机基本结构:中央处理器(CPU)、内存、输入设备、输出设备、总线
这五个部分也被称为冯诺依曼模型。
1. 内存
* 程序和数据都是存储在内存,存储的区域是线性的
* 数据存储的单位是一个二进制位(bit),即0或1。
* 最小的存储单位是字节(byte),1 byte = 8 bit
* 内存的地址是从0开始编号的,最后一个地址为内存总字节数 - 1。
2. 中央处理器
* 32位CPU一次可以计算4byte
* 64位CPU一次可以计算8byte
* 32位和64位这里指的是CPU的位宽;CPU位宽越大,可以计算的数值就越大;
32位CPU最大能计算的整数是4294967295
CPU内部常见的组件:
1. 寄存器
2. 控制单元:负责控制CPU工作
2. 逻辑单元:负责计算
常见的寄存器种类:
1. 通用寄存器:用来存放需要进行运算的数据,比如需要进行加和运算的两个数据。
2. 程序计数器:用来存储CPU要执行下一个指令所在的内存地址。
3. 指令寄存器:用来存放程序寄存器指向的指令,也就是指令本身。指令被执行完成之前,指令都存储在这里。
3. 总线
1. 地址总线:用于指定CPU将要操作的内存地址
2. 数据总线:用于读写内存的数据
3. 控制总线:用于发送和接收信号,比如中断、设备复位等信号,CPU收到信号后自然进行响应,这时也需要控制总线
当CPU要读写内存数据的时候,一般需要通过两个总线:
1. 首先通过地址总线来指定内存的地址
2. 再通过数据总线来传输数据
4. 输入、输出设备
输入设备向计算机输入数据,计算机经过计算后,把数据输出给输出设备。
期间,如果输入设备是键盘,按下键时需要和CPU进行交互,这时就需要用到控制总线了。
(3)程序执行的基本过程

1. CPU读取程序计数器的值,这个值是指令的内存地址;
然后CPU的控制单元操作地址总线指定需要访问的内存地址;
接着通知内存设备准备数据,数据准备好后通过数据总线将指令数据传给CPU;
CPU收到内存传来的数据后,将这个指令数据存入到指令寄存器。
