






Transformer+Detection:引入视觉领域的首创DETR
论文名称:End-to-End Object Detection with Transformers
论文地址:https://arxiv.org/abs/2005.12872
重要的图要经常出现,下图就是:
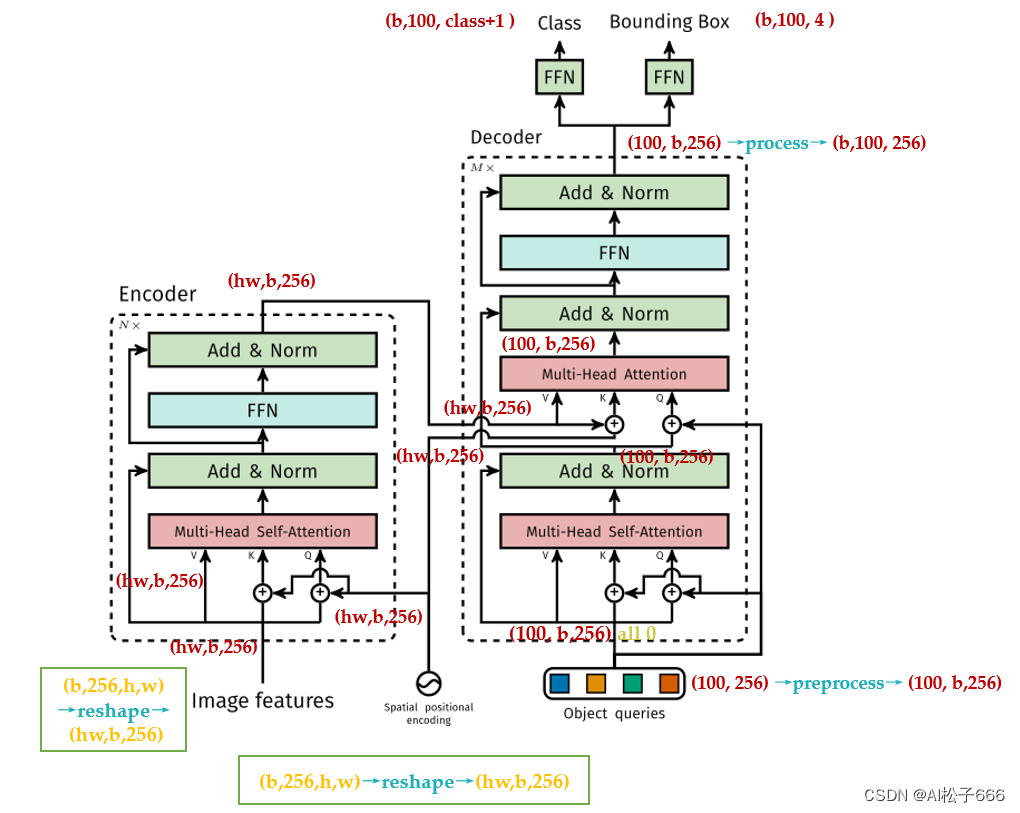
DETR原理分析
网络架构部分解读
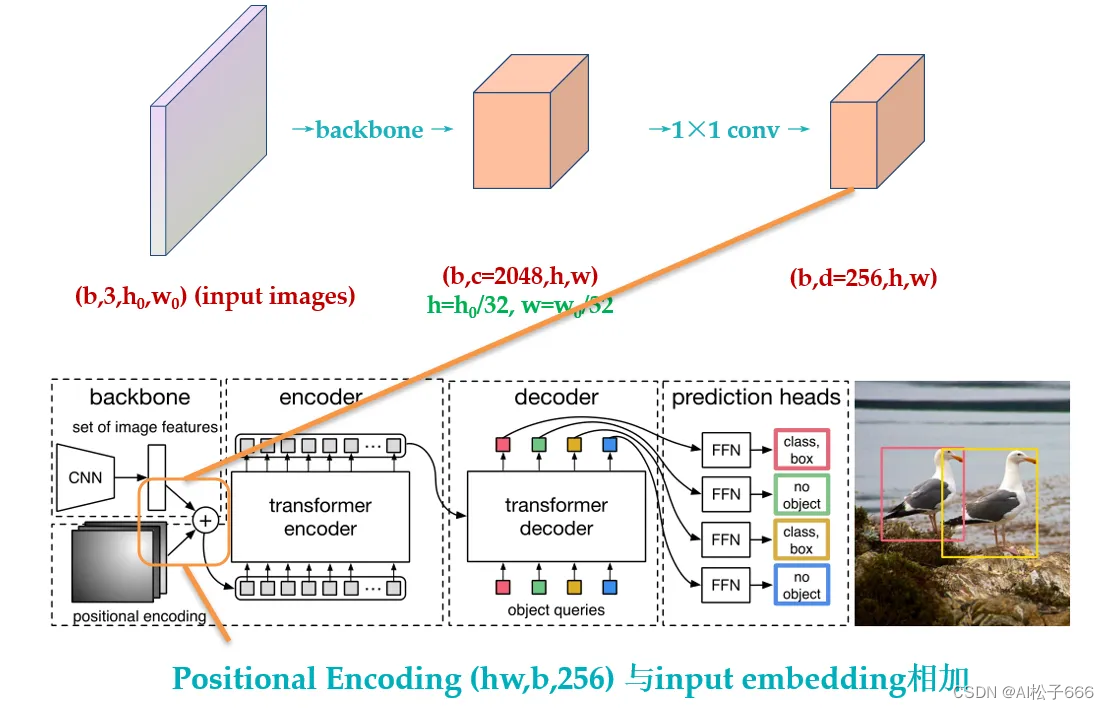
本文的任务是Object detection,用到的工具是Transformers,特点是End-to-end。
目标检测的任务是要去预测一系列的Bounding Box的坐标以及Label, 现代大多数检测器通过定义一些proposal,anchor或者windows,把问题构建成为一个分类和回归问题来间接地完成这个任务。**文章所做的工作,就是将transformers运用到了object detection领域,取代了现在的模型需要手工设计的工作,并且取得了不错的结果。**在object detection上DETR准确率和运行时间上和Faster RCNN相当;将模型 generalize 到 panoptic segmentation 任务上,DETR表现甚至还超过了其他的baseline。DETR第一个使用End to End的方式解决检测问题,解决的方法是把检测问题视作是一个set prediction problem,如下图29所示。

网络的主要组成是CNN和Transformer,Transformer借助第1节讲到的self-attention机制,可以显式地对一个序列中的所有elements两两之间的interactions进行建模,使得这类transformer的结构非常适合带约束的set prediction的问题。DETR的特点是:一次预测,端到端训练,set loss function和二分匹配。
文章的主要有两个关键的部分。
第一个是用transformer的encoder-decoder架构一次性生成 N个box prediction。其中N是一个事先设定的、比远远大于image中object个数的一个整数。
