







0.引言
最原始的GAN发表在NIPS2014上,GAN的思想是非常有趣的,以前我们在设计网络的时候,都是利用一个目标函数来指导一个网络的训练。然而GAN利用两种目标函数来指导两个结构(生成器与判别器)的博弈对抗,让两者互相促进。
举个简单的对抗博弈进步的例子-假币与银行,在初期的时候,由于银行并没有认识到假币的存在,因此一些很简单的假币就可能会被银行误收;随着科技进步,开始有了水印 、紫外光辨别真伪,在这样的条件下,旧的假币就无法通过银行的检验了,但是旧的假币可以知道自己不能通过检验的原因在于水印等不合格,于是假币就在这些方面进行改进,以此想要继续骗过银行,因此银行和假币就处在不断地博弈进步之中 。
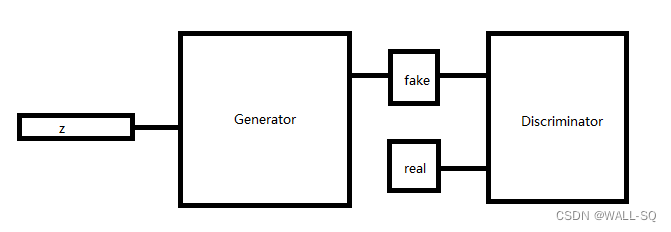
那么现在我们来看一下GAN的工作原理,实际上GAN网络分为两部分-生成器与判别器,生成器的目的就是造假,而判别器的目的就是判别真假,当生成器和判别器可以正确对抗博弈进化时,随着判别器越来越强,生成器也会越来越强,而做生成任务时,我们需要的就是生成器部分。
1.生成器
A.生成器的训练目标
生成器比较复杂,首先我们并不知道怎样做生成这件事,因为我们并不知道用什么去生成,对于传统的神经网络,我们知道输入和输出,而对于生成任务来说,我们希望生成器可以给我们和训练数据属于同种的数据,简单来说就是,如果我们给定的数据是海边风景照,那么我们希望生成器可以给我们生成海边风景照,但是海边风景照数量非常庞大,因为涉及的因素非常多,比如天气、沙滩状况、涨潮情况,稍微变动一点就是不同的数据了,所以我们不可能收集所有的海边风景照。
那么GAN是如何解决这个问题的呢,对于实际数据数量庞大而我们所拥有的数量有限问题,GAN的做法是从分布的角度去看待数据,即我们训练的GAN的目标不是直接生成数据,而是生成分布。那我们到底要怎么用GAN去拟合一个分布呢?并且输入应该是什么样子的呢?
B.生成器的输入
为了避免直接做拟合分布这个0->1的问题,GAN的做法是将另一个分布通过生成器映射为我们需要的目标分布,由于分布都是无限的,因此我们可以通过映射将一个分布转换为另一个分布。说到分布,常用的就是高斯、均匀等,一般的做法都是使用高斯分布。
现在我们确定了方案,即生成器的目标是将一个分布转换为目标分布。那么怎么做呢?假设我们要生成28*28*1的图像数据,我们将每一个点位置的数据视为从一个高斯分布中采样的数据,即通过高斯分布获得28*28*1的输入(称之为输入噪声),此时再通过网络对于采样得到的28*28*1进行转换,这看起来确实是一种方案,但实际上我们通常不会这么做,原因在于我们可能要生成很大的数据,假设我们要生成一个1024*1024的数据,如果我们在输入端的数据就这么大,那么整个网络是十分消耗资源的。我们通常的做法是采样出一个1*z_dim维度的向量,并且认为这个向量的含义是对目标生成数据的高级特征描述,简言之可以理解为肤色的深度、头发的浓密度等等。
C.生成器如何生成
现在我们确定了输入是一个向量,我们要怎么做到生成呢,首先必要的就是需要进行高级特征的解耦,这个过程是我们以前所做的分类网络的逆过程,我们将输入向量理解为分类网络在判别层之前的特征向量,那么为了获得图片,我们需要向浅层解耦,即将高级特征解耦为低级特征,所以首先要做的就是升维,之后的步骤就是利用得到的低级特征向量进行生成。
2.判别器
判别器的结构相对简单,主要进行判别真假的任务,可以参考在初学神经网络时候所写的分类网络,把分物体类别的问题转化为分物体是真实还是虚假的问题。
3.训练
A.损失函数
GAN如何训练的问题很大程度上取决于损失函数的设计,我们先梳理一下,对于判别器来说,目标是要判别出真实数据(判别为1)和判别数据(判别为0),生成器的目的是生成让判别器误判的数据。我们这里先规定一下符号,生成器用G表示,判别器用D表示,输入的采样向量用z表示,生成数据为G(z),真实数据用x表示。
对于判别器来说,希望判别真实数据的结果接近1,即D(x)->1,判别虚假数据的结果接近0,即D(G(z))->0,GAN设计的损失函数判别器部分如下:
对于生成器来说,希望判别器判别生成的结果接近1,即D(G(z))->1,GAN设计的损失函数生成器部分如下:
合在一起就是GAN论文中写的损失函数了:
B.训练策略
在GAN的训练中,有非常危险的问题就是博弈失败,我们知道判别器和生成器是互相促进的,但如果他们的训练不协调就会出现问题。
第一种情况:如果D的进化很快,D很容易区分生成数据与判别数据,那么此时训练D使用的损失函数值就很快接近最小值,梯度也急剧变小,由于G的梯度求解是依赖D的梯度的,当D的梯度很小的时候G的梯度也会变得很小,也就是G无法进化。
第二种情况:如果G的进化很快,G很快就可以欺骗过判别器,此时判别器无法区分真实数据与生成数据,也就不能提供梯度信息,导致G无法再进化,但是G可能并没有进化的很好。
因此如何平衡生成器和判别器的训练是很重要的。
4.代码
import torch
from torch import nn, autograd, optim
import numpy as np
import visdom
import random
import matplotlib.pyplot as plt
h_dim = 400
bs = 512
viz = visdom.Visdom()
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.net = nn.Sequential(
nn.Linear(2, h_dim),
nn.ReLU(True),
nn.Linear(h_dim, h_dim),
nn.ReLU(True),
nn.Linear(h_dim, h_dim),
nn.ReLU(True),
nn.Linear(h_dim, 2),
)
def forward(self, z):
output = self.net(z)
return output
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.net = nn.Sequential(
nn.Linear(2, h_dim),
nn.ReLU(True),