2. CPU分析指令寄存器中的指令,确定指令的类型和参数。
如果是计算类型的指令,就把指令交给逻辑运算单元;如果是存储类型的指令,则交给控制单元执行。
3. CPU执行完指令后,程序计数器的值自增,表示指向下一条指令。
这个自增的大小,由CPU的位宽确定,比如32位CPU,指令是4byte,则自增4。
总结:一个程序执行的时候,CPU会根据程序计数器的内存地址,从内存里面把需要的指令读取到指令寄存器里面执行,然后根据指令长度自增,开始顺序读取下一条指令。
CPU 从程序计数器读取指令、到执⾏、再到下⼀条指令,这个过程会不断循环,直到程序执⾏结束,这个 不断循环的过程被称为 CPU的指令周期。
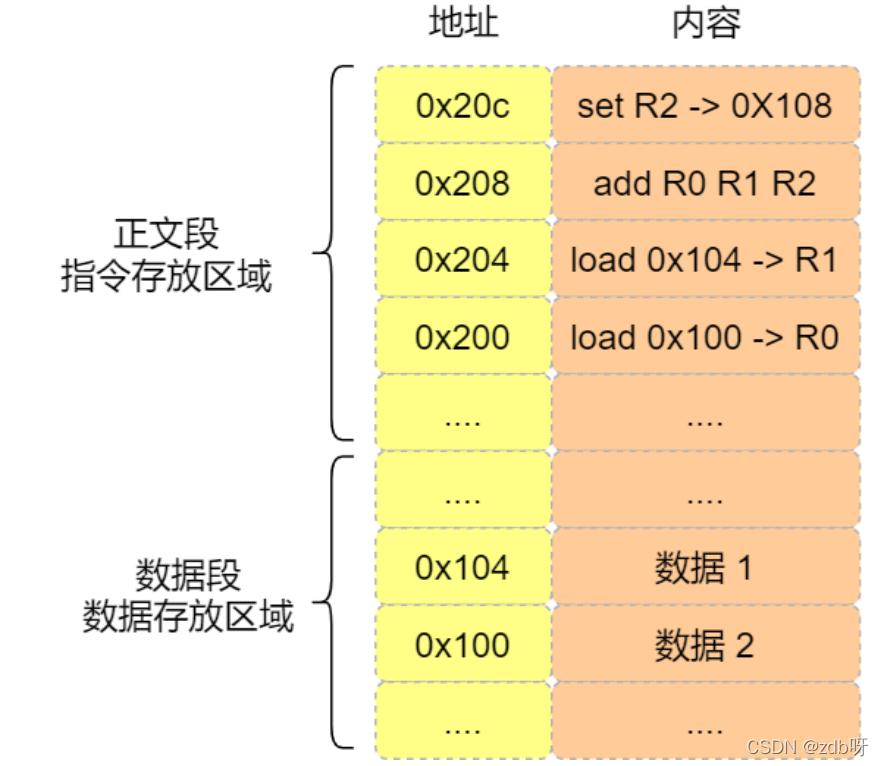
(4)a = 1 + 2执行具体过程
CPU是不认识a=1+2这个字符串,这里需要由汇编器译成机器码。
程序编译过程中,编译器通过分析代码,将1、2存放在内存的数据段;
* 数据1存放在0x100位置
* 数据2存放在0x104位置
编译器会把a=1+2翻译成4条指令,存放在正文段。
* 0x200的内容:load指令将0x100地址中的数据1装入到寄存器R0
* 0x204的内容:load指令将0x104地址中的数据2装入到寄存器R1
* 0x208的内容:add指令将寄存器R0和R1的数据相加,并把结果存放在寄存器R2
* 0x20c的内容:store指令将寄存器R2中的数据存回数据段中的0x108地址中,这个地址也就是变量a内存中的地址
(5)为什么0.1+0.2不等于0.3?
因为计算机用二进制存储数据,由于计算机的资源有限,不能用二进制精确的表示0.1和0.2,会造成精度缺失。
只能得到一个近似于0.3的值,
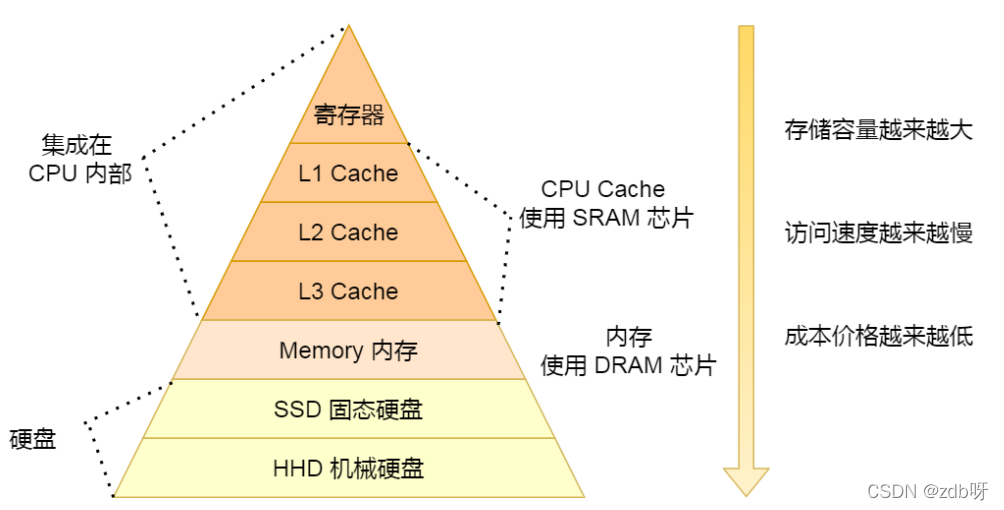
3. 存储器金字塔
(1)存储设备
1. 寄存器
2. 高速缓存器
3. 内存
4. SSD/HDD硬盘
1. 寄存器
最靠近CPU控制单元和逻辑单元的存储器;速度最快,价格最贵,数量不多
