







 本文介绍了模型调优与模型融合的概念,包括交叉验证的原理与GridSearchCV的应用,以及Stacking的详细步骤和代码实现。通过Python进行模型融合,提升预测效果。文中提供多个Stacking的变体,如使用概率作为特征和特征多样性策略,并解释了相关参数的含义。
本文介绍了模型调优与模型融合的概念,包括交叉验证的原理与GridSearchCV的应用,以及Stacking的详细步骤和代码实现。通过Python进行模型融合,提升预测效果。文中提供多个Stacking的变体,如使用概率作为特征和特征多样性策略,并解释了相关参数的含义。
这是本人对模型的融合的代码合集,环境是python3,只要复制过去就可以用了,非常方便。
- 目录
- 1.交叉验证
1.1 原理
1.2 GridSearchCV - 2.绘制学习曲线
- 3.stacking
3.1 stacking原理
3.2 代码实现不同版本的stacking
3.2.1.官网给的例子(简单粗暴)
3.2.2 用概率作为第二层模型的特征
3.2.3 特征多样性
3.2.4.参数详解
1.交叉验证
1.1 原理
基本思想就是把训练数据分成几份,分别为训练集和测试集,用训练集和验证集作为模型选择。最典型的是k折交叉验证:
K折交叉验证,初始采样分割成K个子样本,一个单独的子样本被保留作为验证模型的数据,其他K-1个样本用来训练。交叉验证重复K次,每个子样本验证一次,平均K次的结果或者使用其它结合方式,最终得到一个单一估测。这个方法的优势在于,同时重复运用随机产生的子样本进行训练和验证,每次的结果验证一次,10次交叉验证是最常用的。
如图是5折,因此可以做五次验证,然后对结果进行平均。
1.2 GridSearchCV
一般使用GridSearchCV来做格点搜索寻找最优参数,代码如下:
import numpy as np
import pandas as pd
from pandas import DataFrame
from patsy import dmatrices
import string
from operator import itemgetter
import json
from sklearn.ensemble import RandomForestClassifier,GradientBoostingClassifier
from sklearn.cross_validation import cross_val_score
from sklearn.pipeline import Pipeline
from sklearn.grid_search import GridSearchCV
from sklearn.cross_validation import train_test_split,StratifiedShuffleSplit,StratifiedKFold
from sklearn import preprocessing
from sklearn.metrics import classification_report
from sklearn.externals import joblib
seed=0
clf=GradientBoostingClassifier(n_estimators=500)
###grid search找到最好的参数
param_grid = dict( )
##创建分类pipeline
pipeline=Pipeline([ ('clf',clf) ])
grid_search = GridSearchCV(pipeline, param_grid=param_grid, verbose=3,scoring='accuracy',\
cv=StratifiedShuffleSplit(y_train, n_iter=10, test_size=0.2,random_state=seed)).fit(x_train, y_train)
# 对结果打分
print("Best score: %0.3f" % grid_search.best_score_)
print(grid_search.best_estimator_)
print('-----grid search end------------')
print ('on all train set')
scores = cross_val_score(grid_search.best_estimator_, x_train, y_train,cv=3,scoring='accuracy')
print (scores.mean(),scores)
print ('on test set')
scores = cross_val_score(grid_search.best_estimator_, x_test, y_test,cv=3,scoring='accuracy')
print(scores.mean(),scores)
结果如下:
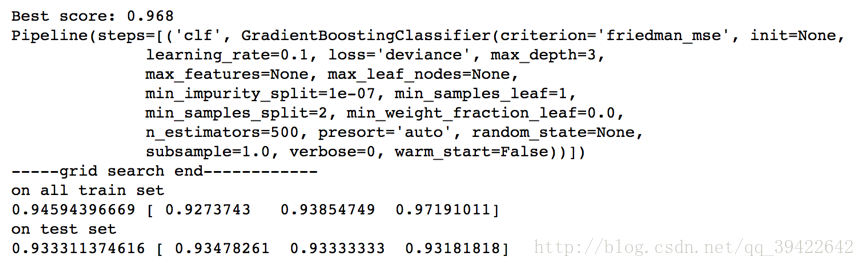
把输出的参数复制一下就OK了。
2.绘制学习曲线
要是模型太复杂,导致过拟合,对测试集的预测就不会太好,该怎么判断模型是否过拟合呢?
