







目前我们对Transformer模型的研究已经很全面了,关于它的复现成果也非常多,但都比较零散,不成系统,而且缺乏对Transformer改进变体的详细梳理,这对我们改模型写代码很不友好。
所以我今天特地帮大家整理了Transformer各组件的魔改方法以及创新思路,每种方法的来源论文以及复现代码都放上了,代码超级简洁,相信能给同学们提供不少灵感。
篇幅原因,论文和代码只做简单介绍,就不详细展示了,需要的同学看文末
精确注意力
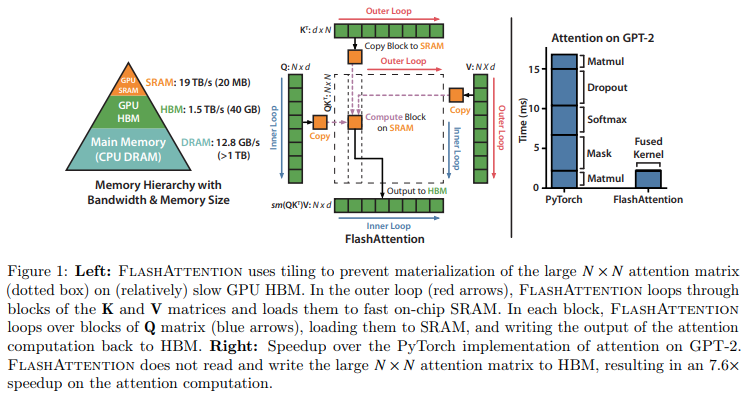
论文:FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
「简介:」FlashAttention是一种新的算法,它使得Transformer模型(一种广泛用于自然语言处理的深度学习模型)在处理长文本序列时能够更快且更节省内存。这个算法通过优化GPU内存的使用来减少内存读写次数,从而提高了计算效率。实验结果表明,使用FlashAttention训练的模型不仅训练速度更快,而且能够处理更长的文本序列,提高了模型的性能和能力。
通过持久内存增强自注意力机制
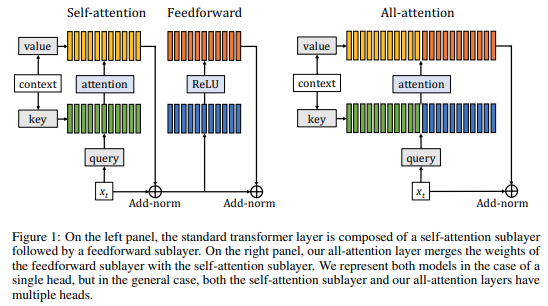
论文:Augmenting Self-attention with Persistent Memory
「简介:」论文介绍了一种新的模型,它仅由注意力层组成,用于增强自注意力机制。传统的Transformer网络包含两个连续的模块:前馈层和自注意力层。自注意力层允许网络捕捉长期依赖关系,通常被认为是Transformer成功的关键因素。基于这一直觉,作者提出了一种新模型,该模型通过增加持久内存向量来增强自注意力层,这些向量在前馈层中起到了类似的作用。由于有了这些向量,可以在不降低Transformer性能的情况下去除前馈层。评估结果显示,该模型在标准的字符级和单词级语言建模基准测试中带来了好处。
记忆transformer
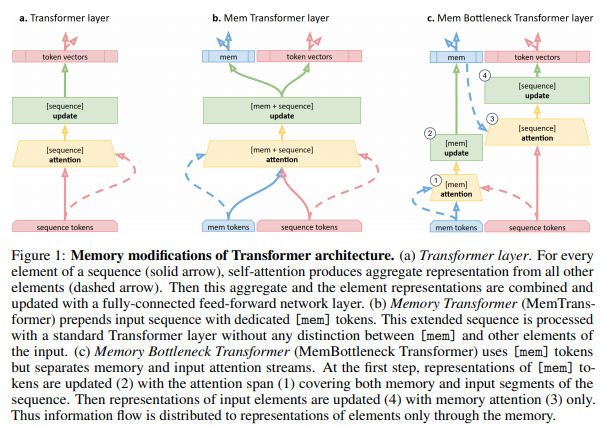
论文:Memory Transformer
「简介:」作者描述了一种名为Memory Transformer的模型,它通过增加可训练的记忆组件来改进传统的Transformer模型。这种记忆增强的神经网络(MANNs)能够学习简单的算法,如复制或反转,并且可以通过反向传播成功地训练在从问答到语言建模的多样化任务上,其性能超越了复杂度相当的RNN和LSTM。在这个工作中,作者提出了对Transformer基线的几种扩展:(1)增加记忆标记来存储非局部表示;(2)为全局信息创建记忆瓶颈;(3)用专门的层控制记忆更新。
改善自注意力的规范化
论文:Transformers without Tears: Improving the Normalization of Self-Attention
「简介:」论文介绍了三种改进Transformer模型训练的方法。第一种是使用预规范化残差连接,可以不用预热直接用大学习率训练。第二种是用一个参数进行ℓ2规范化,这样可以训练得更快,效果也更好。第三种是固定词嵌入的长度,这也有助于提高性能。这些改进在小资源语言对上的实验表明,它们能够提高模型的收敛速度和翻译质量。但在大资源语言对上,预规范化可能会降低性能。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1020
1020

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









