






任务描述
赛题要解决的核心问题为Lidar-based 3D object detection。但由于赛题没有提供带有标注的样例数据,因此检测算法必须使用现有的、在各种大型3D目标检测数据集上训练好的网络模型,并且对模型的部分超参数进行适当修正。
该算法算法设计整体以评估指标为导向,评估指标包括类别平均的平均正确率(mAP)、类别平均的真正样本(mTP,由平均平移误差ATE、 平均缩放误差ASE和平均方向误差AOE组成)、运动速度均方根误差 (RMSE)和实时性(time)四部分。
其中:
- mAP的计算与常规的评估方法有出入,而赛事组没有给出关于AP具体的计算过程,因此该指标比较难调整。但是该指标对于每个检测类别设置了recall=0.1的硬阈值,并要求每个检测类别的检测召回率须大于0.1才会有此得分,因此在调整代码的过程中,应该优先保证检测结果的召回率。
- mTP由ATE、ASE和AOE三个指标取平均构成,分别表示每个类别中、每个groundtruth与匹配到的检测框的中心偏移误差、边界框尺度误差和边界框偏航角误差。因此,mTP指标与检测结果的IoU评估高度相关。同时该指标也别设置为,每个检测类别的检测召回率须大于0.1才会有得分。因此在调整代码的过程中,应该优先保证检测结果的召回率。
- RMSE强调对于每个目标的绝对速度预测的准确性,并额外要求速度的均方误差须在[0,2]区间内才会计得分。检测框的速度项与其他属性(中心便宜、尺度误差等)不绑定,因此可以独立调整。
- time则要求检测算法的每帧推理延迟不超过150ms(超过计time=0分)。因此,若可以通过TensorRT对算法进行加速推理,那么在该项得分上回占有很大优势。
解决思路
赛题要求检测算法需要输出检测框的以下属性:
[
{
"ObjectID": "0",
"ObjectType": "2",
"Center": {
"CenterX": -7.321467876434326,
"CenterY": 49.28360366821289,
"CenterZ": -0.20517873764038086
},
"Size": {
"ObjectLength": 4.57623291015625,
"ObjectWidth": 1.9087408781051636,
"ObjectHeight": 1.611821174621582
},
"Velocity": 0.1375051335042765,
"Yaw": -1.5993585586547852
},
]
我们计划借助现有的3D目标检测算法,来解决对于目标中心点(Center)、尺度(Size)和偏航角(yaw)的预测;而对于目标运动的绝对速度和偏航角,我们计划在算法的后处理环节进行修正。
为了解决该任务中存在的各种难题,需要从数据、模型、后处理等多个方面考虑。
数据
数据包括训练数据和测试数据。
训练数据
但由于训练数据不可用,所以无法从0开始训练用于赛题评估的网络模型,也无法在已有的模型上微调网络参数。
因此,需要对测试数据进行一定的处理以满足对于模型参数的调优。
测试数据
