







 本次实验基于Hadoop 2.7.5,通过MapReduce对YouTube 2007年2月22至5月18日的视频数据进行分析,统计不同视频类型数量。实验包括数据预处理、上传、MapReduce程序设计及结果分析,结果显示用户对音乐、娱乐和体育类视频兴趣较高。
本次实验基于Hadoop 2.7.5,通过MapReduce对YouTube 2007年2月22至5月18日的视频数据进行分析,统计不同视频类型数量。实验包括数据预处理、上传、MapReduce程序设计及结果分析,结果显示用户对音乐、娱乐和体育类视频兴趣较高。
一、实验背景
随着近年来视频拍摄设备与视频处理技术的高速发展,对网络上海量视频的分析越来越受到关注与重视。本实验希望通过使用 Hadoop 实验数据集 —— Dataset for "Statistics and Social Network of YouTube Videos" 进行简明的分析实验,从而加深对大数据分析的体会与认识、对 Hadoop、MapReduce 等的理解与应用。
二、实验目的
本实验将在虚拟机上 (CentOS 7.5 64bits),基于 Hadoop 2.7.5 (64bits),使用 MapReduce 实现对部分 YouTube 视频数据集的分析,以统计出某一时期内 YouTube 用户已上传视频类型的总数量,并对可视化后的结果进行简要的比较与分析。
三、实验过程
3.1 数据集预处理与上传
本实验所用的 YouTube 数据集下载自 School of Computing Science Simon Fraser University。数据集中,每行都代表一条用户上传视频数据,每行中各字段由 Tab 字符 ('\t') 分隔开,各字段含义按顺序如下表所示:
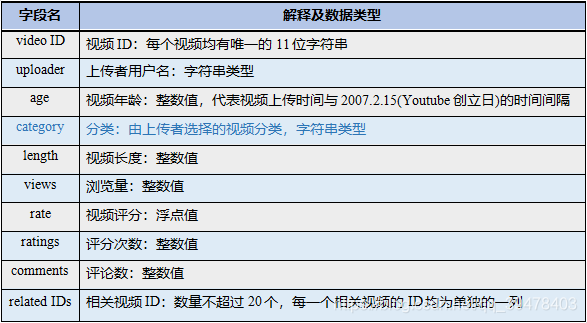
部分数据集如下所示。其中,每行数据从左往右依次表示:video ID、uploader、age、category、length、views、rate、ratings、comments、related IDs。而本实验所关心的、将使用到的是 category 这项 (蓝框)。

实验所用的数据集采样自2007年2月22至5月18日中的35天的YouTube用户上传视频信息。由于下载得到的数据集共有35个压缩包(解压后是4-5个txt文本),对应35天的采样数据,为此,我们需要先在本地主机上合并它们。合并方法有很多种,此处将主要描述方法一,概述方法二。
3.1.1 合并数据集——方法一
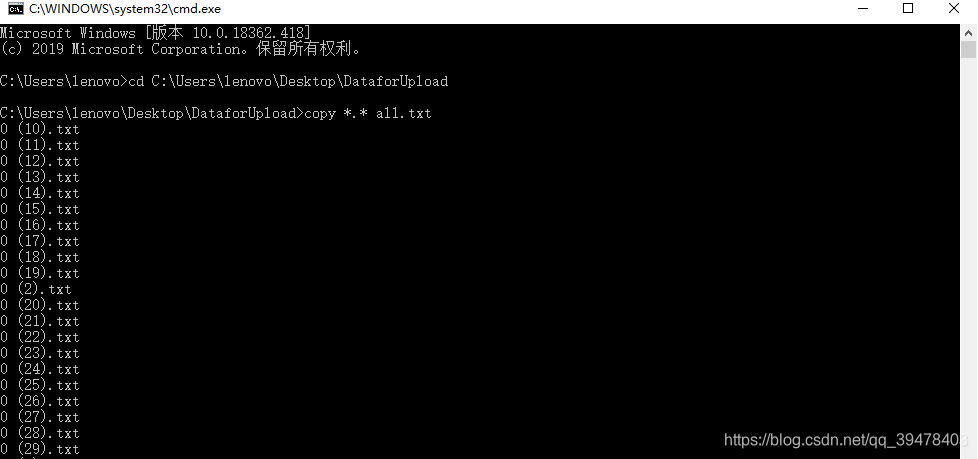
先把解压后的所有txt数据文本放置在桌面的DataforUpload文件夹中,然后打开命令行程序,按路径 cd 进入DataforUpload文件夹,执行 copy *.* all.txt 对文件夹下所有数据文本执行复制合并的批处理操作,生成汇总数据集文件 all.txt 共计895.5MB,含数据约一百万条以上,如下所示:

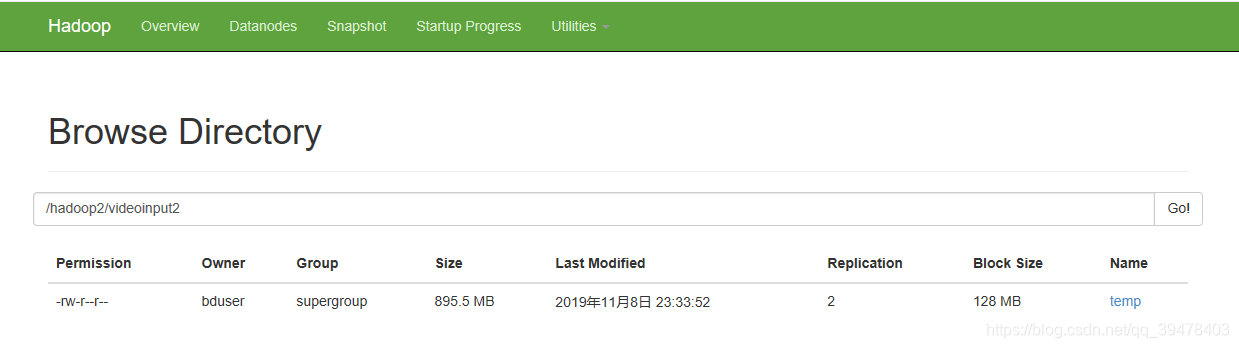
然后连接VPN,登陆虚拟机,运行Hadoop进程,再使用upload程序(见附录)将本地的数据集all.txt上传至HDFS的 "/hadoop2/videoinput2/" 路径下。通过 HDFS Web UI 验证文件上传成功,如下所示:
3.1.2 合并数据集方法二
可以先将本地的含有所有分散文本数据的 DataforUpload 文件夹上传至 HDFS (的hadoop2/inputVideo1/ 路径下),再使用hdfs dfs -getmerge <源路径 目的路径 > 命令将 HDFS 中 DataforUpload 文件夹下所有数据文本合并下载到虚拟机系统本地 (的 /opt/bigdata/hadoop/text/ 路径下) 并命名为 temp。然后cd进入temp所在目录,使用命令du -sh * 查看目录下所有的目录和文件大小,可见869M的 temp,如下所示:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 790
790

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









