







目录
三、特征工程
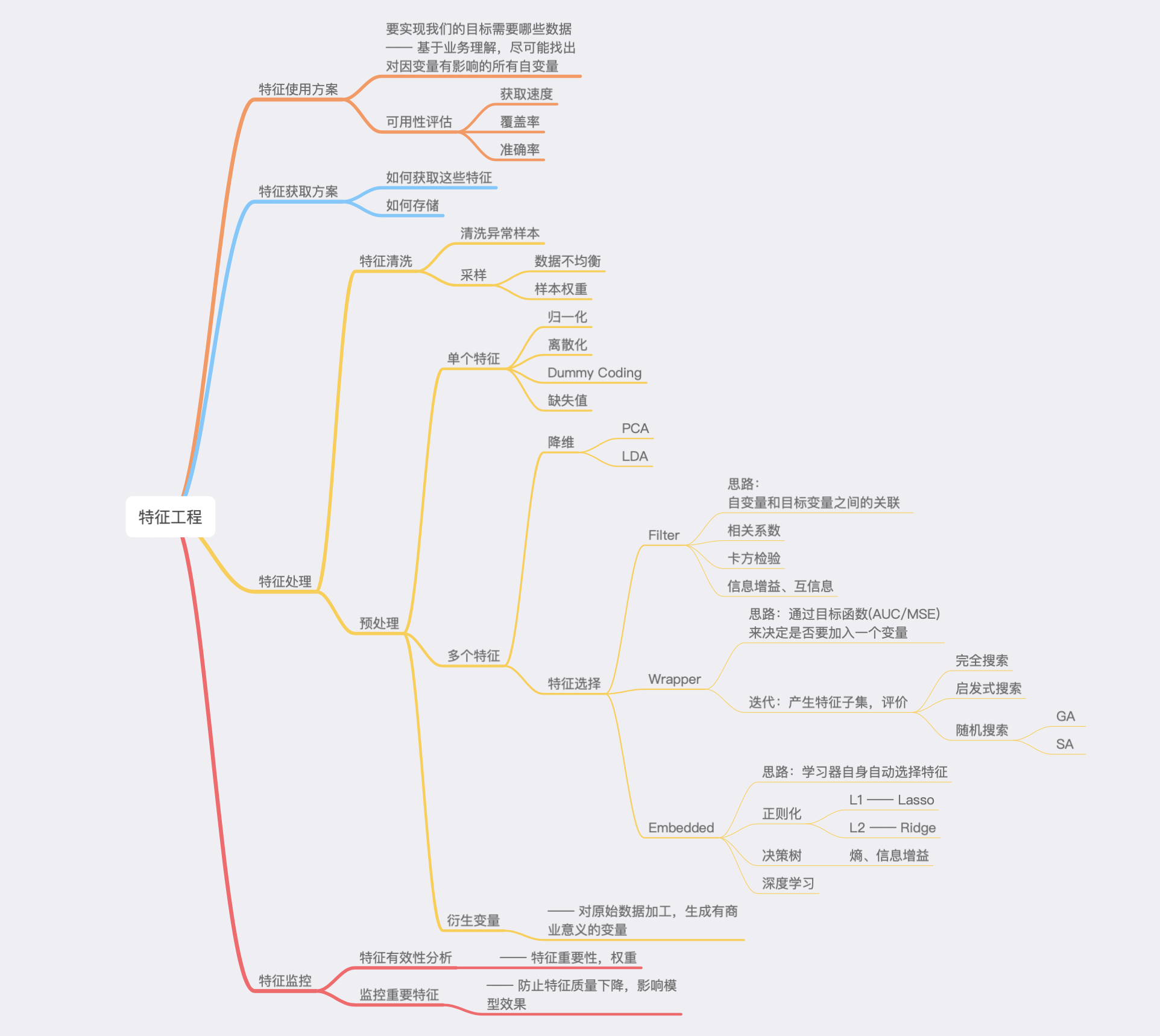
3.1 特征工程概述
“巧妇难为无米之炊”—— 在 ML 中,数据和特征将作“米”,模型和算法则为“妇”。若无数量充分的数据、良好表示的特征,再强大的模型也难以得到满意的结果 (garbage in,garbage out)。因为,数据和特征往往决定了结果的上限,而模型、算法的选择及优化则是在逐步接近该上限。
特征工程,顾名思义,是对原始数据进行一系列工程处理,将其提炼为特征,作为输入供算法和模型使用。在本质上,特征工程是一个表示和展现数据的过程。在实际中,特征工程旨在去除原始数据中的杂质和冗余,设计更高效的特征以刻画求解的问题与预测模型间的关系。
常见的数据类型可分为两大类:
- 结构化数据:可视为关系型数据库的一张表,每列都 有清晰的定义,包含了数值型、类别型两种基本类型;每一行数据表示一个样本的信息
- 非结构化数据:主要包括文本、图像、音频、视频数据,其包含的信息无法用一个简单的数值表示,也没有清晰的类别定义,并且每条数据的大小各不相同
常见的特征类型及其特征工程包括:
- 数值特征:截断、二值化、分桶、缩放、缺失值处理、特征交叉、非线性编码、行统计量等;
- 类别特征:自然数编码、独热编码、分层编码、散列编码、计数编码、计数排名编码、目标编码、类别与类别特征交叉组合、类别u数值特征交叉组合等;
- 时间特征:按类别变量处理、时间变量组合、滞后特征处理、滑动窗口处理等;
- 空间特征:经纬度散列处理、距离计算等;
- 文本特征:语料构建、文本清洗、分词、Skip-Gram 模型、距离/相似度计算、隐语义分析、Word2Vec 等。
流行的特征工程步骤或流程包括:
1. 异常处理:
- 通过箱线图 (或 3-Sigma) 分析删除异常值;
- BOX-COX 转换 (处理有偏分布);
- 长尾截断;
2. 特征归一化/标准化:
- 标准化(转换为标准正态分布);
- 归一化(抓换到 [0,1] 区间);
- 针对幂律分布,可以采用公式:
3. 数据分桶:
- 等频分桶;
- 等距分桶;
- Best-KS 分桶(类似利用基尼指数进行二分类);
- 卡方分桶;
4. 缺失值处理:
- 不处理(针对类似 XGBoost 等树模型);
- 删除(缺失数据太多);
- 插值补全,包括均值/中位数/众数/建模预测/多重插补/压缩感知补全/矩阵补全等;
- 分箱,缺失值一个箱;
5. 特征构造:
- 统计量特征,包括 计数、求和、比例、标准差等;
- 时间特征,包括 相对时间和绝对时间,节假日,双休日等;
- 地理信息,包括 分箱,分布编码等方法;
- 非线性变换,包括 log 变换、平方变换、根号变换等;
- 特征组合、特征交叉;
- 想象能力与业务能力结合的创造性特征构造
6. 特征筛选
- 过滤式 (Filter):先对数据特征选择,再训练学习器,常见方法有 Relief、方差选择法、相关系数法、卡方检验法、互信息法等;
- 包裹式 (Wrapper):直接把最终将使用的学习器的性能作为特征子集的评价准则,常见方法有 拉斯维加斯方法 (Las Vegas Wrapper, LVM) 等;
- 嵌入式 (Embedding):结合过滤式和包裹式,学习器训练过程中自动进行了特征选择,常见方法有 Ridge 回归,Lasso 回归等;
7. 降维
- 成分分析,常见方法有 主成分分析 (PCA)、线性判别分析 (LDA)、独立成分分析 (ICA);
- 特征选择,即通过特征重要性等方式选出特征子集。
3.2 学习目标
- 学习时间序列数据的特征预处理方法
- 学习时间序列特征处理工具 tsfresh (TimeSeries Fresh) 的使用方法
3.3 内容介绍
- 数据预处理
- 处理时间序列数据格式
- 加入时间步特征 time
- 特征工程
- 学习时间序列特征处理库 tsfresh
3.4 代码与理论学习
3.4.1 安装、导入依赖并读取数据
在 jupyter notebook 的一个 cell 中运行 pip 命令安装 tsfresh:
!pip install tsfresh然后,导入包并读取和检查数据集:
# 导入包包
import warnings
warnings.filterwarnings('ignore')
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import tsfresh as tsf