寄存器的数量常在几十~几百,每个寄存器可以用来存储一定字节的数据。
* 32位CPU中大多数寄存器可以存储4byte
* 64位CPU中大多数寄存器可以存储8byte
2. CPU Cache 高速缓存器
* L1-Cache
* L2-Cache
* L3-Cache
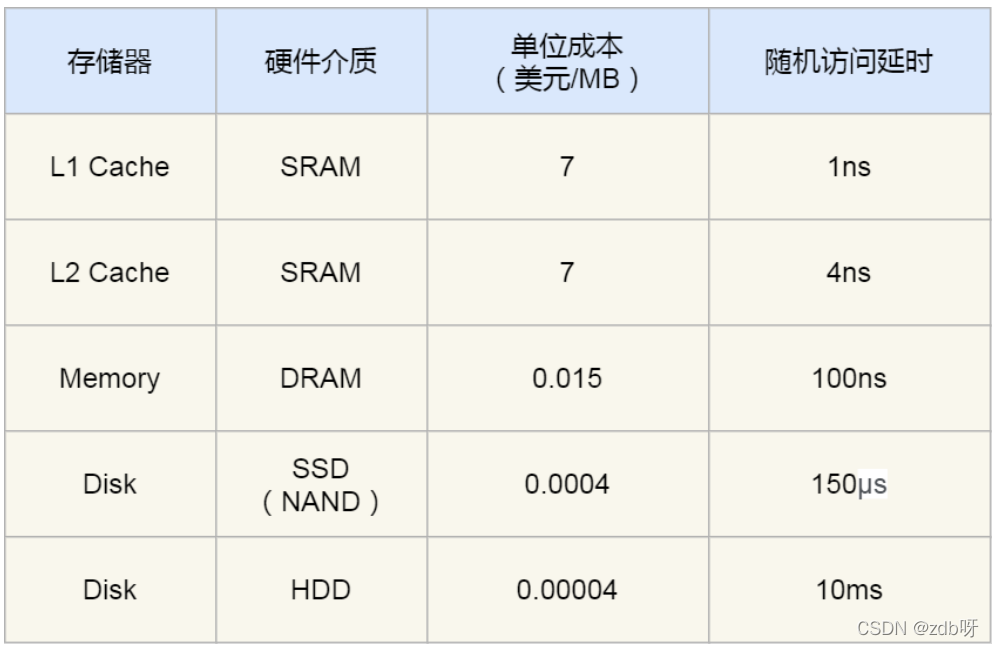
CPU Cache用SRAM的芯片。
L1高速缓存:访问速度几乎和寄存器一样快,通常只需要2~4个时钟周期,而大小在几十KB~几百KB
每个CPU核心都有一块属于自己的L1高速缓存
* L1指令缓存
* L1数据缓存
L2高速缓存:大小在几百KB~几MB;访问速度在10~20个时钟周期;每个CPU核心都有一块属于自己的
L3高速缓存:多个CPU核心共用;大小在几MB~几十MB;访问速度20~60个时钟周期
3. 内存
使用的是DRAM芯片
内存速度大概在200~300个时钟周期
4. SSD/HDD硬盘
(2)访问数据流程
访问数据流程: 寄存器->高速缓存器->内存->磁盘
1. CPU先访问寄存器,如果寄存器有这个数据,CPU就直接从寄存器取数据即可。
2. 寄存器没有这个数据,则接着查询L1高速缓存;L1没有再查询L2;L2没有再查询L3。
3. L3没有,才去内存中取数据。
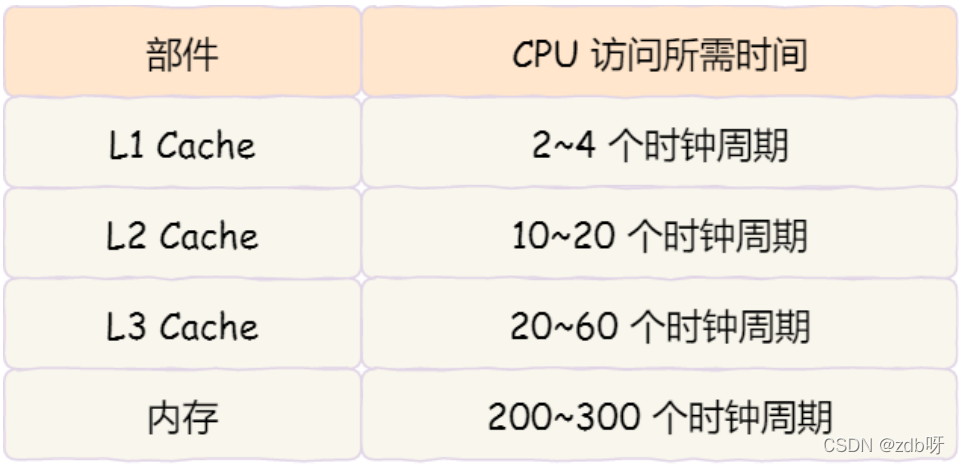
时钟周期是CPU主频的倒数;比如2GHZ主频的CPU,一个时钟周期是0.5ns。
Linux系统中,大概L1 Cache是32KB,L2 Cache是256KB,L3 Cache是3MB。
(3)如何写出让CPU跑的更快的代码?
靠提高缓存命中率:
1. 提高数据缓存的命中率
在遍历数据的时候,应该按照内存布局的顺序操作,这是因为CPU Cache是根据CPU Cache Line批量操作数据的,所以顺序地操作连续内存数据时,性能能得到有效的提升。
2. 提高指令缓存的命中率
