






一、理论基础
1.本文要解决的问题
较深的“plain network”表现不如较浅的“plain network”(无论是在训练集上还是在测试集上)
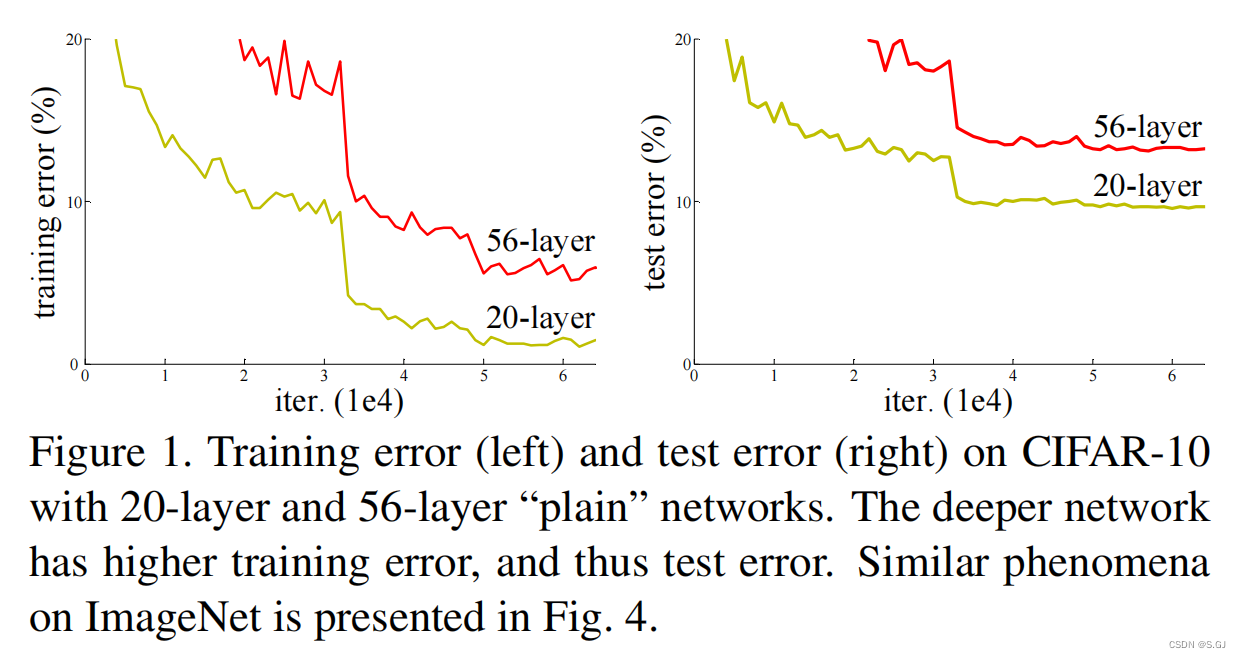
2.解决上述问题的关键操作:跳跃连接
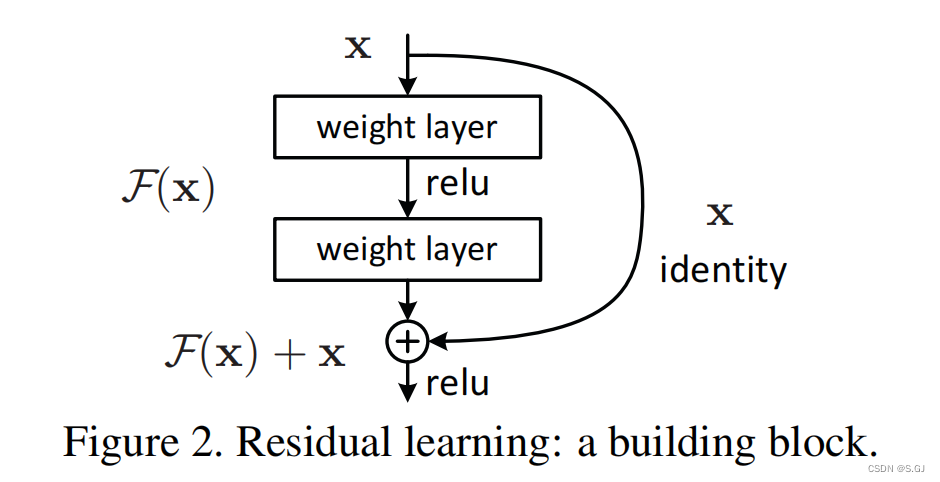
3.两种不同的残差块
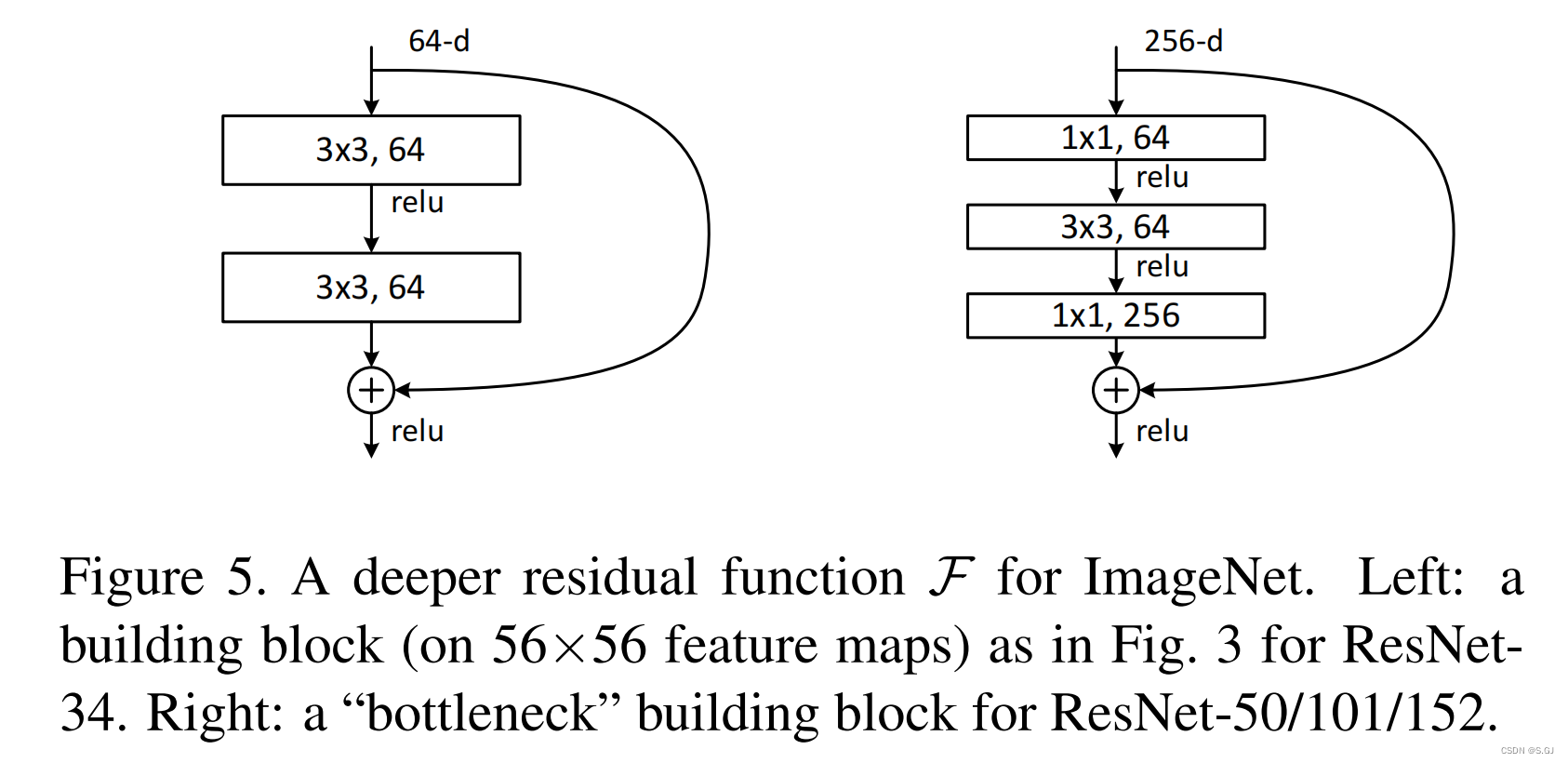
注:右边的block有一个先降维后升维的操作,这种block被用于更深的网络中。
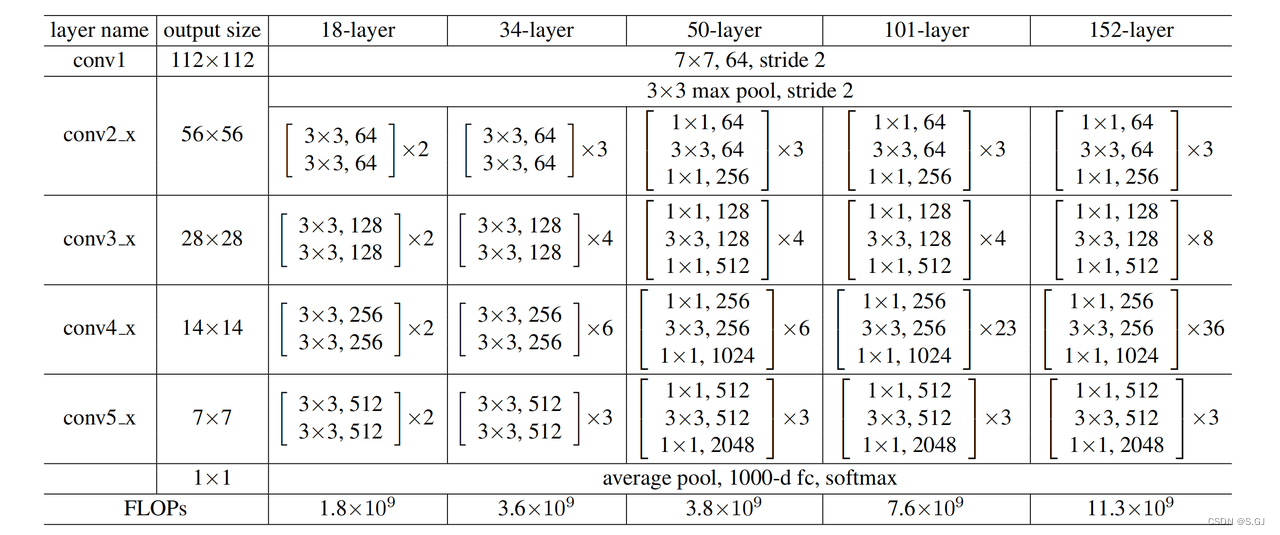
4.不同深度的ResNet
5.跳跃连接维度不一致时,论文中的做法
Conv1x1 + BN
二、代码(ResNet50 + CIFAR10)
1.ResNet50模型
import torch
import torch.nn as nn
import torch.nn.functional as F
# 残差块
class ResidualBlock(nn.Module):
def __init__(self, inchannel, midchannel, outchannel, stride=1):
super(ResidualBlock, self).__init__()
# F(x)
self.left = nn.Sequential(
nn.Conv2d(inchannel, midchannel, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(midchannel),
nn.ReLU(True),
nn.Conv2d(midchannel, midchannel, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(midchannel),
nn.ReLU(True),
nn.Conv2d(midchannel, outchannel, kernel_size=1, stride=1, bias=False),
nn.BatchNorm2d(outchannel),
)
# x
if stride != 1 or inchannel != outchannel:
self.shortcut = nn.Sequential(
nn.Conv2d(inchannel, outchannel, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(outchannel)
)
else:
self.shortcut = nn.Sequential()
def forward(self, x):
out = self.left(x)
out += self.shortcut(x)