from tsfresh import extract_features, select_features
from tsfresh.utilities.dataframe_functions import impute# 数据读取
data_train = pd.read_csv("./data/train.csv")
data_test_A = pd.read_csv("./data/testA.csv")
# 检查 shape
data_train.shape, data_test_A.shape![]()
# 检查 content
data_train.head()
# 检查 content
data_test_A.head()
确认基本正常,可以继续进行。
3.4.2 数据预处理
1) 查看待分离特征及其数据类型:
data_train_raw_feat = data_train["heartbeat_signals"]
print(type(data_train_raw_feat)) # 查看数据类型
data_train_raw_feat
可见,待分离特征是 Series 类型的。
事实上,pandas 的两个主要数据结构分别是 DataFrame 和 Series,前者不再赘述。Series 类似于一维数组 (Numpy-1darray) 与字典 (Python-dict) 数据结构的结合,其由 一列数据数组 和与之对应的 行索引/下标 (index) 数组 构成,可以根据索引访问对应的样本数据。形式上,Series 的索引在左,数据在右,如上图所示。操作上,类似于 DataFrame,Series 数据同样可通过 点运算符 "." 访问公有数据成员,或调用成员函数查看/修改属性。例如,Series.values 得到数据,Series.index 获取索引,Series.head(n=5) 预览前头 n 条样本,Series.tail(n=5) 查看末尾 n 条样本 ......
2) 接着,分离所需的特征:
# 拆分特征
data_train_split_feat = data_train_raw_feat.str.split(",", expand=True)
data_train_split_feat
其中,调用 Series.str.split() 方法,以逗号 ',' 为间隔分离字符串 (若不指定,默认以空格为间隔分离),并通过令形参 expand=True 将拆分的元素 (沿行按列) 展开为各单独的特征列 (若存在 NaN,则在拆分期间它会在列中传播)。此时,已经是二维的 DataFrame 数据了。
3) 同理,分离测试集的特征:
# 分离测试集特征
data_test_raw_feat = data_test_A["heartbeat_signals"]
data_test_split_feat = data_test_raw_feat.str.split(",", expand=True)
data_test_split_feat
4) 接着,对特征实施 行转列 处理:
# 特征行转列处理
train_heartbeat_df = data_train_split_feat.stack()
train_heartbeat_df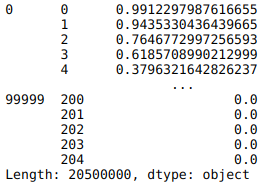
形式上,调用了 DataFrame.stack 方法将通过旋转原先的 DataFrame 的列,返回一个经 reshaped 的 DataFrame (或 Series),且比原先的 DataFrame 具有一至多个层次 (level) 的索引 (index)。
实际中,行转列处理后,出现了两级的索引以及列向量/数组形式堆叠的特征数据。其中,第一级索引无重复 (左往右第 1 列),仍表示样本的序号 (训练-验证集共 100000 条);第二级索引 (左往右第 2 列) 则仍为各样本的特征名,按 0~204 周期重复,表示各样本的 205 个时间步。
5) 然后,重设最外层索引:
# 重置 index
train_heartbeat_df = train_heartbeat_df.reset_index()
train_heartbeat_df 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1006
1006











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