第二个是设计了bipartite matching loss,基于预测的boxex和ground truth boxes的二分图匹配计算loss的大小,从而使得预测的box的位置和类别更接近于ground truth。
DETR整体结构可以分为四个部分:backbone,encoder,decoder和FFN,如下图所示,以下分别解释这四个部分:
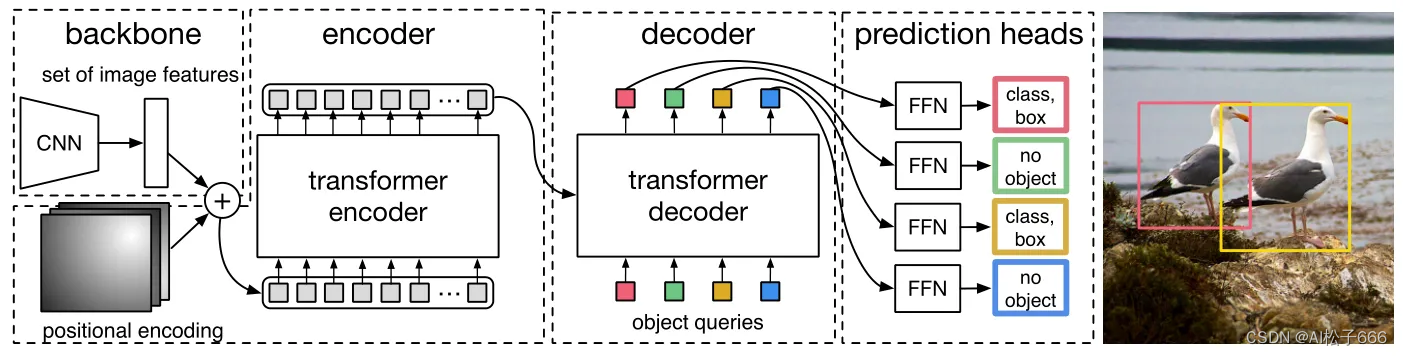
backbone

encoder

进行完位置编码以后根据paper中的图片会有个相加的过程,如下图问号处所示。很多读者有疑问的地方是:下图中相加的2个张量,一个是input embedding,另一个是位置编码维度看上去不一致,是怎么相加的?后面会解答。
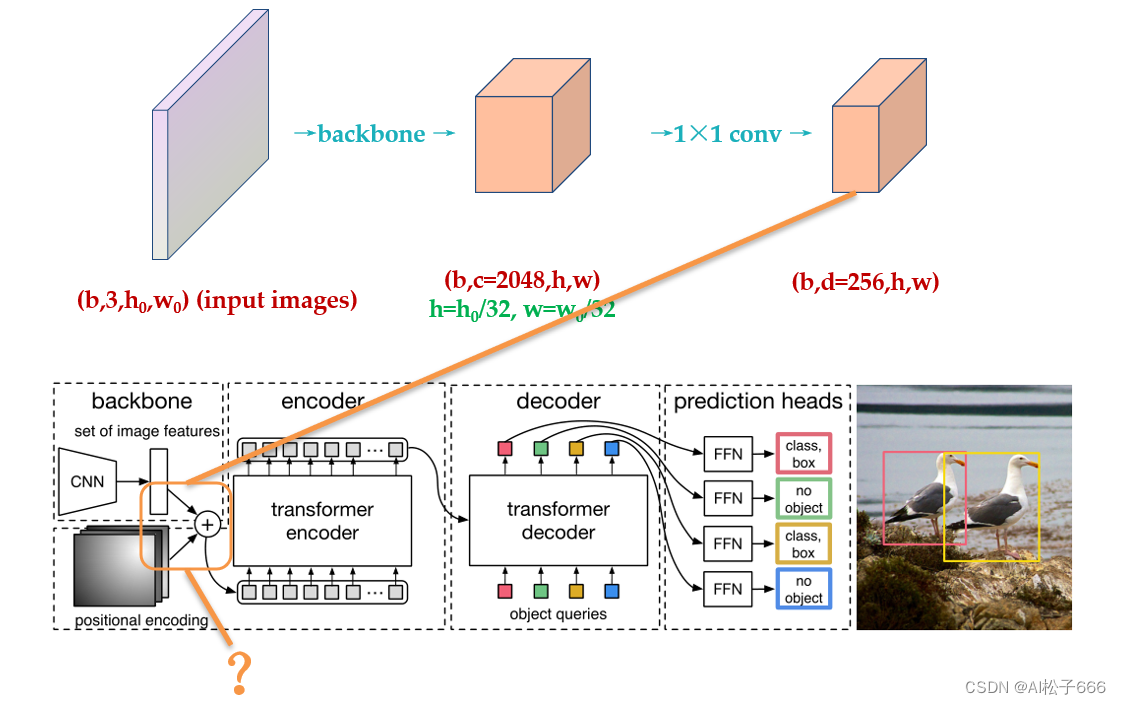


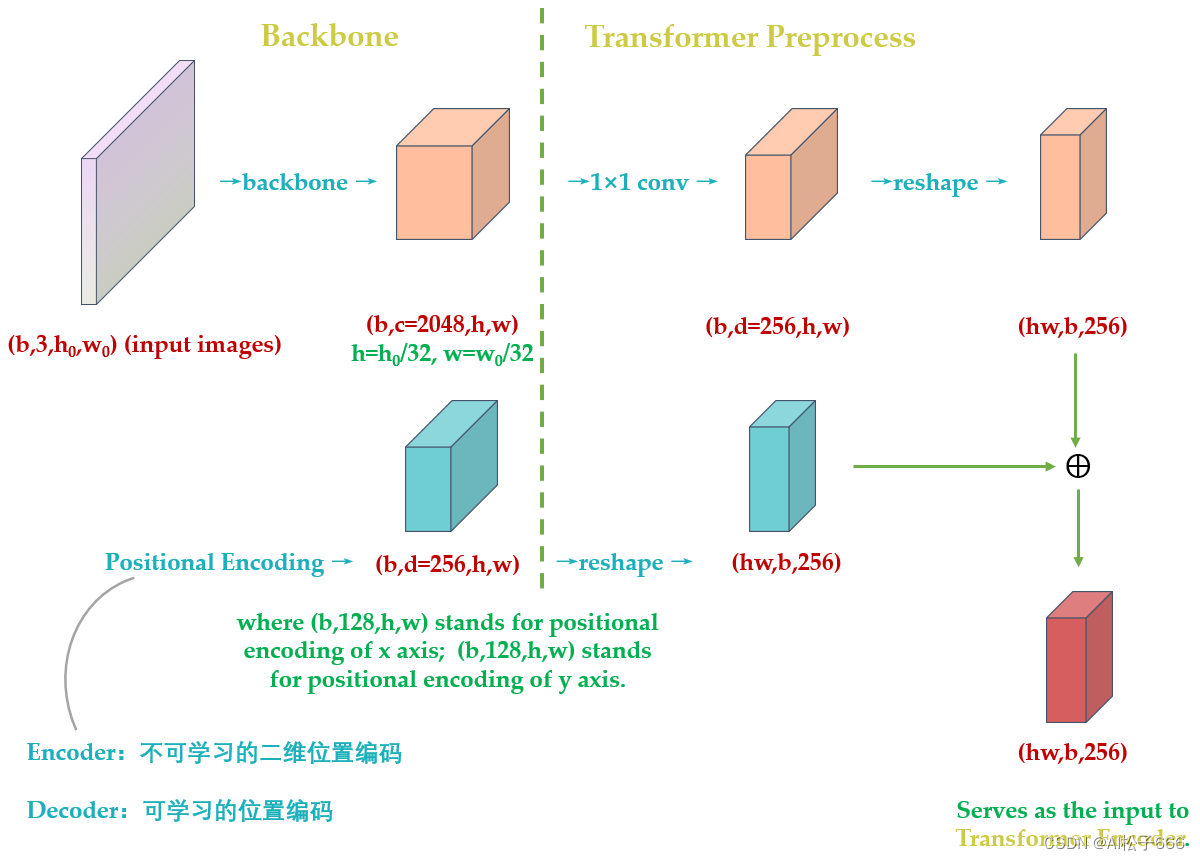
所以,了解了DETR的位置编码之后,你应该明白了其实input embedding和位置编码维度其实是一样的,只是论文图示为了突出二位编码所以画的不一样罢了,如下图33所示:

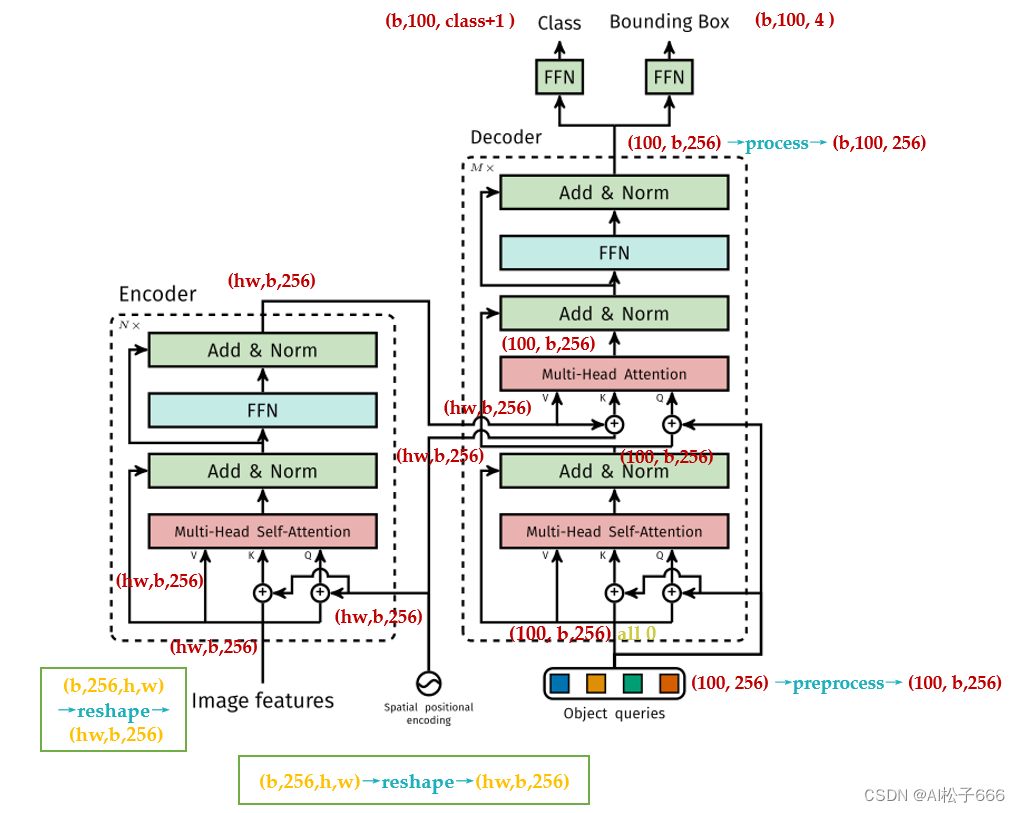
decoder
再看decoder:
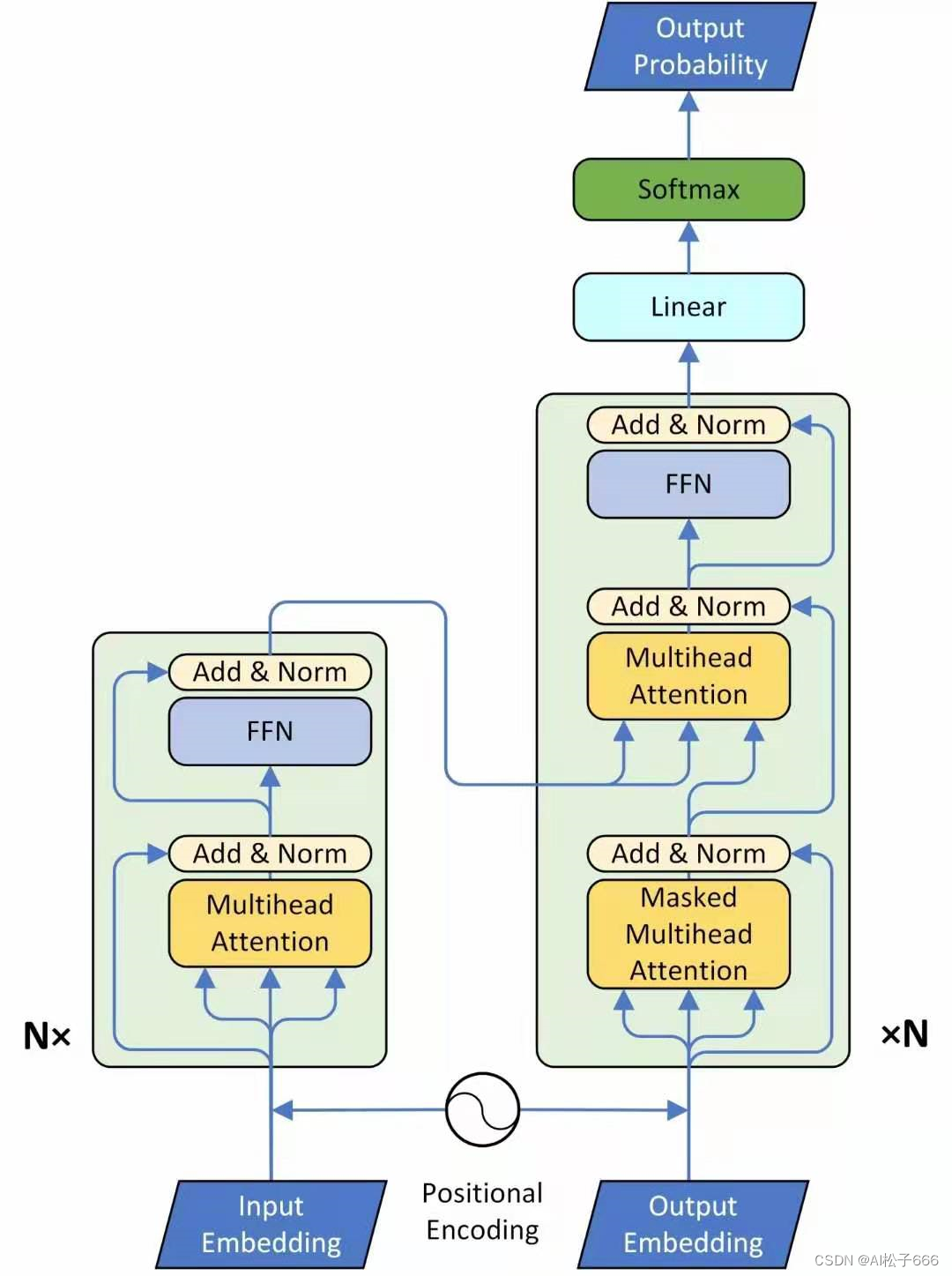
DETR的Decoder和原版Transformer的decoder是不太一样的,如下图34和21所示。
先回忆下原版Transformer,看下图21的decoder的最后一个框:output probability,代表我们一次只产生一个单词的softmax,根据这个softmax得到这个单词的预测结果。这个过程我们表达为:predicts the output sequence one element at a time。
不同的是,DETR的Transformer Decoder是一次性处理全部的object queries,即一次性输出全部的predictions;而不像原始的Transformer是auto-regressive的,从左到右一个词一个词地输出。这个过程我们表达为:decodes the N objects in parallel at each decoder layer。