赛方提供了近30张不带有标注的Lidar点云数据。为了充分利用这些数据,我们根据经验,手动标注出了点云数据中涉及到的目标的信息,包括类别、检测框(中心位置、尺度和偏航角yaw)。对于目标的绝对速度属性,由于该项需要以Lidar车辆的位姿信息为前提并通过计算得到(位姿信息选手不可用),因此无法人工给出标注。
模型
目前已经有很多开源的Lidar-based目标检测模型,并已经在各类大型Lidar点云数据集中(nuscenes、waymo)进行过预训练。因此可以直接用于赛题的目标检测任务。
但根据实验,直接将与训练的模型迁移到赛题数据上进行推理,推理的结果往往不够理想。推测是由于采集数据的雷达不同(顶部雷达vs.前向雷达、32/64线vs.128线等)会使点云数据有内在的偏置属性。
因此,借助测试数据对模型的超参数微调,以及添加适当的后处理过程就十分必要了。
后处理
我们计划使用模型集成(ensemble)来提高原检测算法在竞赛数据上预测的准确性,以尽量提高mAP、mTP指标的评分。
同时,对于目标绝对速度的预测涉及到Lidar坐标系到世界坐标系的转换,而目标的偏航角又与目标在Lidar坐标系中的相对速度强相关,因此在此阶段需要共同处理对于目标速度的偏航角的预测。
为了保证检测算法的时间高效性,还需要借助TensorRT加速推理过程。
算法设计
该算法使用多模型集成预测的方法。具体流程见图1。
-
子模型对场景中的目标进行精确检测,生成一系列原始的多模型预测框。
-
借助提出的预测框融合算法,将粗糙的预测框抑制、删除,并将合格的预测框保留、精炼。
-
按照时间顺序,对相邻场景中的目标预测框进行匹配。
-
借助Lidar车辆的位姿信息,计算出目标在每个时间步下的绝对运动速度,再借助目标的运动方向修正模型预测出的目标偏航角。
-
输出并保存预测框的类别、位置、尺度、速度、偏航角等信息。
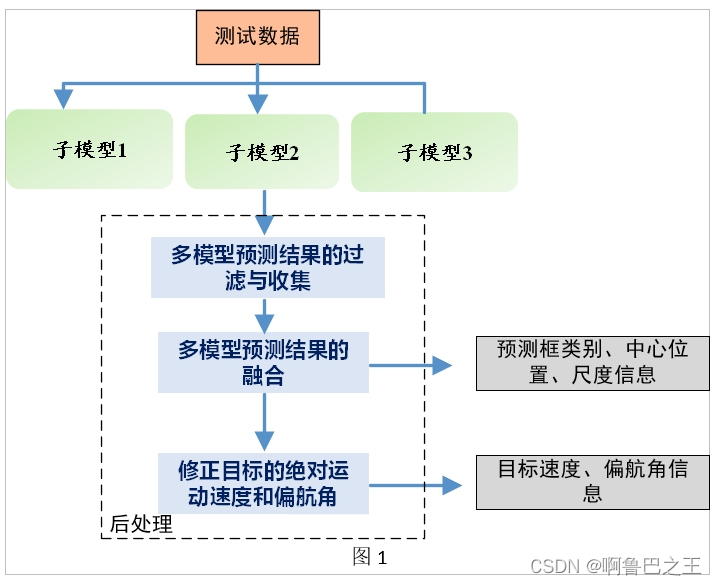
由于缺少带标注的点云数据,我们无法重新训练或调整网络模型的参数,因此本章介绍的重点为模型集成的后处理过程。
代码框架选取
由于需要模型集成,因此选择包含多种检测算法的代码框架对于模型调优和代码修正来说最方面。基于以上考虑,我们选择了mmDetection3D代码库(mmdet3d)作为模型集成的基础。经过大量测试,我们选择代码库中内置的CenterPoint、SSN和PointPillar攻三种算法作为模型集成的子模型,提供基础预测。
数据
mmdet3d中提供了客制化Dataset类的接口,因此可以很轻松地将识别和加载测试数据的方法写入代码库中。
模型
借助于mmdet3d中高度模块化的代码设计,先前选择的CenterPoint、SSN和PointPillar模型可以方便地使用同一套代码进行调用。
后处理
后处理过程分为多模型预测结果的过滤与收集、多模型预测结果的融合、对融合检测框的速度和偏航角的修正三个部分。
多模型预测结果的过滤与收集
该阶段主要负责根据各个子模型的预测框的置信度来过滤检测框。
由于各个子模型的网络结构的不同,它们的预测结果的鲁棒性也不尽相同。例如,我们通过实验发现,CenterPoint对于前背景(目标与其他干扰区域)的检测最不稳定——在将边界框的过滤阈值设为0.2后,模型对于场景内的目标的检测召回率仍然较差,并且会对如路边草丛之类的区域误检。而SSN则最为鲁棒——在将边界框的过滤阈值设为0.05后,模型对于场景内的目标的检测召回率可以达到0.9以上,并且几乎不会对非目标区域误检。PillarPoint则是对于car类别敏感,而容易对于bicycle类别误检。
