







 本文综述了视觉关系检测和场景图生成的关键技术,包括开山之作Visual Relationship Detection with Language Priors,以及后续发展如Scene Graph Generation by Iterative Message Passing、Neural Motifs等。介绍了基于图像的目标检测、关系预测、上下文融合等核心步骤,以及如何利用深度学习模型如CNN、RNN、LSTM等进行特征提取和关系推理。
本文综述了视觉关系检测和场景图生成的关键技术,包括开山之作Visual Relationship Detection with Language Priors,以及后续发展如Scene Graph Generation by Iterative Message Passing、Neural Motifs等。介绍了基于图像的目标检测、关系预测、上下文融合等核心步骤,以及如何利用深度学习模型如CNN、RNN、LSTM等进行特征提取和关系推理。
Scene Graph
简而言之,视觉关系识别/检测任务不仅需要识别出图像中的物体以及他们的位置,还要识别物体之间的关系,即目标物体之间的联系,可以表示为一个三元组Triplet——Relationship: <object1 - predicate - object2>
主要相关的任务有三种:Predicate classification,只需要预测关系。Scene graph classification需要得到对象和关系。Scene graph detection/gen还要定位到框box的对象和关系。
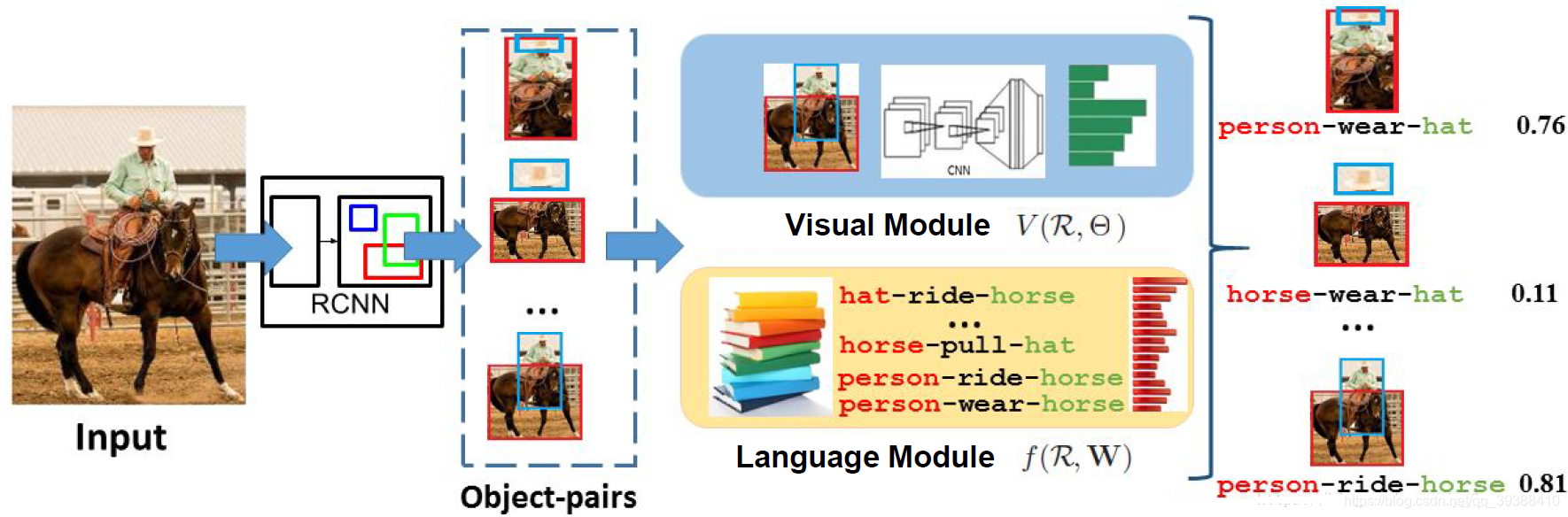
Visual Relationship Detection with Language Priors
ECCV2016,开山之作,公开了一个数据集VRD,包含5000张图片,6000多个关系,平均每个对象有24个关系谓词。其他相关数据集:Scene graph,VIsual phrases,VIsual Genome。
处理方法主要是:
- 先对图像用RCNN等目标检测算法得到一些目标,构成目标对
- 再分别经过一个视觉模型和一个语言模型。视觉模型是用CNN提取object-pair联合的box的特征,再结合他们的类似然度得到关系元组的视觉似然度。语言模型是将目标对的word词向量映射到一个embedding space,其中嵌入空间k是谓词数量,所以能得到两个目标对象间的关系的语言上的似然度。
- 最后两者相乘得到最后的关系三元组似然度可能性,就是预测的结果。<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1132
1132

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