DETR的Decoder主要有两个输入:
1.Transformer Encoder输出的Embedding与 position encoding 之和。
2.Object queries。


损失函数部分解读:



最后,再概括一下DETR的End-to-End的原理,前面那么多段话就是为了讲明白这个事情,如果你对前面的论述还存在疑问的话,把下面一直到Experiments之前的这段话看懂就能解决你的困惑。



DETR代码解读
DETR代码解读:https://github.com/facebookresearch/detr
分析都注释在了代码中。

class PositionEmbeddingSine(nn.Module):
def forward(self, tensor_list: NestedTensor):
#输入是b,c,h,w
#tensor_list的类型是NestedTensor,内部自动附加了mask,
#用于表示动态shape,是pytorch中tensor新特性https://github.com/pytorch/nestedtensor
x = tensor_list.tensors
# 附加的mask,shape是b,h,w 全是false
mask = tensor_list.mask
assert mask is not None
not_mask = ~mask
# 因为图像是2d的,所以位置编码也分为x,y方向
# 1 1 1 1 .. 2 2 2 2... 3 3 3...
y_embed = not_mask.cumsum(1, dtype=torch.float32)
# 1 2 3 4 ... 1 2 3 4...
x_embed = not_mask.cumsum(2, dtype=torch.float32)
if self.normalize:
eps = 1e-6
y_embed = y_embed / (y_embed[:, -1:, :] + eps) * self.scale