因此,在收集各个子模型的预测结果时,需要对每个模型单独设置过滤阈值,以保证检测结果的召回率满足mAP和mTP指标中的阈值。经过实验总结,我们将CenterPoint、PillarPoint和SSN的过滤阈值分别设置为0.28、0.15和0.1。
多模型预测结果的融合
我们给出两种边界框融合的方法:非极大值抑制(NMS)和平均融合。
这里的平均融合指的是,将两个或多个边界框的中心点坐标、尺度和偏航角取平均。其中,由于赛题要求偏航角取值为 [ − π , π ] [-\pi,\pi] [−π,π]区间内,因此我们设置平均后的偏航角的方向应与对比中置信度最高的边界框的偏航角方向为基准(从代码整体来看,此处的基准方向并不重要,因为该方向会在后边与速度预测值一起修正)。
需要特别指出的是,尽管我们可以采用soft NMS、soft weight bbox等使用置信度作为权值进行加权融合的操作,但是由于不同模型的预测置信度是不等价的(在上一节中提到),使用模型各自的置信度作为权值可能会导致一定的偏置,这对模型集成的预测结果有一定的影响。
在整个后处理过程中,我们共设置了三次边界框融合。
1. 在多模型预测结果的过滤与收集之后
由于在nuscenes和waymo数据集上预训练的检测模型通常会有数十类别的预测输出,而赛题中要求的检测类别仅有4个,所以需要在“多模型预测结果的过滤与收集”之后对模型预测的检测框的类别进行映射。例如对于nuscenes类别,我们进行以下的映射,其中字符0-4为赛题中定义的类别:
{'car':'2', 'truck':'3', 'trailer':'3', 'bus':'3', 'construction_vehicle':'3', 'bicycle':'1',
'motorcycle':'1', 'pedestrian':'0', 'traffic_cone':'4', 'barrier':'4'}
在进行类别映射后,特定类别会引入新的重叠框,如类别3和类别1,因此需要进行一次NMS操作(我们设置此处NMS的iou阈值为0.2)。
注意:这里NMS使用了置信度排序作为挑选的依据,这是合理的——NMS是在每个模型、预测的每个类别内部进行的,因此置信度具有可比性。
2. 判断多个子模型是否共同预测
经过上一阶段筛选,剩下的边界框会存在以下几种可能:仅被一个子模型预测为属于某一个目标实例、被两个子模型预测为属于某一个目标实例、被三个子模型共同预测为属于某一个目标实例。在这里,我们选择使用多数投票的方式来保留一系列检测框,而将只被一个子模型预测出的边界框过滤掉。
我们设置判断共同检测的依据为IoU大小,即三个子模型对于某一类别目标的预测框,是否有足够大的重叠程度。为此,我们设置两个子模型的预测框IoU大于0.5时为共同预测,三个子模型的预测框IoU大于0.4时为共同预测(设置三个子模型预测IoU阈值耕地的动机是,我们认为判断三个子模型共同预测的条件不应太苛刻,如图2所示)。同时,为了兼顾计算两组边界框的IoU和计算三组边界框的IoU,我们也设计了新的迭代计算IoU的方法,称为Iterative IoU。不同于先前计算IoU的方法,该方法可以计算任意数量的边界框组之间的共同重叠程度,而非只能计算两个边界框组的重叠程度(如torchvision和mmcv中部署的方法)。借助该方法,用于算法集成的子模型的数量理论上也可以扩展到多个。而由于时间和精力的原因,本算法只使用3个子模型。
