









1:什么是决策树
1.2官话:
决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构建决策树来进行分析的一种方式,是一种直观应用概率分析的一种图解法
1.2通俗
通过一个案例来解释吧,下图是一张用户是否能进行债务偿还的表格,按照我平时的习惯,我们脑子里会有一个类似重要度的东西,比如他年收入高就比年收入低更容易还清贷款,已婚就比单身更容易还清,有房就不没房更容易还清,但这只是大概,基于习惯得出的结果,所以我们就需要将这个结果代码化,流程化,可解释化,这大致就是我认为的决策树

决策树基础算法主要有三类,分别为ID3,C4,5,CART,下表为他们的大致区别,我将分别讲解每一类的推导以及优缺点。

ID3
ID3算法是决策树的一个经典的构造算法,内部使用信息熵以及信息增益来进行构建;每次迭代选择信息增益最大的特征属性作为分割属性
信息熵
信息熵:1948年,香农引入信息熵;一个系统越是有序,信息熵就越低,一个系统越是混乱,信息熵就越高,所以信息熵被认为是一个系统有序程度的度量,信息熵就是用来描述系统信息量的不确定度。
H(X)就叫做随机变量X的信息熵
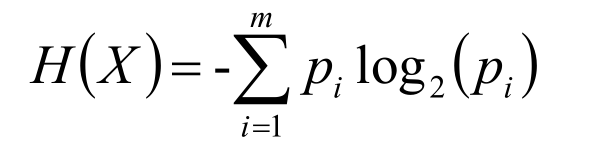
信息增益
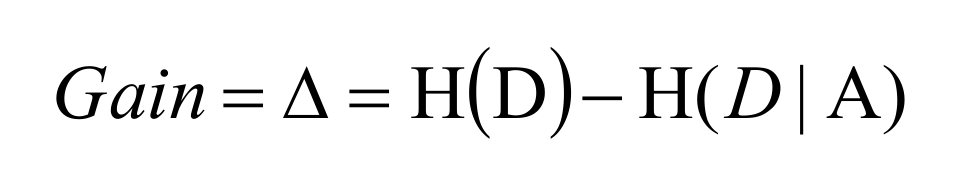
这样只是一个公式,更本不知道怎么计算,所以,我们在上个案例的基础上看怎么解决这个问题,以及和我们预想的有什么区别
我们先算出![]()

这个式子理解为,我们的目标变量是无法偿还债务,这里有两个值是占有3/10.否占7/10.所以我们列出这个式子,接下来看拥有房产这个特征,我们列出式子为

![]() 理解为有房产这个特征对应的能否偿还债务有四个样本,不能偿还的的概率4/4.能偿还的概率为0
理解为有房产这个特征对应的能否偿还债务有四个样本,不能偿还的的概率4/4.能偿还的概率为0
![]() 理解为无房产这个特征对应的能否偿还债务有四个样本,不能偿还的的概率是3/6.能偿还的概率为3/6
理解为无房产这个特征对应的能否偿还债务有四个样本,不能偿还的的概率是3/6.能偿还的概率为3/6
最后总的减去各自的得到信息增益,以此类推,得出

收入是最重要的,以此为房产,婚姻,在这个途中,收入是连续性变量,故要定义一个阈值进行分割,变成离散型变量

优点:
决策树构建速度快;实现简单;
缺点:
计算依赖于特征数目较多的特征,而属性值最多的属性并不一定最优
ID3算法不是递增算法
ID3算法是单变量决策树,对于特征属性之间的关系不会考虑
抗噪性差
只适合小规模数据集,需要将数据放到内存中
C4.5算法
在ID3算法的基础上,进行算法优化提出的一种算法(C4.5);现在C4.5已经是特别经典的一种决策树构造算法;使用信息增益率来取代ID3算法中的信息增益,在树的构造过程中会进行剪枝操作进行优化;能够自动完成对连续属性的离散化处理;C4.5算法在选中分割属性的时候选择信息增益率最大的属性,涉及到的公式为:

优点:
产生的规则易于理解
准确率较高
实现简单
缺点:
对数据集需要进行多次顺序扫描和排序,所以效率较低
只适合小规模数据集,需要将数据放到内存中
CART算法
使用基尼系数作为数据纯度的量化指标来构建的决策树算法就叫做CART(Classification And Regression Tree,分类回归树)算法。CART算法使用GINI增益作为分割属性选择的标准,选择GINI增益最大的作为当前数据集的分割属性;可用于分类和回归两类问题。CART构建是二叉树。

ID3和C4.5算法均只适合在小规模数据集上使用
ID3和C4.5算法都是单变量决策树
当属性值取值比较多的时候,最好考虑C4.5算法,ID3得出的效果会比较差
决策树分类一般情况只适合小数据量的情况(数据可以放内存)
CART算法是三种算法中最常用的一种决策树构建算法。
三种算法的区别仅仅只是对于当前树的评价标准不同而已,ID3使用信息增益、
C4.5使用信息增益率、CART使用基尼系数。
CART算法构建的一定是二叉树,ID3和C4.5构建的不一定是二叉树。
有问题加QQ2681707763















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