nn.Linear(h_dim, h_dim),
nn.ReLU(True),
nn.Linear(h_dim, h_dim),
nn.ReLU(True),
nn.Linear(h_dim, 1),
nn.Sigmoid()
)
def forward(self, x):
output = self.net(x)
return output.view(-1)
def data_generator():
scale = 2
centers = [
(1, 0),
(-1, 0),
(0, 1),
(0, -1),
(1. / np.sqrt(2), 1. / np.sqrt(2)),
(1. / np.sqrt(2), -1. / np.sqrt(2)),
(-1. / np.sqrt(2), 1. / np.sqrt(2)),
(-1. / np.sqrt(2), -1. / np.sqrt(2)),
]
centers = [(scale * x, scale * y) for x, y in centers]
while True:
dataset = []
for i in range(bs):
point = np.random.randn(2) * 0.02
center = random.choice(centers)
point[0] += center[0]
point[1] += center[1]
dataset.append(point)
dataset = np.array(dataset).astype(np.float32)
dataset /= 1.414
yield dataset
def main():
torch.manual_seed(23)
np.random.seed(23)
data_iter = data_generator()
x = next(data_iter)
G = Generator().cuda()
D = Discriminator().cuda()
optim_G = optim.Adam(G.parameters(), lr=5e-4, betas=(0.5, 0.9))
optim_D = optim.Adam(D.parameters(), lr=5e-4, betas=(0.5, 0.9))
viz.line([[0, 0]], [0], win='loss', opts=dict(title='loss',legend=['D', 'G']))
for epoch in range(50000):
for _ in range(5):
xr = next(data_iter)
xr = torch.from_numpy(xr).cuda()
predr = D(xr)
# max predr, min lossr, min -predr
lossr = -predr.mean()
z = torch.randn(bs, 2).cuda()
xf = G(z).detach()
predf = D(xf).requires_grad_()
lossf = predf.mean()
loss_D = lossr + lossf
optim_D.zero_grad()
loss_D.backward()
optim_D.step()
z = torch.randn(bs, 2).cuda()
xf = G(z)
predf = D(xf)
# max predf
loss_G = -predf.mean()
optim_G.zero_grad()
loss_G.backward()
optim_G.step()
if epoch % 100 == 0:
viz.line([[loss_D.item(), loss_G.item()]], [epoch], win='loss', update='append')
print(loss_D.item(), loss_G.item())
generate_image(D, G, xr.cpu().numpy(), epoch)
def generate_image(D, G, xr, epoch):
N_POINTS = 128
RANGE = 3
plt.clf()
points = np.zeros((N_POINTS, N_POINTS, 2), dtype="float32")
points[:, :, 0] = np.linspace(-RANGE, RANGE, N_POINTS)[:, None]
points[:, :, 1] = np.linspace(-RANGE, RANGE, N_POINTS)[None, :]
points = points.reshape((-1, 2))
with torch.no_grad():
points = torch.Tensor(points).cuda()
disc_map = D(points).cpu().numpy()
x = y = np.linspace(-RANGE, RANGE, N_POINTS)
cs = plt.contour(x, y, disc_map.reshape((len(x), len(y))).transpose())
plt.clabel(cs, inline=1, fontsize=10)
with torch.no_grad():
z = torch.randn(bs, 2).cuda()
samples = G(z).cpu().numpy()
plt.scatter(xr[:, 0], xr[:, 1], c='orange', marker='.')
plt.scatter(samples[:, 0], samples[:, 1], c='green', marker='+')
viz.matplot(plt, win='contour', opts=dict(title='p(x):%d'%epoch))
if __name__ == '__main__':
main()














 593
593











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









