







微积分
SGD,Momentum,Adagard,Adam原理
SGD为随机梯度下降,每一次迭代计算数据集的mini-batch的梯度,然后对参数进行跟新。
Momentum参考了物理中动量的概念,前几次的梯度也会参与到当前的计算中,但是前几轮的梯度叠加在当前计算中会有一定的衰减。
Adagard在训练的过程中可以自动变更学习的速率,设置一个全局的学习率,而实际的学习率与以往的参数模和的开方成反比。
Adam利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率,在经过偏置的校正后,每一次迭代后的学习率都有个确定的范围,使得参数较为平稳。
L1不可导的时候该怎么办
当损失函数不可导,梯度下降不再有效,可以使用坐标轴下降法,梯度下降是沿着当前点的负梯度方向进行参数更新,而坐标轴下降法是沿着坐标轴的方向,假设有m个特征个数,坐标轴下降法进参数更新的时候,先固定m-1个值,然后再求另外一个的局部最优解,从而避免损失函数不可导问题。
使用Proximal Algorithm对L1进行求解,此方法是去优化损失函数上界结果。
sigmoid函数特性
定义域为

值域为(-1,1)
函数在定义域内为连续和光滑的函数
处处可导,导数为

一个活动,n个女生手里拿着长短不一的玫瑰花,无序的排成一排,一个男生从头走到尾,试图拿更长的玫瑰花,一旦拿了一朵就不能再拿其他的,错过了就不能回头,问最好的策略?
选择的策略为不选取前r-1个女生,只从剩下的n-r+1个女生开始选取,若任何一个女生比之前的女生玫瑰花都长则选取这个女生,假设从第r个女生开始选,则第k个被选中的女生拥有最长玫瑰花的概率为:




当第r个为玫瑰最长的女生,那么她被选中概率比第r+1个女生大,则

即

因

所以

在此策略下,玫瑰最长女生被选中概率为0.368
某大公司有这么一个规定:只要有一个员工过生日,当天所有员工全部放假一天。但在其余时候,所有员工都没有假期,必须正常上班。这个公司需要雇用多少员工,才能让公司一年内所有员工的总工作时间期望值最大?
假设一年有365 天,每个员工的生日都概率均等地分布在这 365 天里。
E=n * (1-1/365)^n
n=365
切比雪夫不等式
![]()
一根绳子,随机截成3段,可以组成一个三角形的概率有多大
设绳子长为a,折成三段的长度为x,y,a-x-y从而得到



最大似然估计和最大后验概率的区别?
最大似然估计提供了一种给定观察数据来评估模型参数的方法,而最大似然估计中的采样满足所有采样都是独立同分布的假设。最大后验概率是根据经验数据获难以观察量的点估计,与最大似然估计最大的不同是最大后验概率融入了要估计量的先验分布在其中,所以最大后验概率可以看做规则化的最大似然估计。
什么是共轭先验分布
假设





概率和似然的区别
概率是指在给定参数

频率学派和贝叶斯学派的区别
频率派认为抽样是无限的,在无限的抽样中,对于决策的规则可以很精确。贝叶斯派认为世界无时无刻不在改变,未知的变量和事件都有一定的概率,即后验概率是先验概率的修正。频率派认为模型参数是固定的,一个模型在无数次抽样后,参数是不变的。而贝叶斯学派认为数据才是固定的而参数并不是。频率派认为模型不存在先验而贝叶斯派认为模型存在先验。
0~1均匀分布的随机器如何变化成均值为0,方差为1的随机器
0~1的均匀分布是均值为1/2,方差为0.转成均值为0,方差为1.概率论题目
Lasso的损失函数

Sfit特征提取和匹配的具体步骤
生成高斯差分金字塔,尺度空间构建,空间极值点检测,稳定关键点的精确定位,稳定关键点方向信息分配,关键点描述,特征点匹配
求m*k矩阵A和n*k矩阵的欧几里得距离?
先得到矩阵