out = F.relu(out)
return out
class ResNet50(nn.Module):
def __init__(self, C_in=3, C_out=10):
super(ResNet50, self).__init__()
self.conv_stem = nn.Sequential(
nn.Conv2d(in_channels=C_in, out_channels=64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True), # 原地修改信息,减少显存占用
nn.MaxPool2d(kernel_size=3, stride=2, padding=1),
)
self.layer1 = nn.Sequential(
ResidualBlock(64, 64, 256, 1),
ResidualBlock(256, 64, 256, 1),
ResidualBlock(256, 64, 256, 1), # 3
)
self.layer2 = nn.Sequential(
ResidualBlock(256, 128, 512, 2),
ResidualBlock(512, 128, 512, 1),
ResidualBlock(512, 128, 512, 1),
ResidualBlock(512, 128, 512, 1), # 4
)
self.layer3 = nn.Sequential(
ResidualBlock(512, 256, 1024, 2),
ResidualBlock(1024, 256, 1024, 1),
ResidualBlock(1024, 256, 1024, 1),
ResidualBlock(1024, 256, 1024, 1),
ResidualBlock(1024, 256, 1024, 1),
ResidualBlock(1024, 256, 1024, 1), # 6
)
self.layer4 = nn.Sequential(
ResidualBlock(1024, 512, 2048, 2),
ResidualBlock(2048, 512, 2048, 1),
ResidualBlock(2048, 512, 2048, 1), # 3
)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(2048, C_out)
def forward(self, x):
x = self.conv_stem(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x2.工具(固定随机性 + 绘制训练曲线)
import os
import torch
import random
import numpy as np
