






1 论文简介
该论文提供了一个较为通用的框架,只要是风格转移等类似于图像上的色彩有不同的域的转换,使用论文提供的框架都会有很好的效果
2 论文的贡献
1,突破以往训练的训练集必须使用对齐图像的局限性
2,提供了非常好的框架进行图像域的迁移学习
3,新颖的网络结构以及损失函数
3 数据集
该论文的数据集并不需要两张能够按照像素对齐的图像对,只需要按照自己的需求(艺术目的等)进行训练即可
4 网络结构(及loss函数都是从代码方面看的)
首先看一下论文使用残差块(由卷积层和批量标准化归一层交迭组成)
class ResidualBlock(nn.Module):
def __init__(self, in_features):
super(ResidualBlock, self).__init__()
self.block = nn.Sequential(
nn.ReflectionPad2d(1),
nn.Conv2d(in_features, in_features, 3),
nn.InstanceNorm2d(in_features),
nn.ReLU(inplace=True),
nn.ReflectionPad2d(1),
nn.Conv2d(in_features, in_features, 3),
nn.InstanceNorm2d(in_features),
)
def forward(self, x):
return x + self.block(x)
生成网络–generator
生成网络大体由 初始化的卷积层—下采样—残差网络–上采样 这四部分一次构成
下面依次给出各部分的详细代码
首先是初始化的卷积层
model = [
nn.ReflectionPad2d(channels),
nn.Conv2d(channels, out_features, 7),
nn.InstanceNorm2d(out_features),
nn.ReLU(inplace=True),
]
然后是两次下采样
for _ in range(2):
out_features *= 2
model += [
nn.Conv2d(in_features, out_features, 3, stride=2, padding=1),
nn.InstanceNorm2d(out_features),
nn.ReLU(inplace=True),
]
接着按照需求进行残差学习
for _ in range(num_residual_blocks):
model += [ResidualBlock(out_features)]
进行两次上采样
for _ in range(2):
#//返回不大于结果的一个最大的整数
out_features //= 2
model += [
nn.Upsample(scale_factor=2),
nn.Conv2d(in_features, out_features, 3, stride=1, padding=1),
nn.InstanceNorm2d(out_features),
nn.ReLU(inplace=True),
]
输出卷积层
model += [nn.ReflectionPad2d(channels), nn.Conv2d(out_features, channels, 7), nn.Tanh()]
这就是生成网络了
鉴别网络–Discriminator
鉴别块由卷积层和归一化层交迭组成
def discriminator_block(in_filters, out_filters, normalize=True):
layers = [nn.Conv2d(in_filters, out_filters, 4, stride=2, padding=1)]
if normalize:
layers.append(nn.InstanceNorm2d(out_filters))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
鉴别器由四个鉴别块和一个卷积层组成
self.model = nn.Sequential(
*discriminator_block(channels, 64, normalize=False),
*discriminator_block(64, 128),
*discriminator_block(128, 256),
*discriminator_block(256, 512),
nn.ZeroPad2d((1, 0, 1, 0)),
nn.Conv2d(512, 1, 4, padding=1)
)
5 loss函数
文章中的loss 叙述的我有些不理解,这里我将我理解的代码中的思想说一下,这里的AB是若有像素对其的图片则为其图片对,没有则是目标图像数据和源数据集的随机一张
(1)生成网络的loss
设有两个生成器G_AB,G_BA(两个解码器构造完全一样), 将可以不按照像素对齐的两张图片分别设A ,B
第一部分的loss函数设计是这样的,在generator之后即计算损失
A 通过 G_BA得到了A的生成图像resNet_A
B通过 G_AB得到了B的生成图像resNet_B
将(A,resNet_A)进行loss,记为loss_i_A
将(B,resNet_B)进行loss,记为loss_i_B
loss_identidine = (loss_i_A+loss_i_B)/2
这称为Identity loss
第二部分的GAN_loss函数是这样的:
A通过G_AB生成B的假象为fake_B,fake_B通过D_B和大小相同的全1矩阵比较loss,记loss_gan_A
B通过G_BA生成A的假象为fake_A,fake_A通过D_A和大小相同的全1矩阵比较loss,记loss_gan_B
GAN_loss = (loss_gan_A+loss_gan_B)/2
第三部分的循环一致性Cycle_loss是这样的:这里的循环一致性loss指的是
A通过残差网络生成了fake_B,fake_B又通过残差网络生成了recov_A,A与recov_A理想情况下应该差别不大
这个过程可以表示为 A–>fake_B—>recov_A(与A相似)
在第二部分得到fake_B,fake_A之后
fake_B通过G_BA生成recov_A,recov_A与原始A做loss设为cross_loss_A
fake_A通过G_AB生成recov_B,recov_B与原始B做loss设为cross_loss_B
Cycle_loss = (cross_loss_A+cross_loss_B)/2
总loss :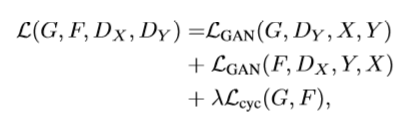
但是实现的时候是这样的:
loss_G = loss_GAN +权重1 * loss_cycle + 权重2 * loss_identity
这就是生成网络的loss计算方法
(2)鉴别网络的loss
两个鉴别器D_A ,D_B都使用相似的loss
首先将A通过D_A与相同大小的全1矩阵计算loss记为loss_a
再将上面的fake_A放入缓冲区,将五十张图片按照维度排列好,一起与相同大小的全0矩阵计算loss,记为loss_b
loss = (loss_b+loss_a)/2
6 实验结果说明
论文通过与多种方法进行了多种维度的对比,这里不再细说















 2123
2123











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