x_embed = x_embed / (x_embed[:, :, -1:] + eps) * self.scale
# num_pos_feats = 128
# 0~127 self.num_pos_feats=128,因为前面输入向量是256,编码是一半sin,一半cos
dim_t = torch.arange(self.num_pos_feats, dtype=torch.float32, device=x.device)
dim_t = self.temperature ** (2 * (dim_t // 2) / self.num_pos_feats)
# 输出shape=b,h,w,128
pos_x = x_embed[:, :, :, None] / dim_t
pos_y = y_embed[:, :, :, None] / dim_t
pos_x = torch.stack((pos_x[:, :, :, 0::2].sin(), pos_x[:, :, :, 1::2].cos()), dim=4).flatten(3)
pos_y = torch.stack((pos_y[:, :, :, 0::2].sin(), pos_y[:, :, :, 1::2].cos()), dim=4).flatten(3)
pos = torch.cat((pos_y, pos_x), dim=3).permute(0, 3, 1, 2)
# 每个特征图的xy位置都编码成256的向量,其中前128是y方向编码,而128是x方向编码
return pos
# b,n=256,h,w
作者定义了一种数据结构:NestedTensor,里面打包存了两个变量:x 和mask。
NestedTensor:
里面打包存了两个变量:x 和mask。
to()函数:把变量移到GPU中。
Backbone
class BackboneBase(nn.Module):
def __init__(self, backbone: nn.Module, train_backbone: bool, num_channels: int, return_interm_layers: bool):
super().__init__()
for name, parameter in backbone.named_parameters():
if not train_backbone or 'layer2' not in name and 'layer3' not in name and 'layer4' not in name:
parameter.requires_grad_(False)
if return_interm_layers:
return_layers = {"layer1": "0", "layer2": "1", "layer3": "2", "layer4": "3"}
else:
return_layers = {'layer4': "0"}
#作用的模型:定义BackboneBase时传入的nn.Moduleclass的backbone,返回的layer:来自bool变量return_interm_layers
self.body = IntermediateLayerGetter(backbone, return_layers=return_layers)
self.num_channels = num_channels
def forward(self, tensor_list: NestedTensor):
#BackboneBase的输入是一个NestedTensor
#xs中间层的输出,
xs = self.body(tensor_list.tensors)
out: Dict[str, NestedTensor] = {}
for name, x in xs.items():
m = tensor_list.mask
assert m is not None
#F.interpolate上下采样,调整mask的size
#to(torch.bool) 把mask转化为Bool型变量
mask = F.interpolate(m[None].float(), size=x.shape[-2:]).to(torch.bool)[0]
out[name] = NestedTensor(x, mask)
return out
class Backbone(BackboneBase):
"""ResNet backbone with frozen BatchNorm."""