对于被两个或三个子模型共同预测为属于某一个目标实例的检测框,我们设置它们的融合方法为平均融合。
3. 子模型两两共同预测
在实验中,我们发现会出现以下情况:子模型1与2对某一个目标共同预测(产生bbox1和bbox2),子模型2与3对该目标也共同预测(bbox2和bbox3),但是子模型1、2和3并未对该目标共同预测。具体见图2。
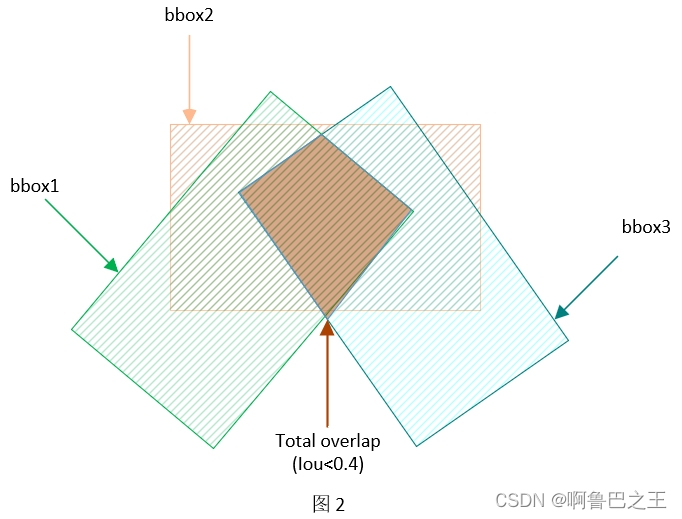
为了处理这种情况,我们将bbox1与bbox2的平均融合结果、bbox2与bbox3的平均融合结果再进行一次平均融合,即bbox1、bbox2和bbox3的加全权重分别为0.25、0.5和0.25。这样做的动机是:在三个bbox均表示同意给目标的前提下,bbox2分别与bbox1和bbox3有较高的重合度,这表明bbox2相比于其他两个能够给出更精确的预测框表示,因此我们赋予bbox更高的加权权重。
修正目标的绝对运动速度和偏航角
在经过“多模型预测结果的融合”步骤之后,我们可以得到一系列相对精确的目标预测框,可以直接用于目标的中心点和尺度的预测。现在,我们将在后处理阶段中的后续步骤中预测和修正目标的速度属性。
为了求取目标的绝对运动速度,我们需要对相邻时间步的场景中预测得到的检测框进行匹配(re-id),将属于特定目标实例的边界框连结,并在后续借助Lidar车辆的位姿信息,将Lidar坐标系中同一目标在不同时间步的空间位置转换到世界坐标系中以求取目标的绝对位移向量。
1. 预测框匹配
在相邻的时间步中,我们选择目标的位置差异作为代价指标(cost)。通过贪心算法,可以将当前时间步中预测的 n n n个目标框与上一时间步预测的 m m m个目标框进行最小代价下的匹配。匹配成功的目标框会加入现有的目标轨迹统计,而匹配失败的目标框则会作为新的目标轨迹的开始并加入轨迹统计。
按照时间步推进的顺序,对融合后的多模型预测框进行逐类别的匹配,可以得到在Lidar坐标系下属于不同目标实例的数个运动轨迹。
2.绝对位移量和绝对运动速度
如图3所示,利用不同时间步 t , t + 1 t,t+1 t,t+1的Lidar车辆位姿信息,可以将不同时间步中预测得到的目标的中心距离 s t , s t + 1 s_{t}, s_{t+1} st,st+1映射到世界坐标系中(东北天坐标系);又借助Lidar车辆的定位信息,通过计算经纬度差可以得到车辆在时间步内的位移向量 x c a r x_{car} xcar,因此目标的绝对位移向量可以通过 x o b j = s t + 1 + x c a r − s t x_{obj}=s_{t+1}+x_{car}-s_t xobj=st+1+xcar−st计算得到。
同时,由于赛题场景中采样的Lidar频率较高(根据提供的测试样例数据,两相邻时间步的时间插值
T
T
