







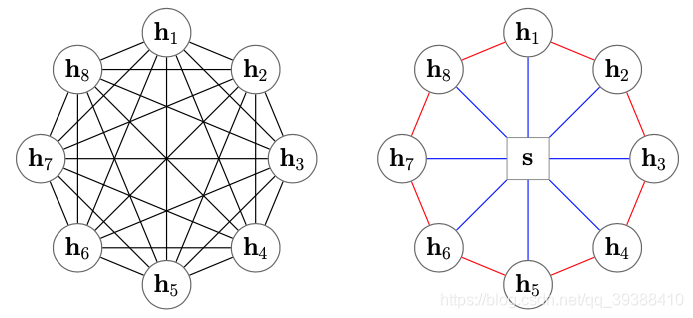
Star-Transformer
来自NAACL 2019的论文。
问题:
- Transformer的自注意力机制每次都要计算所有词之间的注意力,其计算复杂度为输入长度的平方,结构很重
- 在语言序列中相邻的词往往本身就会有较强的相关性,似乎本来就不需要计算所有词之间
解决:
Star-Transformer用星型拓扑结构代替了全连通结构如上图左边是Transformer,而右边是Star-Transformer。在右边的图中,所有序列中直接相邻的词可以直接相互作用,而非直接相邻的元素则通过中心节点实现间接得信息传递,因此,复杂性从二次降低到线性,同时保留捕获局部成分和长期依赖关系的能力。
- Radical connections, 捕捉非局部信息。即每两个不相邻的卫星节点都是两跳邻居,可以通过两步更新接收非局部信息。
- Ring connections, 捕捉局部信息。 由于文本输入是一个序列,相邻词相连以捕捉局部成分之间的关系。值得注意的是它第一个节点和最后一个节点也连接起来,形成环形连接。
具体实现算法如下:

- 在初始化阶段,卫星节点(周围的词节点)的初始值为各自相应的词向量 e 1 . . . . e n e_1....e_n e1....en,而中心节点(集成节点)的初始值为所有词节点词向量的平均值 a v e r a g e ( e 1 . . . . e n ) average(e_1....e_n) average(e1....en)。
- 更新卫星节点。对于某卫星节点 i i i,先得到它的上下文信息 C i t C^t_i Cit,它由相邻节点 h i − 1 、 h i + 1 h_{i - 1}、h_{i+1} hi−1、hi+1,中心节点 s s s,和这个节点对应的token词嵌入 e i e^i ei组成。然后多头注意力更新特征,最后使用层归一化。
- 更新中心节点(relay node)。中心节点与上一时刻和所有卫星信息的交互,所以同样是多头注意力 M u l t i A t t ( s t − 1 , s t − 1 ) MultiAtt(s^{t-1},s^{t-1}) MultiAtt(st−1,st−1),H是可学习的位置编码(它在所有时刻都是一样的)。
- 交替更新T步,over。
paper:https://arxiv.org/abs/1902.09113
code:https://github.com/fastnlp/fastNLP
Transformer-XL
Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context,ACL 2019
问题:
- Transformer可以学习到输入文本的长距离依赖关系和全局特性,但是! 需要事先设定输入长度,这导致了其对于长程关系的捕捉有了一定限制。
- 出于效率的考虑,需要对输入的整个文档进行分割(固定的),那么每个序列的计算相互独立,所以只能够学习到同个序列内的语义联系,整体上看,这将会导致文档语意上下文的碎片化(context fragmentation)。
那么如何学习更长语义联系?
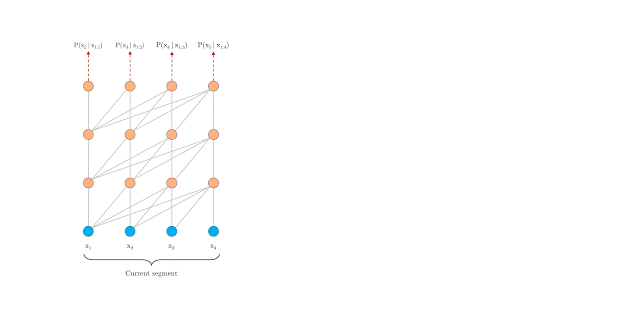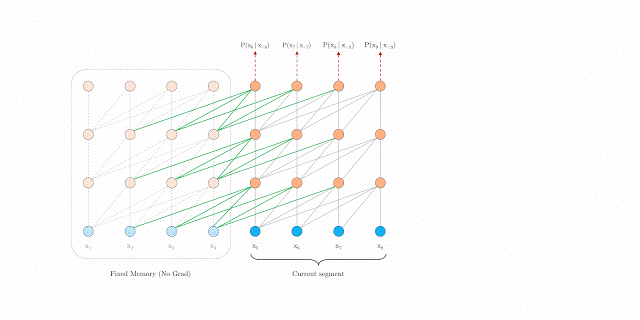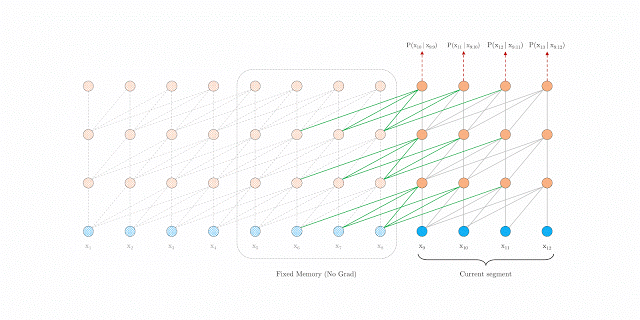
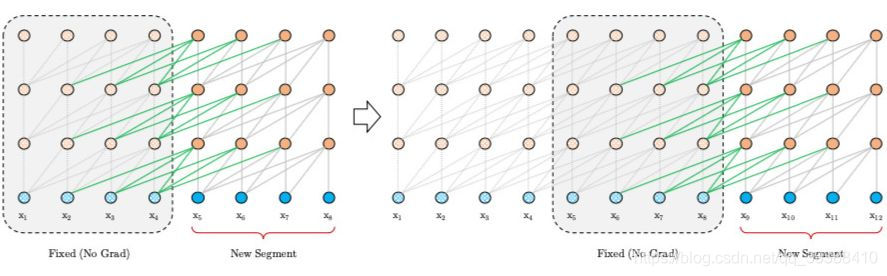
segment-level Recurrence
segment-level循环机制。如上图左边为原始 Transformer,右边为 Transformer-XL,Transformer-XL 模型的计算当中加入绿色连线,使得当层的输入取决于本序列和上一个序列前一层的输出。这样每个序列计算后的隐状态会参与到下一个序列的计算当中,使得模型能够学习到跨序列的语义联系。(看动图可能更好理解)
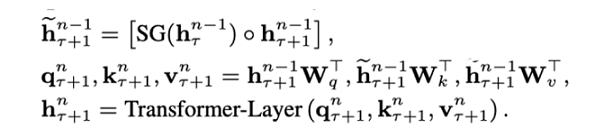
h r n h^n_r hrn是第 r r r个segment的第n层隐向量,那么第r+1个的第n层的隐向量的计算,就是上面这套公式。
- 其中SG是是stop-gradient,不再对 s t s_t
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1578
1578

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









