



 文章探讨了Transformer中多头注意力机制的作用,解释了为何它能学习不同维度的信息,以及QKV矩阵的生成和自注意力计算原理。还讨论了多头机制如何增强模型表达能力和计算效率,并简要介绍了Transformerencoder的结构。
文章探讨了Transformer中多头注意力机制的作用,解释了为何它能学习不同维度的信息,以及QKV矩阵的生成和自注意力计算原理。还讨论了多头机制如何增强模型表达能力和计算效率,并简要介绍了Transformerencoder的结构。
Transformer为什么使用多头注意力机制呢?
多头可以学习到不同维度的特征和信息。为什么可以学习到不同维度的信息呢?
答案是:多头注意力机制的组成是有单个的self attention,由于self attention通过产生QKV矩阵来学习数据特征,那每一个self attention最终会产生一个维度上的输出特征,所以当使用多头注意力机制的时候,模型就可以学习到多维度的特征信息,这使得模型可以从多个维度更好的理解数据。同时多头注意力机制还是并行计算的,这也符合现在硬件架构,提升计算效率。详细说明请看下文。
首先,要明确的是multi head attention的组成是单个的self attention。我们先理解self attention的计算过程。
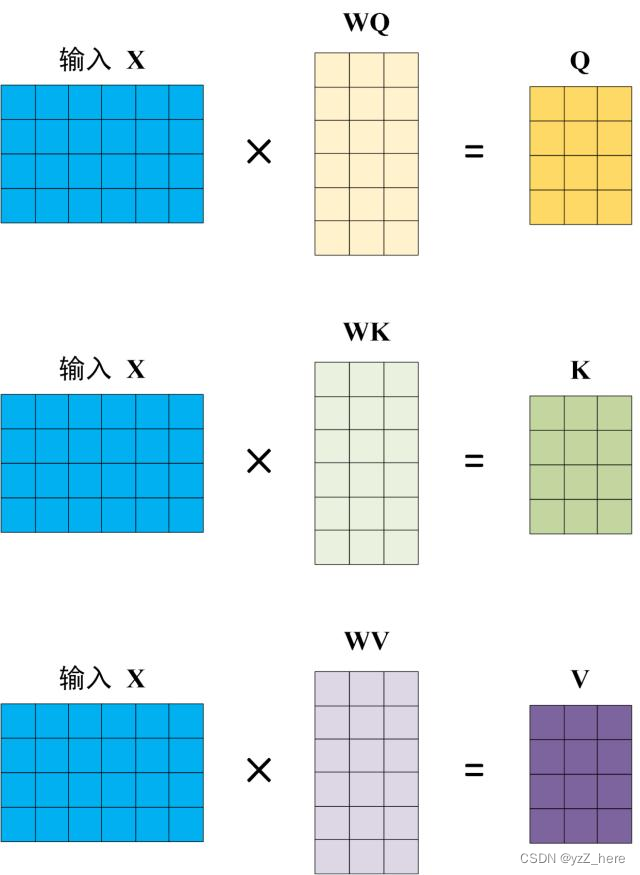
self attention的计算如左下图所示:其中QKV的来源是将输入X进行线性变换,产生三个不同的权重矩阵,如右下图所示,然后这三个矩阵依次和输入x做矩阵点乘运算得到了QKV,