import matplotlib.pyplot as plt
def set_seed(seed):
np.random.seed(seed)
random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed) # 禁止hash随机化
os.environ['CUBLAS_WORKSPACE_CONFIG'] = ':4096:8' # 在cuda 10.2及以上的版本中,需要设置以下环境变量来保证cuda的结果可复现
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed) # 多GPU训练需要设置这个
torch.manual_seed(seed)
# torch.use_deterministic_algorithms(True) # 一些操作使用了原子操作,不是确定性算法,不能保证可复现,设置这个禁用原子操作,保证使用确定性算法
torch.backends.cudnn.deterministic = True # 确保每次返回的卷积算法是确定的
torch.backends.cudnn.enabled = False # 禁用cudnn使用非确定性算法
torch.backends.cudnn.benchmark = False # 与上面一条代码配套使用,True的话会自动寻找最适合当前配置的高效算法,来达到优化运行效率的问题。False保证实验结果可复现。
def plot_train_curve(output_dir, train_loss, test_loss):
plt.plot(range(len(train_loss)), train_loss, label="train_loss", c="r")
plt.plot(range(len(test_loss)), test_loss, label="test_loss", c="b")
plt.legend(loc="best")
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.savefig("{}/train_curve".format(output_dir))
plt.close()
3.训练
import matplotlib
matplotlib.use('Agg')
import warnings
warnings.filterwarnings('ignore')
import os
import torch
import argparse
import numpy as np
from tqdm import tqdm
from torch.utils.data import DataLoader
import torchvision.datasets as datasets
