







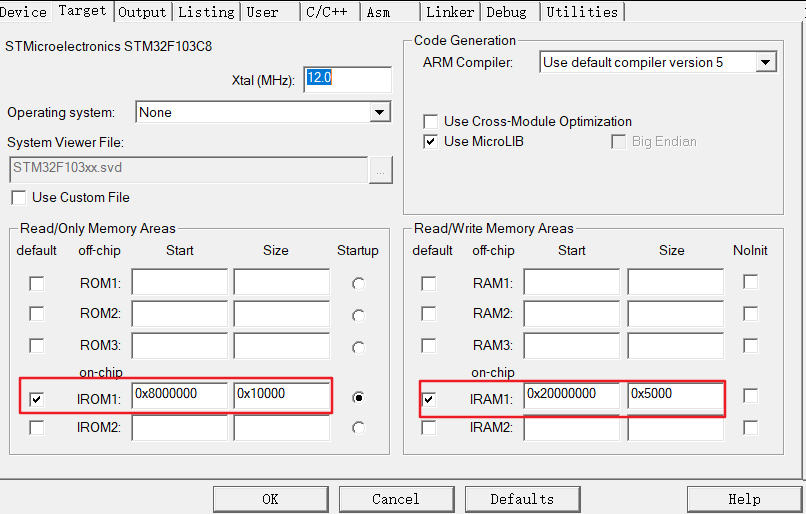
STM32F103C8T6
CPU:STM32F103RCT6,LQFP64,FLASH:64KB,RAM:20KB
flash起始地址为0x8000000,大小为0x10000(16进制)—>65536字节(10进制)—>64KB
RAM起始地址为0x2000000,大小为0x5000(16进制)—>20480字节(10进制)—>20KB
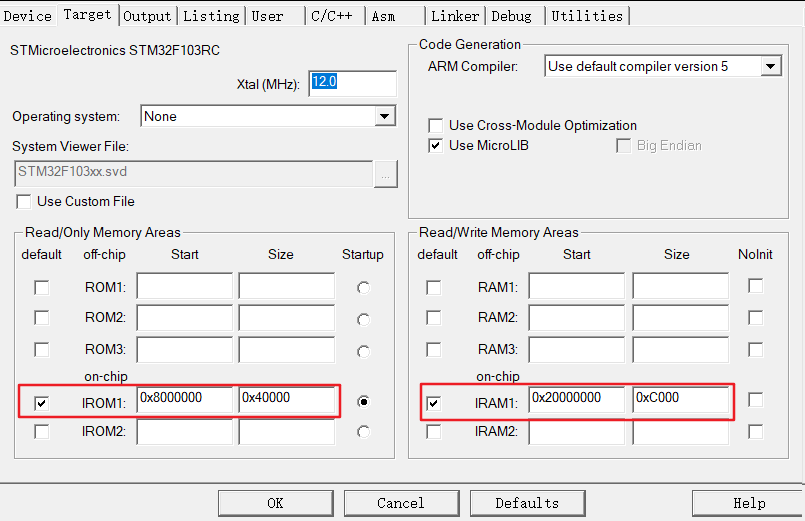
STM32F103RCT6
CPU:STM32F103RCT6,LQFP64,FLASH:256KB,SRAM:48KB;
flash起始地址为0x8000000,大小为0x4000(16进制)—>262144字节(10进制)—>256KB
RAM起始地址为0x2000000,大小为0xC000(16进制)—>49125字节(10进制)—>48KB
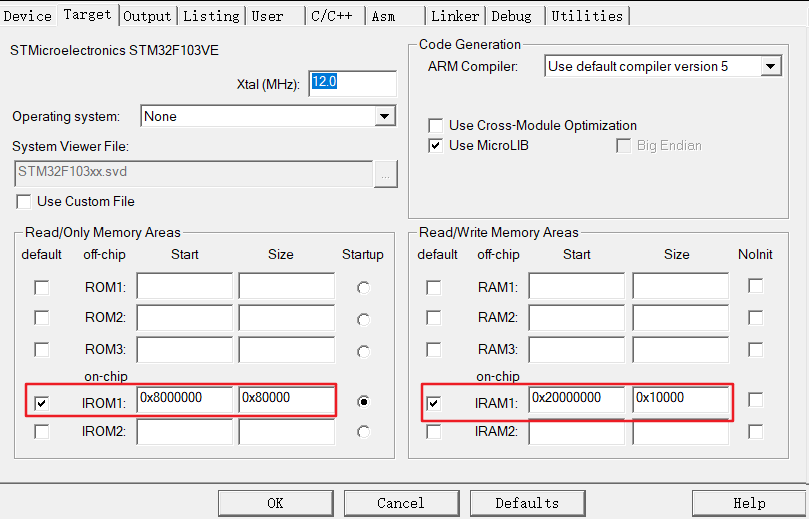
STM32F103VET6
CPU:STM32F103VET6,LQFP100,FLASH:512KB,SRAM:64KB;
flash起始地址为0x8000000,大小为0x80000(16进制)—>524288字节(10进制)—>512KB
RAM起始地址为0x2000000,大小为0x10000(16进制)—>65536字节(10进制)—>64KB
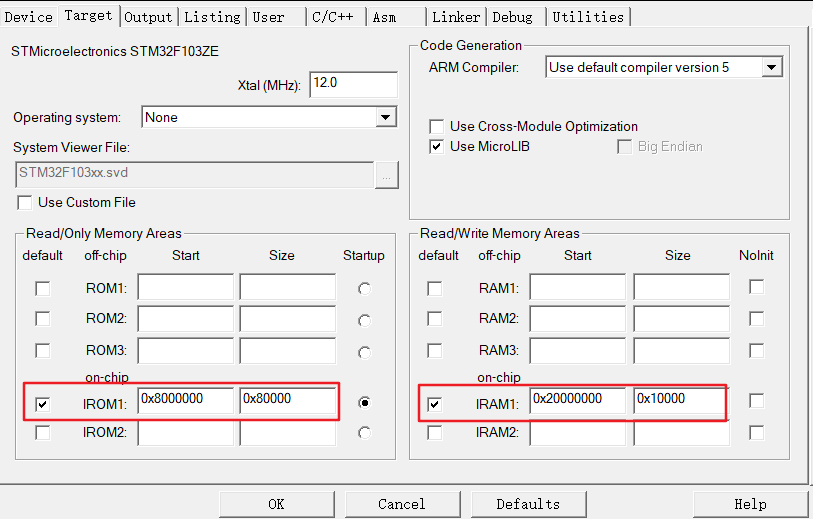
STM32F103ZET6
CPU:STM32F103ZET6,LQFP144,FLASH:512KB,SRAM:64KB;
flash起始地址为0x8000000,大小为0x80000(16进制)—>524288字节(10进制)—>512KB
RAM起始地址为0x2000000,大小为0x10000(16进制)—>65536字节(10进制)—>64KB


















 4789
4789

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