def __init__(self, name: str,
train_backbone: bool,
return_interm_layers: bool,
dilation: bool):
#根据name选择backbone, num_channels, return_interm_layers等,传入BackboneBase初始化
backbone = getattr(torchvision.models, name)(
replace_stride_with_dilation=[False, False, dilation],
pretrained=is_main_process(), norm_layer=FrozenBatchNorm2d)
num_channels = 512 if name in ('resnet18', 'resnet34') else 2048
super().__init__(backbone, train_backbone, num_channels, return_interm_layers)
把Backbone和之前的PositionEmbeddingSine连在一起:
Backbone完以后输出(b,c,h,w),再经过PositionEmbeddingSine输出(b,H,W,256)。
class Joiner(nn.Sequential):
def __init__(self, backbone, position_embedding):
super().__init__(backbone, position_embedding)
def forward(self, tensor_list: NestedTensor):
xs = self[0](tensor_list)
out: List[NestedTensor] = []
pos = []
for name, x in xs.items():
out.append(x)
# position encoding
pos.append(self[1](x).to(x.tensors.dtype))
return out, pos
def build_backbone(args):
#position_embedding是个nn.module
position_embedding = build_position_encoding(args)
train_backbone = args.lr_backbone > 0
return_interm_layers = args.masks
#backbone是个nn.module
backbone = Backbone(args.backbone, train_backbone, return_interm_layers, args.dilation)
#nn.Sequential在一起
model = Joiner(backbone, position_embedding)
model.num_channels = backbone.num_channels
return model
Transformer的一个Encoder Layer:
class TransformerEncoderLayer(nn.Module):
def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1,
activation="relu", normalize_before=False):
super().__init__()
self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
# Implementation of Feedforward model
self.linear1 = nn.Linear(d_model, dim_feedforward)
self.dropout = nn.Dropout(dropout)
self.linear2 = nn.Linear(dim_feedforward, d_model)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.activation = _get_activation_fn(activation)
self.normalize_before = normalize_before
def with_pos_embed(self, tensor, pos: Optional[Tensor]):
return tensor if pos is None else tensor + pos
def forward_post(self,
src,
src_mask: Optional[Tensor] = None,
src_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None):
# 和标准做法有点不一样,src加上位置编码得到q和k,但是v依然还是src,
# 也就是v和qk不一样
q = k = self.with_pos_embed(src, pos)
src2 = self.self_attn(q, k, value=src, attn_mask=src_mask,
key_padding_mask=src_key_padding_mask)[0]
#Add and Norm
src = src + self.dropout1(src2)
src = self.norm1(src)
#FFN
src2 = self.linear2(self.dropout(self.activation(self.linear1(src))))
#Add and Norm
src = src + self.dropout2(src2)
src = self.norm2(src)
return src
def forward_pre(self, src,
src_mask: Optional[Tensor] = None,
src_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None):
src2 = self.norm1(src)
q = k = self.with_pos_embed(src2, pos)
src2 = self.self_attn(q, k, value=src2, attn_mask=src_mask,
key_padding_mask=src_key_padding_mask)[0]
src = src + self.dropout1(src2)
src2 = self.norm2(src)
src2 = self.linear2(self.dropout(self.activation(self.linear1(src2))))
src = src + self.dropout2(src2)
return src
def forward(self, src,
src_mask: Optional[Tensor] = None,
src_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None):
if self.normalize_before:
return self.forward_pre(src, src_mask, src_key_padding_mask, pos)
return self.forward_post(src, src_mask, src_key_padding_mask, pos)
有了一个Encoder Layer的定义,再看Transformer的整个Encoder:
class TransformerEncoder(nn.Module):
def __init__(self, encoder_layer, num_layers, norm=None):
super().__init__()
# 编码器copy6份
self.layers = _get_clones(encoder_layer, num_layers)
self.num_layers = num_layers
self.norm = norm
def forward(self, src,
mask: Optional[Tensor] = None,
src_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None):
# 内部包括6个编码器,顺序运行
# src是图像特征输入,shape=hxw,b,256
output = src
for layer in self.layers:
# 第一个编码器输入来自图像特征,后面的编码器输入来自前一个编码器输出
output = layer(output, src_mask=mask,
src_key_padding_mask=src_key_padding_mask, pos=pos)
return output
Object Queries:可学习的位置编码:
注释中已经注明了变量的shape的变化过程,最终输出的是与Positional Encoding维度相同的位置编码,维度是(b,H,W,256),只是现在这个位置编码是可学习的了。
class PositionEmbeddingLearned(nn.Module):
"""
Absolute pos embedding, learned.