from torchvision.transforms import transforms
from util import set_seed, plot_train_curve
from ResNet50 import ResNet50
def train(args):
print('------------------------Model and Training Details--------------------------')
print(args)
# seed
set_seed(2024)
# dataset
transform_train = transforms.Compose([
transforms.RandomHorizontalFlip(), # 水平翻转
transforms.RandomCrop(32, padding=4), # 裁剪
transforms.ColorJitter(0.5, 0.5, 0.5), # 颜色变换
transforms.ToTensor(),
transforms.Normalize(mean=[0.4914, 0.4822, 0.4465], std=[0.2470, 0.2435, 0.2616]),
])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.4914, 0.4822, 0.4465], std=[0.2470, 0.2435, 0.2616]),
])
train_dataset = datasets.CIFAR10("../data/CIFAR10", train=True, download=True, transform=transform_train)
train_loader = DataLoader(train_dataset, shuffle=True, num_workers=3, batch_size=args.batch_size)
test_dataset = datasets.CIFAR10("../data/CIFAR10", train=False, download=True, transform=transform_test)
test_loader = DataLoader(test_dataset, shuffle=False, num_workers=3, batch_size=args.batch_size)
# model and optimizer
model = ResNet50(C_in=3, C_out=10).cuda()
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=args.lr, weight_decay=args.weight_decay)
# training
best_test_acc = 0.