有规律的条件分支语句能够让CPU的分支预测器发挥作用,进一步提高执行的效率。
(4)CPU Cache的数据结构和读取过程?
CPU Cache的数据结构:
CPU Cache的数据是从内存中读取过来的,它是以一小块一小块读取数据的,而不是按照单个数组元素来读取数据的;
在CPU Cache中,这样的一小块数据,称为Cache Line(缓存块,高速缓存行)。
大小一般为64byte
* 当CPU访问数据的时候,先是访问CPU Cache,如果缓存命中的话,则直接返回数据,就不用每次都从内存读取数据;
* 如果CPU Cache没有缓存该数据,则会从内存读取数据,但是并不是指读取一个数据,而是一次性读取一块一块的数据存放到CPU Cache中,之后才会被CPU读取。
对于直接映射Cache采⽤的策略,就是把内存块的地址始终「映射」在⼀个CPU Line(缓存块)的地址,⾄于映射关系实现⽅式,则是使⽤「取模运算」,取模运算的结果就是内存块地址对应的CPU Line(缓存块)的地址。
举个例⼦,内存共被划分为32个内存块,CPU Cache共有8个CPU Line,假设CPU想要访问第15号内存块,如果15号内存块中的数据已经缓存在CPU Line中的话,则是⼀定映射在7号CPU Line中,因为15 % 8的值是7。
可以发现有多个内存块对应同一个CPU Line;因此,为了区别不同内存块,在对应的CPU Line中我们还会存储⼀个组标记(Tag)。
这个组标记会记录当前CPU Line中存储的数据对应的内存块。
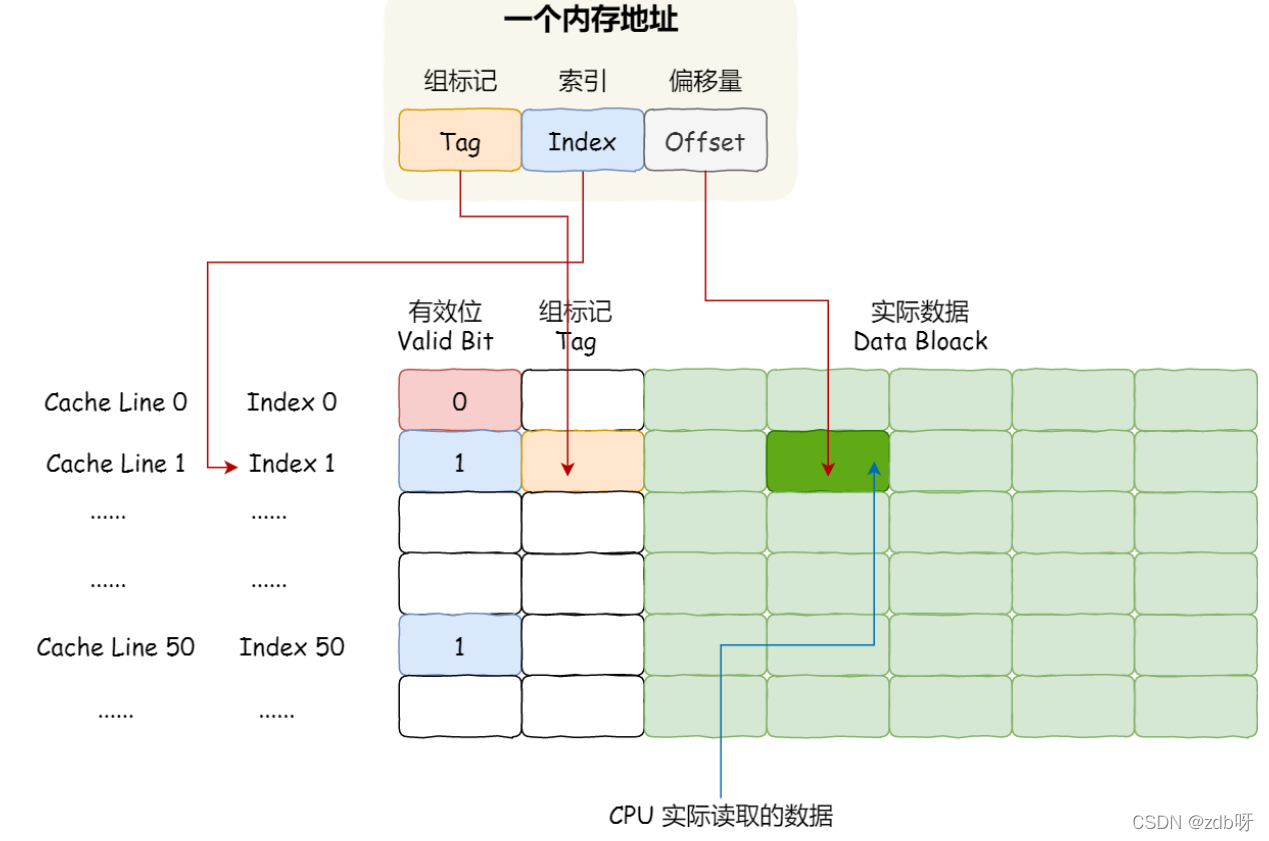
内存地址映射到CPU Cache地址里的策略:
直接映射Cache,巧妙的把内存地址拆分成【索引+组标记+偏移量】的方式
如果内存中的数据已经在CPU Cache中,CPU访问一个内存地址的步骤:
1. 根据内存地址中索引信息,计算在CPU Cache中的索引,也就是找出对应的CPU Line的地址