"""
def __init__(self, num_pos_feats=256):
super().__init__()]
#这里使用了nn.Embedding,这是一个矩阵类,里面初始化了一个随机矩阵,矩阵的长是字典的大小,宽是用来表示字典中每个元素的属性向量,
# 向量的维度根据你想要表示的元素的复杂度而定。类实例化之后可以根据字典中元素的下标来查找元素对应的向量。输入下标0,输出就是embeds矩阵中第0行。
self.row_embed = nn.Embedding(50, num_pos_feats)
self.col_embed = nn.Embedding(50, num_pos_feats)
self.reset_parameters()
def reset_parameters(self):
nn.init.uniform_(self.row_embed.weight)
nn.init.uniform_(self.col_embed.weight)
#输入依旧是NestedTensor
def forward(self, tensor_list: NestedTensor):
x = tensor_list.tensors
h, w = x.shape[-2:]
i = torch.arange(w, device=x.device)
j = torch.arange(h, device=x.device)
#x_emb:(w, 128)
#y_emb:(h, 128)
x_emb = self.col_embed(i)
y_emb = self.row_embed(j)
pos = torch.cat([
x_emb.unsqueeze(0).repeat(h, 1, 1),#(1,w,128) → (h,w,128)
y_emb.unsqueeze(1).repeat(1, w, 1),#(h,1,128) → (h,w,128)
], dim=-1).permute(2, 0, 1).unsqueeze(0).repeat(x.shape[0], 1, 1, 1)
#(h,w,256) → (256,h,w) → (1,256,h,w) → (b,256,h,w)
return pos
def build_position_encoding(args):
N_steps = args.hidden_dim // 2
if args.position_embedding in ('v2', 'sine'):
# TODO find a better way of exposing other arguments
position_embedding = PositionEmbeddingSine(N_steps, normalize=True)
elif args.position_embedding in ('v3', 'learned'):
position_embedding = PositionEmbeddingLearned(N_steps)
else:
raise ValueError(f"not supported {args.position_embedding}")
return position_embedding
Transformer的一个Decoder Layer:
注意变量的命名:
object queries(query_pos)
Encoder的位置编码(pos)
Encoder的输出(memory)
def forward_post(self, tgt, memory,
tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
query_pos: Optional[Tensor] = None):
#query,key的输入是object queries(query_pos) + Decoder的输入(tgt),shape都是(100,b,256)
#value的输入是Decoder的输入(tgt),shape = (100,b,256)
q = k = self.with_pos_embed(tgt, query_pos)
#Multi-head self-attention
tgt2 = self.self_attn(q, k, value=tgt, attn_mask=tgt_mask,
key_padding_mask=tgt_key_padding_mask)[0]
#Add and Norm
tgt = tgt + self.dropout1(tgt2)
tgt = self.norm1(tgt)
#query的输入是上一个attention的输出(tgt) + object queries(query_pos)
#key的输入是Encoder的位置编码(pos) + Encoder的输出(memory)
#value的输入是Encoder的输出(memory)
tgt2 = self.multihead_attn(query=self.with_pos_embed(tgt, query_pos),
key=self.with_pos_embed(memory, pos),
value=memory, attn_mask=memory_mask,
key_padding_mask=memory_key_padding_mask)[0]
#Add and Norm
tgt = tgt + self.dropout2(tgt2)
tgt = self.norm2(tgt)
#FFN
tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt))))
tgt = tgt + self.dropout3(tgt2)
tgt = self.norm3(tgt)
return tgt
def forward_pre(self, tgt, memory,
tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
query_pos: Optional[Tensor] = None):
tgt2 = self.norm1(tgt)
q = k = self.with_pos_embed(tgt2, query_pos)
tgt2 = self.self_attn(q, k, value=tgt2, attn_mask=tgt_mask,
key_padding_mask=tgt_key_padding_mask)[0]
tgt = tgt + self.dropout1(tgt2)
tgt2 = self.norm2(tgt)
tgt2 = self.multihead_attn(query=self.with_pos_embed(tgt2, query_pos),
key=self.with_pos_embed(memory, pos),
value=memory, attn_mask=memory_mask,
key_padding_mask=memory_key_padding_mask)[0]
tgt = tgt + self.dropout2(tgt2)
tgt2 = self.norm3(tgt)
tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt2))))
tgt = tgt + self.dropout3(tgt2)
return tgt
def forward(self, tgt, memory,
tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
query_pos: Optional[Tensor] = None):
if self.normalize_before:
return self.forward_pre(tgt, memory, tgt_mask, memory_mask,
tgt_key_padding_mask, memory_key_padding_mask, pos, query_pos)
return self.forward_post(tgt, memory, tgt_mask, memory_mask,
tgt_key_padding_mask, memory_key_padding_mask, pos, query_pos)