train_loss_epochs = []
test_loss_epochs = []
for epoch in range(args.epochs):
# test
model.eval()
test_acc = []
test_loss = []
with torch.no_grad():
for img, img_label in tqdm(test_loader):
img, img_label = img.cuda(), img_label.cuda()
output = model(img)
acc = torch.mean((torch.argmax(output, dim=-1) == img_label).float())
loss = criterion(output, img_label)
test_acc.append(acc.item())
test_loss.append(loss.item())
test_acc = np.mean(test_acc)
test_loss = np.mean(test_loss)
test_loss_epochs.append(test_loss)
if test_acc > best_test_acc:
best_test_acc = test_acc
torch.save(model.state_dict(), "{}/model_state_dict.pth".format(args.output_dir))
# train
model.train()
train_acc = []
train_loss = []
for img, img_label in tqdm(train_loader):
optimizer.zero_grad()
img, img_label = img.cuda(), img_label.cuda()
output = model(img)
acc = torch.mean((torch.argmax(output, dim=-1) == img_label).float())
loss = criterion(output, img_label)
loss.backward()
optimizer.step()
train_acc.append(acc.item())
train_loss.append(loss.item())
train_acc = np.mean(train_acc)
train_loss = np.mean(train_loss)
train_loss_epochs.append(train_loss)
print("epoch[%d/%d]: train_loss: %.4f, test_loss: %.4f, train_acc: %.4f, test_acc: %.4f" % (epoch+1, args.epochs, train_loss, test_loss, train_acc, test_acc))
# training loss curve
plot_train_curve(args.output_dir, train_loss_epochs, test_loss_epochs)
def test(args):
print('------------------------Model and Testing Details--------------------------')
print(args)
# seed
set_seed(2024)
# test dataset
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.4914, 0.4822, 0.4465], std=[0.2470, 0.2435, 0.2616]),
])
test_dataset = datasets.CIFAR10("../data/CIFAR10", train=False, download=True, transform=transform_test)
test_loader = DataLoader(test_dataset, shuffle=False, num_workers=3, batch_size=args.batch_size)
# model and load_state_dict
model = ResNet50().cuda()
model.load_state_dict(torch.load("{}/model_state_dict.pth".format(args.output_dir)))
# testing
model.eval()
test_acc = []
with torch.no_grad():
for img, img_label in tqdm(test_loader):
img, img_label = img.cuda(), img_label.cuda()
output = model(img)
acc = torch.mean((torch.argmax(output, dim=-1) == img_label).float())
test_acc.append(acc.item())
test_acc = np.mean(test_acc)
print("test_acc:", test_acc)
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--lr', type=float, default=1e-3,)
parser.add_argument('--epochs', type=int, default=200,)
parser.add_argument('--batch_size', type=int, default=2048,)
parser.add_argument('--weight_decay', type=float, default=1e-4,)
parser.add_argument('--output_dir', type=str, default='./log',)
args = parser.parse_args()
if not os.path.exists(args.output_dir):
os.makedirs(args.output_dir)
train(args)
test(args)















 3802
3802

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