2. 找到CPU Line后,判断CPU Line中的有效位,确认CPU Line中数据是否有效;
如果无效,CPU就会直接访问内存,并重新加载数据,如果数据有效,则往下执行
3. 对比内存地址中组标记和CPU Line中的组标记,确认CPU Line中的数据是我们要访问的内存数据;
如果不是,CPU就会直接访问内存,并重新加载数据;
4. 根据内存地址中偏移量信息,从CPU Line的数据块中,读取对应的字。
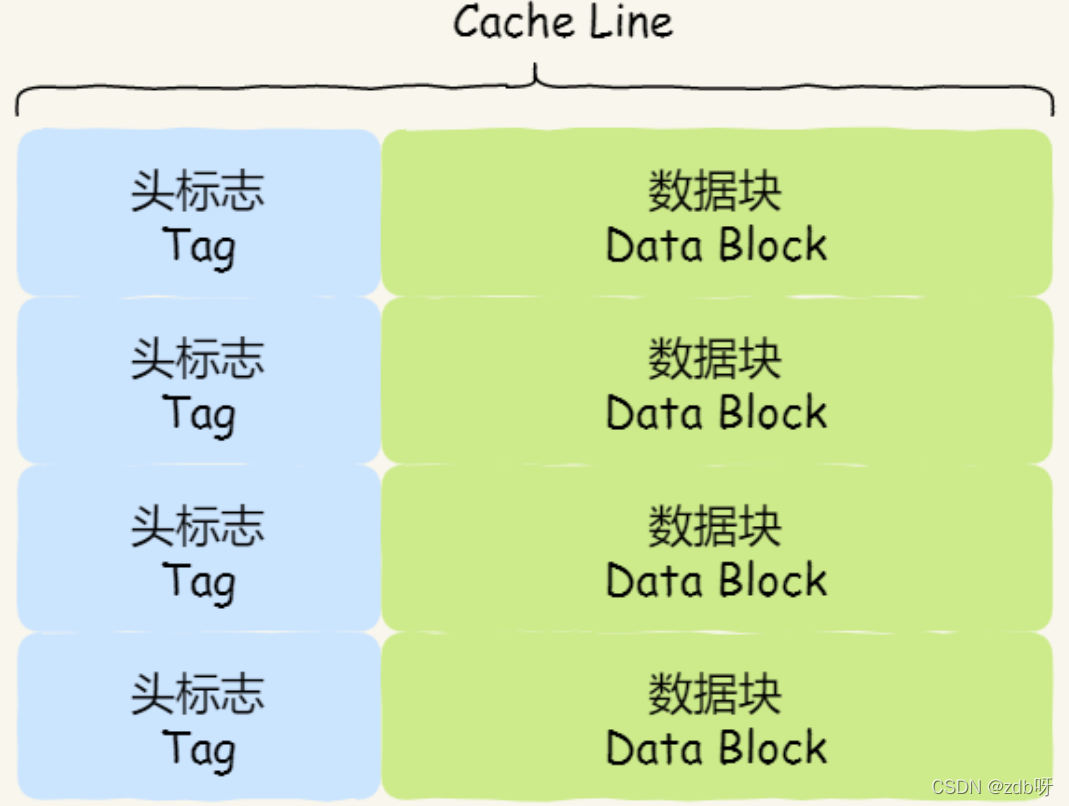
(5)Cache Line的数据结构
由各种标志(Tag)+数据块(Data Block)组成
(6)CPU Cache的数据写入
写直达(Write Through):将数据同时写入内存和Cache中
在这个方法里,写入前会先判断数据是否已经在CPU Cache里面:
* 如果不在,先将数据更新到Cache里面,再写入内存里面
* 如果在,直接把数据更新到内存里面
写直达由于每次写操作都会把数据写回到内存,而导致影响性能,于是为了要减少数据写回内存的频率,就出现了写回方法
写回(Write Back):当发生写操作时,新的数据仅仅被写入Cache Block里,只有当修改过的Cache Block被替换时才需要写到内存中,减少数据写回内存的频率。
写回流程:
1. 如果当发生写操作时,数据已经在CPU Cache里的话,则把数据更新到CPU Cache里,同时标记CPU Cache里的这个Cache Block为脏(Dirty)的。这个时候CPU Cache里面的Cache Block的数据和内存是不一致的,这种情况是不用把数据写到内存里面的。
2. 如果当发生写操作时,数据所对应的Cache Block里存放的是别的内存地址的数据,就要检查Cache Block里的数据有没有标记为脏;
如果是,就要Cache Block里的数据写回到内存,然后再把当前数据写入Cache Block里,同时也把它标记为脏;
如果不是,则直接将数据写入到Cache Block里,然后标记为脏。