有了一个Decoder Layer的定义,再看Transformer的整个Decoder:
class TransformerDecoder(nn.Module):
#值得注意的是:在使用TransformerDecoder时需要传入的参数有:
# tgt:Decoder的输入,memory:Encoder的输出,pos:Encoder的位置编码的输出,query_pos:Object Queries,一堆mask
def forward(self, tgt, memory,
tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
query_pos: Optional[Tensor] = None):
output = tgt
# Decoder输入的tgt:(100, b, 256)
intermediate = []
for layer in self.layers:
output = layer(output, memory, tgt_mask=tgt_mask,
memory_mask=memory_mask,
tgt_key_padding_mask=tgt_key_padding_mask,
memory_key_padding_mask=memory_key_padding_mask,
pos=pos, query_pos=query_pos)
if self.return_intermediate:
intermediate.append(self.norm(output))
if self.norm is not None:
output = self.norm(output)
if self.return_intermediate:
intermediate.pop()
intermediate.append(output)
if self.return_intermediate:
return torch.stack(intermediate)
return output.unsqueeze(0)
然后是把Encoder和Decoder拼在一起,即总的Transformer结构的实现:
此处考虑到字数限制,省略了代码。
实现了Transformer,还剩后面的FFN:
class MLP(nn.Module):
""" Very simple multi-layer perceptron (also called FFN)"""
def __init__(self, input_dim, hidden_dim, output_dim, num_layers):
super().__init__()
self.num_layers = num_layers
h = [hidden_dim] * (num_layers - 1)
self.layers = nn.ModuleList(nn.Linear(n, k) for n, k in zip([input_dim] + h, h + [output_dim]))
def forward(self, x):
for i, layer in enumerate(self.layers):
x = F.relu(layer(x)) if i < self.num_layers - 1 else layer(x)
return x

# pred_logits:[b,100,92]
# pred_boxes:[b,100,4]
# targets是个长度为b的list,其中的每个元素是个字典,共包含:labels-长度为(m,)的Tensor,元素是标签;boxes-长度为(m,4)的Tensor,元素是Bounding Box。
# detr分类输出,num_queries=100,shape是(b,100,92)
bs, num_queries = outputs["pred_logits"].shape[:2]
# We flatten to compute the cost matrices in a batch
out_prob = outputs["pred_logits"].flatten(0, 1).softmax(-1) # [batch_size * num_queries, num_classes] = [100b, 92]
out_bbox = outputs["pred_boxes"].flatten(0, 1) # [batch_size * num_queries, 4] = [100b, 4]
# 准备分类target shape=(m,)里面存储的是类别索引,m包括了整个batch内部的所有gt bbox
# Also concat the target labels and boxes
tgt_ids = torch.cat([v["labels"] for v in targets])# (m,)[3,6,7,9,5,9,3]
# 准备bbox target shape=(m,4),已经归一化了
tgt_bbox = torch.cat([v["boxes"] for v in targets])# (m,4)
#(100b,92)->(100b, m),对于每个预测结果,把目前gt里面有的所有类别值提取出来,其余值不需要参与匹配
#对应上述公式,类似于nll loss,但是更加简单
# Compute the classification cost. Contrary to the loss, we don't use the NLL,
# but approximate it in 1 - proba[target class].
# The 1 is a constant that doesn't change the matching, it can be ommitted.
#行:取每一行;列:只取tgt_ids对应的m列
cost_class = -out_prob[:, tgt_ids]# (100b, m)
# Compute the L1 cost between boxes, 计算out_bbox和tgt_bbox两两之间的l1距离 (100b, m)
cost_bbox = torch.cdist(out_bbox, tgt_bbox, p=1)# (100b, m)
# Compute the giou cost betwen boxes, 额外多计算一个giou loss (100b, m)
cost_giou = -generalized_box_iou(box_cxcywh_to_xyxy(out_bbox), box_cxcywh_to_xyxy(tgt_bbox))
#得到最终的广义距离(100b, m),距离越小越可能是最优匹配
# Final cost matrix
C = self.cost_bbox * cost_bbox + self.cost_class * cost_class + self.cost_giou * cost_giou
#(100b, m)--> (b, 100, m)
C = C.view(bs, num_queries, -1).cpu()
#计算每个batch内部有多少物体,后续计算时候按照单张图片进行匹配,没必要batch级别匹配,徒增计算
sizes = [len(v["boxes"]) for v in targets]
#匈牙利最优匹配,返回匹配索引
#enumerate(C.split(sizes, -1))]:(b,100,image1,image2,image3,...)
indices = [linear_sum_assignment(c[i]) for i, c in enumerate(C.split(sizes, -1))]
return [(torch.as_tensor(i, dtype=torch.int64), torch.as_tensor(j, dtype=torch.int64)) for i, j in indices]

参考文档:https://zhuanlan.zhihu.com/p/340149804















 788
788











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