对的,就是学习曲线
def plot_learning_curve(estimator, title, X, y, ylim=None, cv=None,
n_jobs=1, train_sizes=np.linspace(.1, 1.0, 5)):
plt.figure()
plt.title(title)
if ylim is not None:
plt.ylim(*ylim)
plt.xlabel("Training examples")
plt.ylabel("Score")
train_sizes, train_scores, test_scores = learning_curve(
estimator, X, y, cv=cv, n_jobs=n_jobs, train_sizes=train_sizes)
train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)
plt.grid()
plt.fill_between(train_sizes, train_scores_mean - train_scores_std,
train_scores_mean + train_scores_std, alpha=0.1,
color="r")
plt.fill_between(train_sizes, test_scores_mean - test_scores_std,
test_scores_mean + test_scores_std, alpha=0.1, color="g")
plt.plot(train_sizes, train_scores_mean, 'o-', color="r",
label="Training score")
plt.plot(train_sizes, test_scores_mean, 'o-', color="g",
label="Cross-validation score")
plt.legend(loc="best")
return plt
title = "Learning Curves (Random Forest, n_estimators = 100)"
cv = cross_validation.ShuffleSplit(df_train_data.shape[0], n_iter=10,test_size=0.2, random_state=0)
estimator = RandomForestRegressor(n_estimators = 100)
plot_learning_curve(estimator, title, X, y, (0.0, 1.01), cv=cv, n_jobs=4)
plt.show()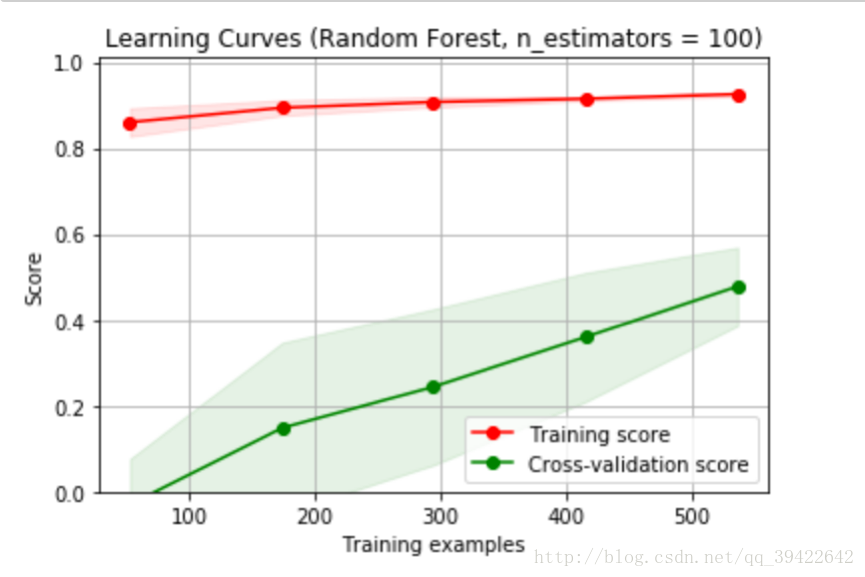
一看就是欠拟合了,因为数据,特征都太少,模型学习的非常容易,所以在训练集上做的非常好,但是在测试集上做的特别差。其实主要看他们的差距,差距特别大,多半是不正常。
发现他过拟合之后该怎么办了呢?
对于过拟合:
1.找更多的数据来学习
2.增大正则化系数
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 400
400











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









