







论文链接:https://arxiv.org/pdf/2001.07676.pdf
时间:2021年1月
特点:多模板

背景
- 在小样本场景下传统监督学习效果很差,于是提出了模型PET(Pattern-Exploiting Training)它是一种半监督训练过程,使用自然语言模板将输入的示例重新组织成完形风格的短语。
符号定义:
- 有标注小样本数据集:T
- 无标注大型数据集:D
- 语言模型:M
- 词表:V
- 掩码标记:___
- 分类任务:A
- 标签:L
- 输入:短语序列 x = (s1, . . . , sk)
模型
在详细介绍模型之前需要先介绍一个概念 PVP
PVP定义
Pattern-Verbalizer-Pair
- 定义函数P(pattern):输入x,输出包含掩码标记的句子或短语,使得输出可以被看作是一个完形填空问题。可以理解为“模板构造”。输入x=“Best pizza ever!” P(x)="Best pizza ever! It was___.”
- 映射V(verbalizer):将PLM预测标签映射为词表中的一个单词。比如预测结果为负向标签0,继续将0映射为单词“bad”,可以理解为“答案映射”的逆过程。
在学习prompt的过程中,最后一步答案映射是将预测词映射为标签词,这里的verbalizer是逆过程,对于两者的区别,我的理解是verbalizer侧重于训练过程,答案映射侧重于预测过程。
通过之前对prompt的学习我们知道,模板构造,答案映射,是prompt-tunning中非常关键的两个环节。对于同一个任务,可以设计不同的模板,也可以设计不同的答案映射器,这会带来不同的效果。因此需要进一步讨论组合PVP的概念。
组合PVP
- 在缺乏大型数据集的情况下,很难确定哪些PVP表现良好,定义了一组PVP来处理任务。
针对不同的分类任务以及数据集,论文提出了多种建议的PVP组合,下文仅以情感分类任务为例继续介绍。
P:

对于情感分类,论文提出了四种建议的模板。以P3为例,假设输入a=“Best pizza ever”, 构造的模板P3(a)=“Best pizza ever.All in all, it was__”。
V:
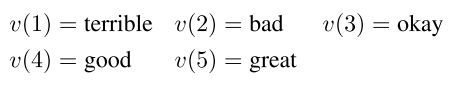
标签1映射为单词terrible,标签2映射为单词bad
从上面这个例子也能看出来,PET中模板以及映射都是手工创建的,特殊的是有多个PVP组成PVPs,也就是在综述论文中提到的多模板组合。
结构
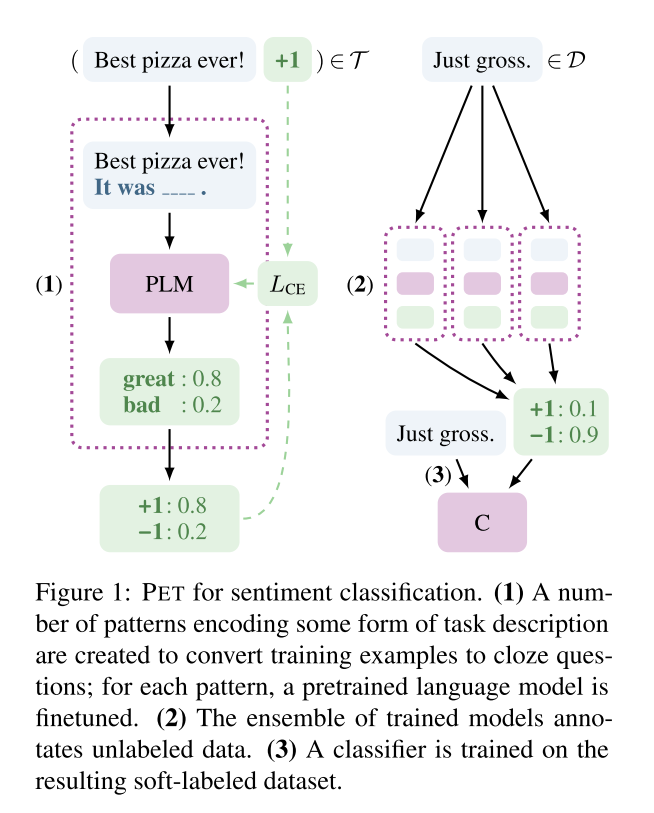
- 第(1)步:每一个单独的PLM在小样本数据集T上进行精调。
- 第(2)步:使用所有PLM的集合对大型无标注数据集D进行软标签标注
- 第(3)步:在具有软标签的数据集上训练标准分类器C
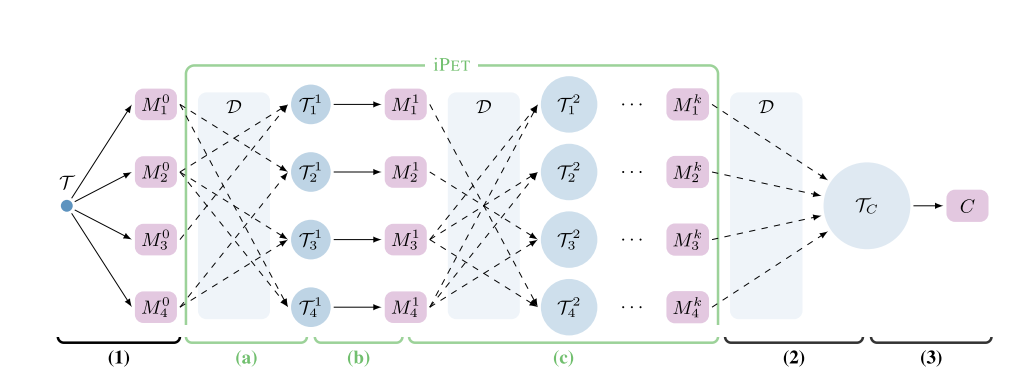
为了达到更好的效果,进一步提出了iPET,上图中123为PET结构,123abc为iPET结构
- iPET的核心思想是在不断增大的数据集上迭代训练模型
- 第(a)步:在第一轮PET模型训练完成之后,随机组合若干个为数据集D打标签,每个类中挑选得分最高的样本合并到小样本数据集中,形成较大的数据集。
- 第(b)步:在扩大后的数据集上再一次训练PET模型
- 第(c)步:将这个过程迭代多次
实验
- 数据集:Yelp Reviews, AG’s News, Yahoo Questions,MNLI ,X-Stance(使用x-stance 来研究PET在其他语言中的效果)
- 语言模型:英文实验(RoBERTa large),x-stance(XLM-R)
- 试验任务:情感分类,主题分类,答案匹配,句子匹配
英文数据集精度与方差:
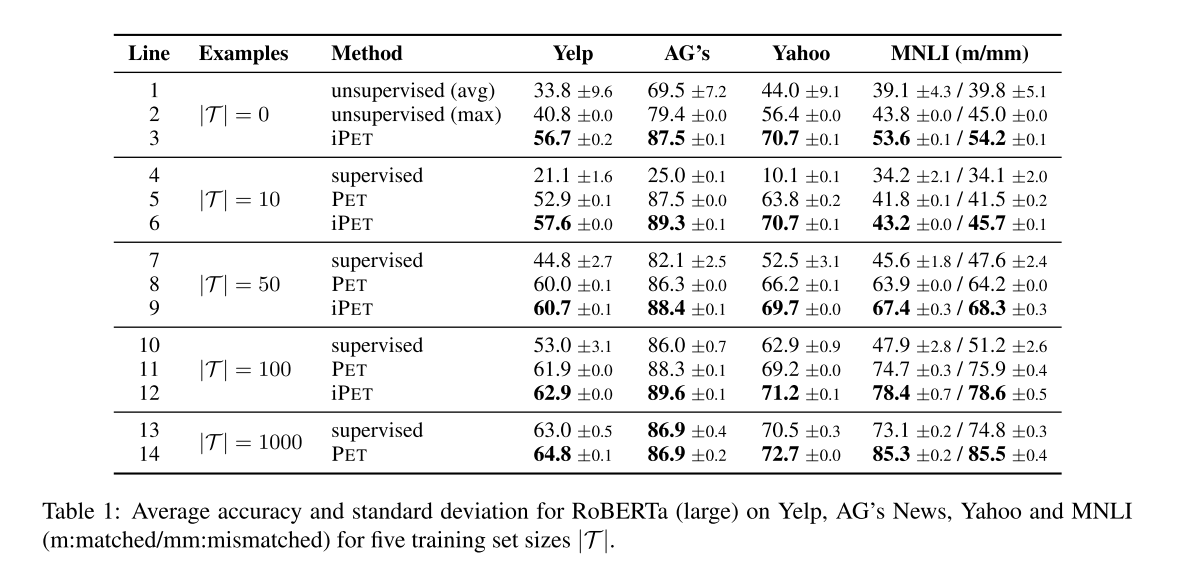
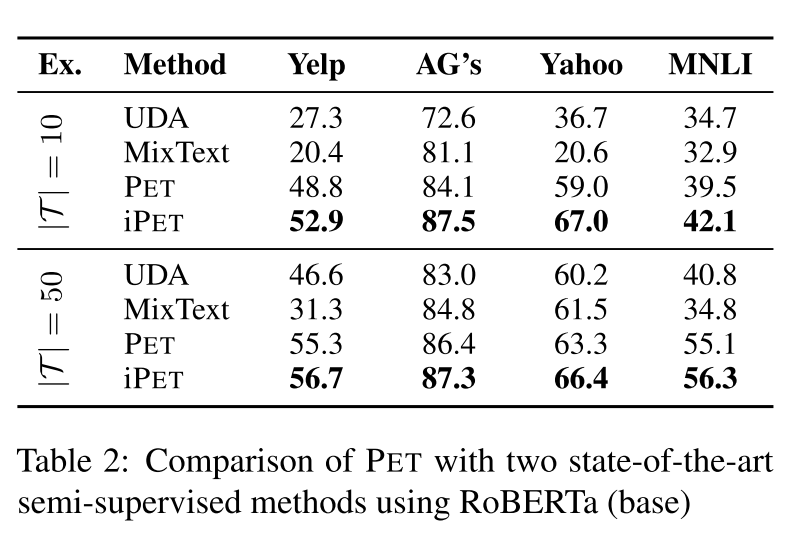
无论小样本数据集为多大,iPET都能达到SOTA。
与baseline的比较:



















 371
371

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











