






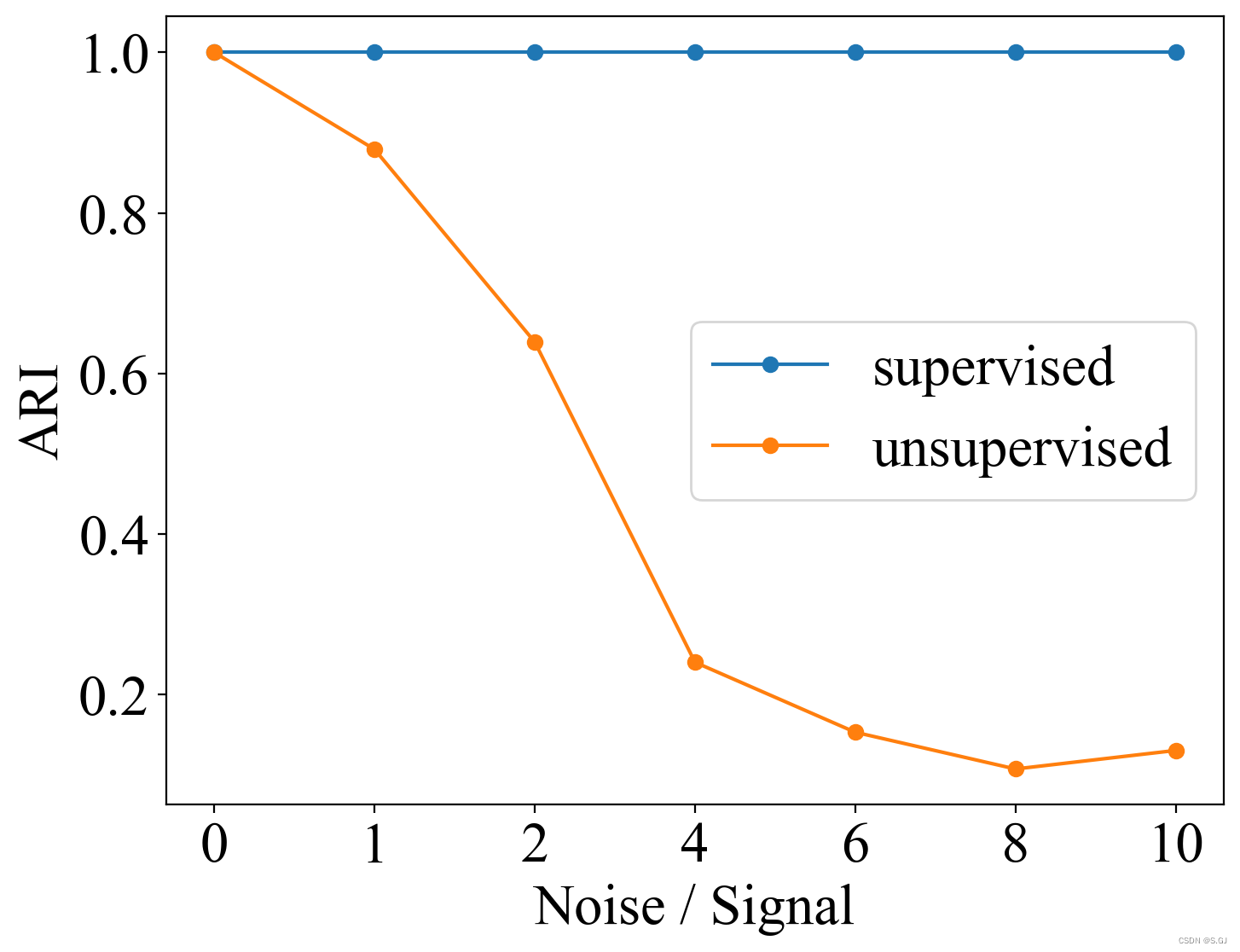
 本文通过构建含有不同噪声比例的数据集,比较了KMeans无监督算法和MLP有监督算法在处理噪声数据时的表现,发现随着噪声增加,无监督算法效果下降,而有监督算法对噪声鲁棒性更强。
本文通过构建含有不同噪声比例的数据集,比较了KMeans无监督算法和MLP有监督算法在处理噪声数据时的表现,发现随着噪声增加,无监督算法效果下降,而有监督算法对噪声鲁棒性更强。
目录
一、实验目的
探索数据中存在大量噪声时对无监督算法(KMeans)和有监督算法(MLP)的影响,并观察它们之间的差异。
二、实验过程
1、手动构造没有噪声的数据(2个特征,4个类别)。

2、以扩展特征维度的方式往数据中不断添加噪声,分别运行无监督算法和有监督算法并记录它们的实验结果。
三、实验结论
随着噪声的不断加入,无监督算法的表现逐渐下降,而有监督算法则对数据中存在的大量噪声十分鲁棒。
四、实验代码
1、数据集
import torch
import numpy as np
from torch.utils.data import Dataset
class MyDataset(Dataset):
def __init__(self, noise_ratio=1, normalization=True):
np.random.seed(2023) # 固定数据集
C1 = np.array([np.random.uniform(0,1,100), np.random.uniform(0,1,100)]).T
C2 = np.array([np.random.uniform(0,1,100), np.random.uniform(2,3,100)]).T
C3 = np.array([np.random.uniform(2,3,100), np.random.uniform(0,1,100)]).T
C4 = np.array([np.random.uniform(2,3,100), np.random.uniform(2,3,100)]).T
data = np.concatenate([C1, C2, C3, C4], axis=0)
# 添加噪声
noise = np.random.randn(data.shape[0], data.shape[1] * noise_ratio)
self.X = np.concatenate([data, noise], axis=-1)
# 特征归一化
if normalization:
self.X = (self.X - np.mean(self.X, axis=0, keepdims=True)) / (np.std(self.X, axis=0, keepdims=True) + 1e-8)
self.Y = np.array([0]*C1.shape[0]+[1]*C2.shape[0]+[2]*C3.shape[0]+[3]*C4.shape[0])
# ndarray 转 tensor
self.X = torch.Tensor(self.X)
self.Y = torch.Tensor(self.Y).long()
def __len__(self):
return len(self.X)
def __getitem__(self, index):
return self.X[index], self.Y[index]
2、无监督算法
from sklearn.cluster import KMeans
from sklearn.metrics.cluster import adjusted_rand_score
from dataset import MyDataset
if __name__ == '__main__':
ARIs = []
for noise_ratio in [0, 1, 2, 4, 6, 8, 10]:
class_num = 4
dataset = MyDataset(noise_ratio=noise_ratio)
x = dataset.X.numpy()
y = dataset.Y.numpy()
y_pred = KMeans(n_clusters=class_num).fit_predict(x)
ari = adjusted_rand_score(y, y_pred)
ARIs.append(round(ari,4))
print('noise_ratio={}: {}'.format(noise_ratio, ari))
print(ARIs)[1.0, 0.8792, 0.639, 0.2398, 0.1526, 0.1068, 0.1299]
3、有监督算法
import torch
import numpy as np
import torch.nn as nn
from tqdm import tqdm
import torch.optim as optim
from torch.utils.data import DataLoader, random_split
from sklearn.metrics.cluster import adjusted_rand_score
from dataset import MyDataset
class MLP(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(MLP, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(hidden_size, output_size)
def forward(self, x):
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
return x
if __name__ == '__main__':
ARIs = []
for noise_ratio in [0, 1, 2, 4, 6, 8, 10]:
class_num = 4
train_ratio = 0.8
hidden_size = 64
num_epochs = 200
learning_rate = 0.001
dataset = MyDataset(noise_ratio=noise_ratio)
test_ratio = 1.0 - train_ratio # 8:2
train_size = int(train_ratio * len(dataset))
test_size = len(dataset) - train_size
train_set, test_set = random_split(dataset, [train_size, test_size])
