







前言:
最近写论文中,由于Discussion部分的需要,于是读了这篇文章,并记录一下。
摘要:
传统的使用对抗的方法来进行特征域自适应的文章存在两个问题:
1.域分类器仅尝试区分源域或目标域,因此不考虑类之间的任务特定决策边界。因此,训练有素的生成器(特征提取器)可以在类边界附近生成模糊特征。
2.这些使用对抗的特征域自适应方法旨在完全匹配不同域之间的特征分布,但是由于每个域的独有特征,这而很难实现。
例如下图所示:传统方法只是在尝试融合不同域之间的分布,但是由于每个域的特征都有其独有的特性,因此不可能实现完全匹配,这个时候即使对齐了源域和目标域的分布,由于没有考虑目标样本与特定于任务的决策边界之间的关系。此方法还是无法很好地提取区分特征
因此为了解决这个问题,文章中引入了一种新方法,该方法试图通过利用尝试使用特定于任务的分类器来检测源域分布范围之外的目标样本。我们的方法允许生成器生成目标样本的判别特征,因为它考虑了决策边界和目标样本之间的关系。 简单来讲就是生成器除了要对齐源域和目标域之外,还要尽可能地区分开目标域中的特征!!!可不可也利用这一点也尽可能地区分开源域不同特征之间的距离了???----由于源域是有监督的分割,所以本身就可以很好的判别特征(区分特征)

方法:
本文提出了一种新的对抗训练的方法,我们的方法的目标是通过使用特定于任务的分类器作为判别器来对齐源特征和目标特征,以便考虑类边界和目标样本之间的关系。 因此,我们的方法允许生成器生成目标样本的判别特征,因为它考虑了决策边界和目标样本之间的关系。
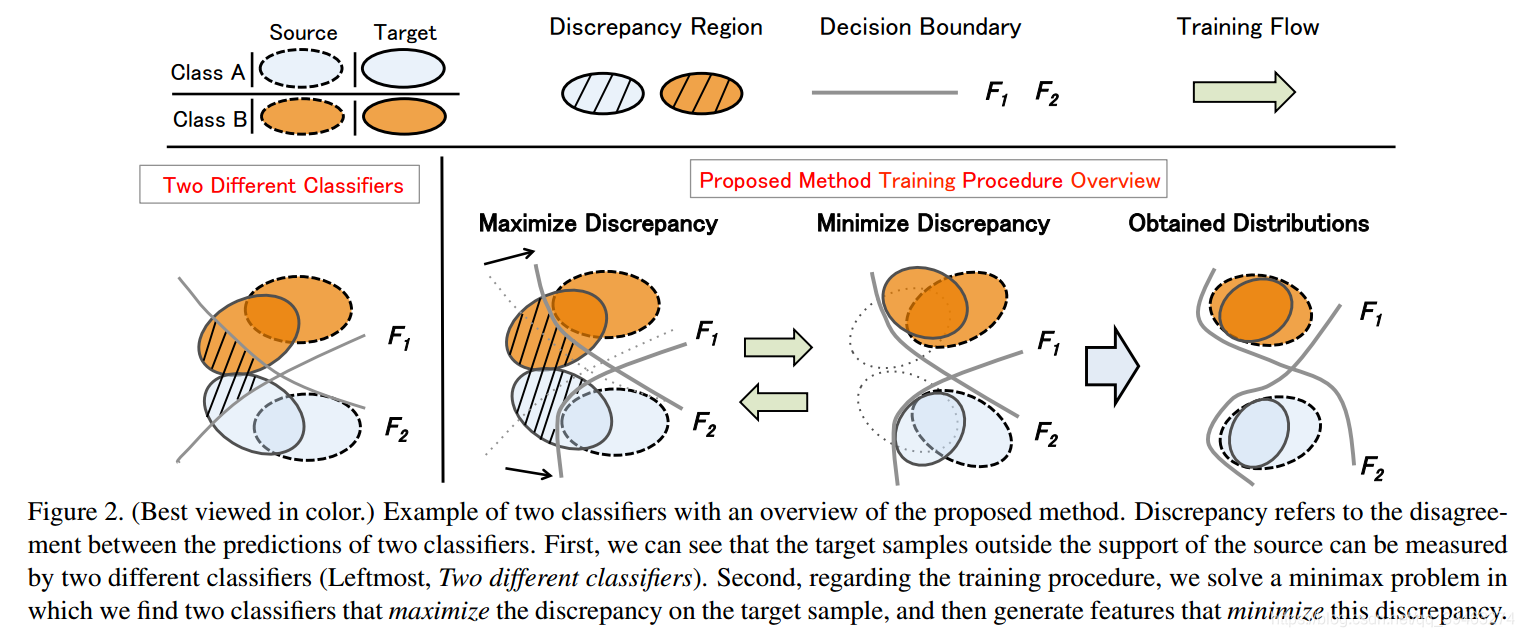
问题本质:
为了完成以上目标,该问题的本质就是如何才能检测出远离源域覆盖范围的目标域样本。如上图,对于分类器F2来说,黑线部分的target就是远离源域的部分;对于F1分类器来说同理。因此文章中通过构建两个分类器F1和F2来检测远离源域覆盖范围的目标域样本
方法分析:
要检测出这些目标样本: 文中提出在目标样本的预测中利用两个分类器的分歧。即假设两个分类器都能够正确地预测出源域(对源域的分割提出了很高的要求),因此超出源域覆盖范围的目标域被两个不同的的分类器分类会有不同的分类结果。
两个分类器构成了一个特定于任务的分类器,然后将其作为一个判别器
训练方法:
1.判别器(两个分类器):训练判别器来最大化discrepancy。 如果没有这一步,两个分类器将会非常得像,从而无法检测出远离源域覆盖范围的目标域样本
2.生成器(特征提取器):训练生成器来糊弄判别器,因此来最小化discrepancy.
总结:
这种新的生成对抗方法考虑目标样本与特定于任务的决策边界之间的关系,创新性地构建了两个特定任务的分类器联合来作为一个判别器(判别器本质上就是一个损失函数,在本文中没有构建一个专门的判别器),进行特征层面的域自适应,从而取得了不错的结果!!!

















 693
693

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