(7)请你回答一下为什么要有 page cache,操作系统怎么设计的 page cache
加快从磁盘读取文件的速率。
page cache中有一部分磁盘文件的缓存,因为从磁盘中读取文件比较慢,所以读取文件先去page cache中去查找,如果命中,则不需要去磁盘中读取,大大加快读取速度。
在Linux内核中,文件的每个数据块最多只能对应一个Page Cache项,它通过两个数据结构来管理这些Cache项,一个是radix tree,另一个是双向链表。
* Radix tree是一种搜索树,Linux内核利用这个数据结构来通过文件内偏移快速定位Cache项
3. 缓存一致性
(1)缓存一致性问题
CPU多核心的缓存一致性问题(Cache Coherence)
例如两核,初始i=0
* A号核心执行i++,采用写回策略,先把值1的执行结果写入L1/L2 Cache中,然后把L1/L2 Cache对应的Block标记为脏,这个时候数据没有同步到内存中。
* B号核心也尝试从内存读取i第值,这时候还是0
这就是所谓的缓存一致性问题,A核心和B核心的缓存是不一致的,从而会导致执行结果错误。
(2)怎么解决缓存不一致问题
需要一种机制,来同步两个不同核心里面的缓存数据;要实现这个机制需要做到:
1. 某个CPU核心里面的Cache数据更新时,必须要传播到其他核心Cache,这个称为写传播(Write Propagation)
2. 某个CPU核心里对数据的操作顺序,必须在其他核心看起来顺序也是一样的,即事务的串行化(Transaction Serialization)
(3)事务的串行化
例子:4核CPU,i=0
* A核心:i=100
* B核心:i=200
A、B对i的修改传播到C、D
* C核心:看到先变100再变200
* D核心:看到先变200再变100
则不是串行化
怎么实现串行化:
1. CPU核心对于Cache中的数据操作,需要同步给其他CPU核心
2. 引入锁
(4)怎么实现写传播?