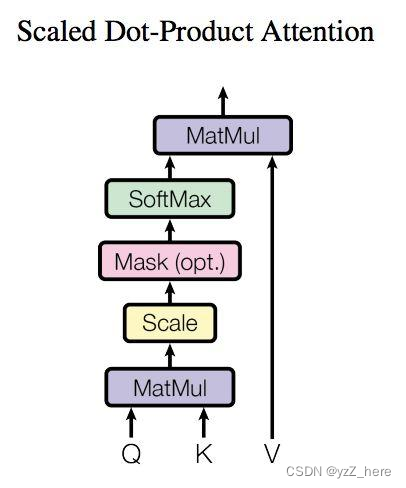
最后通过下面这个式子的可以得到self attention的输出,我们可以将其理解为一个维度上的特征信息。

而多头注意力机制的如下图,允许模型从不同的子空间关注多个不同的位置(上图中的QKV的来源文件中矩阵是生成了,可学习的,)从而捕捉不同级别的特征和信息,使得每个头可以学习到不同的关系,这使得模型可以从不同的角度理解数据。
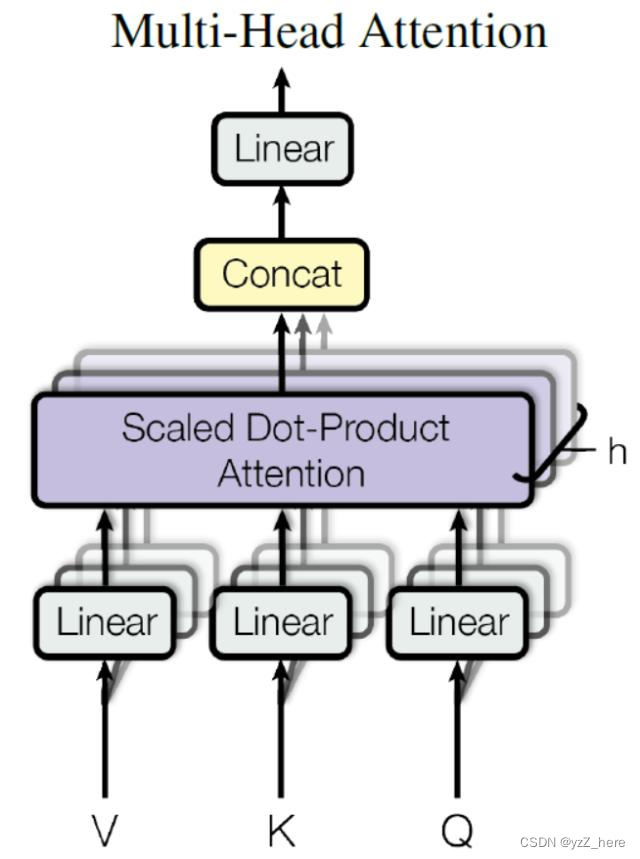
几个问题:
1、Q和K为什么使用不同的权重矩阵生成?为什么不能使用同一个值进行自身的点乘运算?
回答:1)使用不同的权重举证可以增加模型的表达能力,不同的权重矩阵允许模型在不同的空间中学习和匹配不同的特征。2)不同的权重矩阵可以使模型更好的参数化,学习到更多的信息而不是仅仅依赖一个权重矩阵。
2、self attention中为什么是点乘而不是add?二者复杂度上有什么区别?
回答:点乘注意力通常在实践中表现更好,可能是因为计算简单和高效。点乘复杂度为O(d*n^2)其中d是特征维度,n是序列长度。
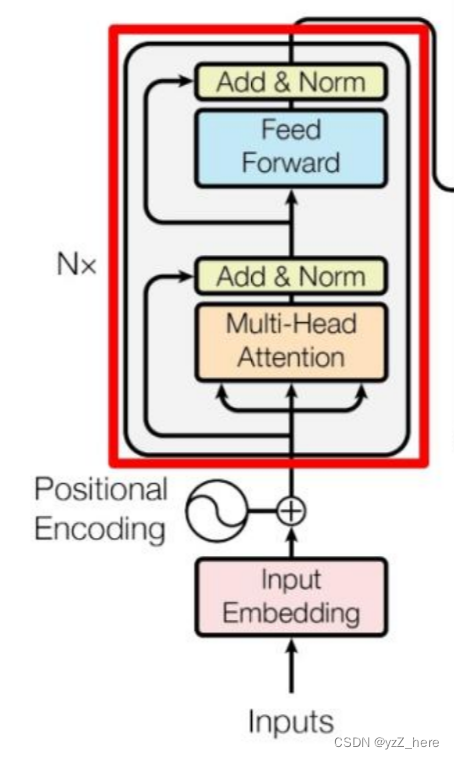
3、transformer的encoder结构
回答:encoder由多个相同的block组成,如下图所示,每个block中包含由两个模块,multi head attention和feed forward模块。每个模块中都含有一个残差连接和归一化层。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