train_loader = DataLoader(train_set, batch_size=len(train_set), shuffle=True)
test_loader = DataLoader(test_set, batch_size=len(test_set), shuffle=False)
input_size = dataset.X.shape[-1]
model = MLP(input_size, hidden_size, class_num).cuda()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=learning_rate, momentum=0.9)
# 训练模型
best_test_ari = 0.
for epoch in range(num_epochs):
# test
model.eval()
total_test_ari = []
with torch.no_grad():
for X, Y in tqdm(test_loader):
X, Y = X.cuda(), Y.cuda()
output = model(X)
ari = adjusted_rand_score(Y.cpu().numpy(), torch.argmax(output, dim=-1).cpu().detach().numpy())
total_test_ari.append(ari)
test_ari = np.mean(total_test_ari)
best_test_ari = test_ari if test_ari > best_test_ari else best_test_ari
# train
model.train()
total_train_loss = []
total_train_ari = []
for X, Y in tqdm(train_loader):
X, Y = X.cuda(), Y.cuda()
output = model(X)
loss = criterion(output, Y)
loss.backward()
optimizer.step()
ari = adjusted_rand_score(Y.cpu().numpy(), torch.argmax(output, dim=-1).cpu().detach().numpy())
total_train_loss.append(loss.item())
total_train_ari.append(ari)
train_loss = np.mean(total_train_loss)
train_ari = np.mean(total_train_ari)
print("epoch: %d, train_loss: %.4f, train_ari: %.4f, test_ari: %.4f, best_test_ari: %.4f" %
(epoch, train_loss, train_ari, test_ari, best_test_ari))
ARIs.append(round(best_test_ari,4))
print(ARIs)[1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0]
4、可视化数据
import matplotlib.pyplot as plt
from dataset import MyDataset
plt.rcParams['font.size'] = 24
plt.rcParams['font.sans-serif'] = ['Times New Roman']
if __name__ == '__main__':
dataset = MyDataset(noise_ratio=0, normalization=False)
X = dataset.X.numpy()
Y = dataset.Y.numpy()
fig, ax = plt.subplots(figsize=(6, 6))
for y in set(Y):
plt.scatter(X[Y==y, 0], X[Y==y, 1], label='class {}'.format(y+1))
box = ax.get_position()
ax.set_position([box.x0, box.y0, box.width, box.height * 0.8])
ax.legend(loc='center left', bbox_to_anchor=(1.0, 0.5), markerscale=1., handlelength=1)
plt.xlabel('feature_1', labelpad=10)
plt.ylabel('feature_2', labelpad=10)
plt.savefig('data.png', dpi=200, bbox_inches='tight')
plt.close()
5、可视化实验结果
import matplotlib.pyplot as plt
plt.rcParams['font.size'] = 24
plt.rcParams['font.sans-serif'] = ['Times New Roman']
if __name__ == '__main__':
noise_ratio = [0, 1, 2, 4, 6, 8, 10]
ARI_supervised = [1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0]
ARI_unsupervised = [1.0, 0.8792, 0.639, 0.2398, 0.1526, 0.1068, 0.1299]
fig, ax = plt.subplots(figsize=(8, 6))
plt.plot(ARI_supervised, marker="o", label="supervised")
plt.plot(ARI_unsupervised, marker="o", label="unsupervised")
plt.legend()
plt.xticks(ticks=range(len(noise_ratio)), labels=noise_ratio)
plt.xlabel("Noise / Signal")
plt.ylabel("ARI")
plt.savefig("results.png", dpi=200, bbox_inches='tight')
plt.close()
(本人水平有限,还请各位批评指正)
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