写传播的原则是当某个CPU核心更新了Cache中的数据,要把该事件广播通知到其他核心。通过总线嗅探(Bus Snooping)
总线嗅探工作机制:
当A号CPU核心修改了L1 Cache中的i变量的值,通过总线把这个事件广播通知给其他所有的核心,然后每个CPU核心都会监听总线上的广播事件,并检查是否有相同的数据在自己的L1 Cache里面
如果B号CPU核心的L1 Cache中有该数据,那么也需要把该数据更新
(5)MESI协议
基于总线嗅探机制的,是保障缓存一致性的协议。
(6)伪共享问题
1. 最开始变量A和B都不在Cache里面,假设1号核心绑定线程A,2号核心绑定线程B;线程A只会读写变量A,线程B只会读写变量B。
2. 1号核心读取变量A,由于变量A和B都属于同一Cache Line,所以变量A、B都被加载到Cache,并将此Cache Line标记为独占状态。
3. 2号核心读取变量B,现在两个核心读加载了该Cache Line,所以被标记为共享状态,
4. 1号核心要修改变量A,发现该Cache Line为共享,所以需要通过总线发送消息给2号核心,通知2号核心把Cache中对应的Cache Line标记为已失效状态,然后1号核心对应Cache Line状态变成已修改状态,并且修改变量A。
5. 2号核心要修改变量B,发现Cache中对应的Cache Line为已失效状态,另外1号核心的Cache也有相同的数据,且状态为已修改。
所以先把1号核心的Cache对应的Cache Line写回内存,然后2号核心再从内存读取Cache Line大小的数据到Cache中,最后把变量B修改到2号核心的Cache中,并将状态标记为已修改。
这种因为多个线程同时读写同一个Cache Line的不同变量时,而导致CPUCache失效的现象称为伪共享(False Sharing)。















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