欧拉公式
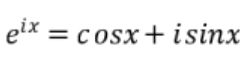
矩阵正定性的判断,Hessian矩阵正定性在梯度下降中的应用
若矩阵所有特征值均不小于0,则判定为半正定。若矩阵所有特征值均大于0,则判定为正定。在判断优化算法的可行性时Hessian矩阵的正定性起到了很大的作用,若Hessian正定,则函数的二阶偏导恒大于0,函数的变化率处于递增状态,在牛顿法等梯度下降的方法中,Hessian矩阵的正定性可以很容易的判断函数是否可收敛到局部或全局最优解。
概率题:抽蓝球红球,蓝结束红放回继续,平均结束游戏抽取次数
根据红球和蓝球的个数,依据概率公式,求出平均抽取次数。
PCA
PCA是比较常见的线性降维方法,通过线性投影将高维数据映射到低维数据中,所期望的是在投影的维度上,新特征自身的方差尽量大,方差越大特征越有效,尽量使产生的新特征间的相关性越小。
PCA算法的具体操作为对所有的样本进行中心化操作,计算样本的协方差矩阵,然后对协方差矩阵做特征值分解,取最大的n个特征值对应的特征向量构造投影矩阵。
拟牛顿法的原理
牛顿法的收敛速度快,迭代次数少,但是Hessian矩阵很稠密时,每次迭代的计算量很大,随着数据规模增大,Hessian矩阵也会变大,需要更多的存储空间以及计算量。拟牛顿法就是在牛顿法的基础上引入了Hessian矩阵的近似矩阵,避免了每次都计算Hessian矩阵的逆,在拟牛顿法中,用Hessian矩阵的逆矩阵来代替Hessian矩阵,虽然不能像牛顿法那样保证最优化的方向,但其逆矩阵始终是正定的,因此算法始终朝最优化的方向搜索。
编辑距离
概念
编辑距离的作用主要是用来比较两个字符串的相似度的
编辑距离,又称Levenshtein距离(莱文斯坦距离也叫做Edit Distance),是指两个字串之间,由一个转成另一个所需的最少编辑操作次数,如果它们的距离越大,说明它们越是不同。许可的编辑操作包括将一个字符替换成另一个字符,插入一个字符,删除一个字符。
在概念中,我们可以看出一些重点那就是,编辑操作只有三种。插入,删除,替换这三种操作,我们有两个字符串,将其中一个字符串经过上面的这三种操作之后,得到两个完全相同的字符串付出的代价是什么就是我们要讨论和计算的。
例如:
我们有两个字符串:kitten 和 sitting:
现在我们要将kitten转换成sitting
我们可以做如下的一些操作;
kitten–>sitten 将K替换成S sitten–> sittin 将e替换成i
sittin–> sitting 添加g
在这里我们设置每经过一次编辑,也就是变化(插入,删除,替换)我们花费的代价都是1。
例如:
如果str1=”ivan”,str2=”ivan”,那么经过计算后等于 0。没有经过转换。相似度=1-0/Math.Max(str1.length,str2.length)=1
如果str1=”ivan1”,str2=”ivan2”,那么经过计算后等于1。str1的”1”转换”2”,转换了一个字符,所以距离是1,相似度=1-1/Math.Max(str1.length,str2.length)=0.8
算法过程
1.str1或str2的长度为0返回另一个字符串的长度。 if(str1.length==0) return str2.length; if(str2.length==0) return str1.length;
2.初始化(n+1)*(m+1)的矩阵d,并让第一行和列的值从0开始增长。扫描两字符串(n*m级的),如果:str1[i] == str2[j],用temp记录它,为0。否则temp记为1。然后在矩阵d[i,j]赋于d[i-1,j]+1 、d[i,j-1]+1、d[i-1,j-1]+temp三者的最小值。
3.扫描完后,返回矩阵的最后一个值d[n][m]即是它们的距离。
计算相似度公式:1-它们的距离/两个字符串长度的最大值。
我们用字符串“ivan1”和“ivan2”举例来看看矩阵中值的状况:
1、第一行和第一列的值从0开始增长

图一
首先我们先创建一个矩阵,或者说是我们的二维数列,假设有两个字符串,我们的字符串的长度分别是m和n,那么,我们矩阵的维度就应该是(m+1)*(n+1).
注意,我们先给数列的第一行第一列赋值,从0开始递增赋值。我们就得到了图一的这个样子
之后我们计算第一列,第二列,依次类推,算完整个矩阵。
我们的计算规则就是:
d[i,j]=min(d[i-1,j]+1 、d[i,j-1]+1、d[i-1,j-1]+temp) 这三个当中的最小值。
其中:str1[i] == str2[j],用temp记录它,为0。否则temp记为1
我们用d[i-1,j]+1表示增加操作
d[i,j-1]+1 表示我们的删除操作
d[i-1,j-1]+temp表示我们的替换操作
2、举证元素的产生 Matrix[i - 1, j] + 1 ; Matrix[i, j - 1] + 1 ; Matrix[i - 1, j - 1] + t 三者当中的最小值

3.依次类推直到矩阵全部生成


这个就得到了我们的整个完整的矩阵。















 6194
6194











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