T约为0.2ms),因此使用以上计算方法可能会由于误差而使得目标的运动速度突变。因此,我们设置目标的速度更新按照以下公式线性更新:
v
t
+
1
=
v
t
∗
0.3
+
x
o
b
j
T
∗
0.7
v_{t+1}=v_{t} * 0.3 + \frac{x_{obj}}{T} * 0.7
vt+1=vt∗0.3+Txobj∗0.7
此外,根据该计算速度的方法,第一帧(时间步为1)中检测到的目标会计算不到运动速度。由于Lidar数据采集的间隔约为0.2s,因此我们设定首帧中检测到的目标的运动速度等于第而帧中对应目标的运动速度。
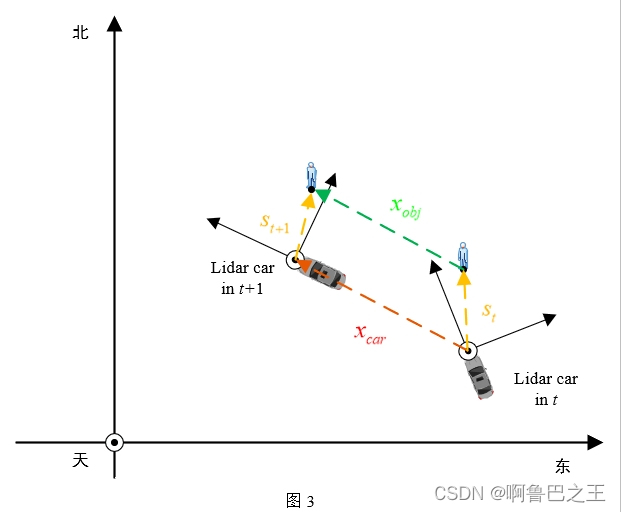
3.修正目标的偏航角
由于赛题为道路场景下的目标检测,因此我们假设:目标运动的瞬时速度方向应与偏航角强相关,即目标总是向着着正前方运动。因此在上一步骤中预测得到的目标速度方向对于目标的偏航角修正具有指导意义。
由于目标的速度方向与位移方向一致,因此我们将上一步骤中计算得到的绝对位移向量 x o b j x_{obj} xobj通过变换矩阵逆映射回 t + 1 t+1 t+1时间步下的Lidar坐标系中( x o b j ′ x'_{obj} xobj′)。通过将位移向量 x o b j ′ x'_{obj} xobj′的方向与融合后的多模型预测的偏航角yaw进行加权平均,我们可以得到最终用于输出的目标偏航角预测值。
注意:模型预测的偏航角方向可能与位移方向相反(即角度差的绝对值大于 π 2 \frac{\pi}{2} 2π),此时我们选择位移方向为基准方向,并将先前预测的偏航角方向加或减 π 2 \frac{\pi}{2} 2π后再与位移方向加权平均。
至此,我们便得到了用于评估检测算法性能的所有输出量,包括:
[
“ObjectID”, # 在后处理阶段给出中
“ObjectType”, # 由模型预测给出
“Center”, # 由模型预测给出
“Size”, # 由模型预测给出
“Velocity”, # 由后处理阶段计算得出
“Yaw”, # 由模型预测给出并再后处理阶段修正
]
一点分享
个人认为,对于任何机器学习相关的目标检测类别的比赛,如果赛题对于算法的运行速度没有绝对性的要求,那么一定要使用模型集成的方法。这种方法能够以时间换取精度,极大提高算法的检测性能。

如图4,我们可视化了三个子模型以及集成的模型在同一场景下的检测结果,其中红色框表示行人,绿色框表示骑自行车/电动车的人,深蓝色框表示小型车,黄色框表示大型车,青蓝色框表示障碍物。
可以非常明显地看到,由于使用了按多数投票来集成预测的方法,每一个子模型预测出的杂乱的、非目标框能够被有效过滤,而至少两个子模型共同预测的目标框能够融合并保留,从而整个集成模型可以为目标生成一个精确的检测框。
代码将会按照比赛要求,在完全结束之后开源在GitHub中:https://github.com/qq1018408006/Lidar-based-3D-object-detection-in-closed-parks















 1564
1564











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









