







本章帮助网络工程师或架构师回答如下问题:
- 什么是网络虚拟化?
- 网络虚拟化有哪些用途?
- 网络虚拟化领域内有哪些不同的技术方向?
- 网络虚拟化的控制面有哪些选择?
- 当使用 VXLAN 时如何进行桥接和路由?
什么是网络虚拟化?
网络虚拟化可以让网络运营者将一个物理网络划分为多个互相隔离的虚拟网络。
在分组网络中,每一个虚拟网络总是认为自己拥有以下资源:
- 接口或者链接
- 转发表
- 其他类型的表,比如用于执行强制策略 (例如,接入控制) 以及用于完成其他数据包处理(比如,网络地址转换[NAT])。
- 数据包级缓存以及链路队列
在更高的抽象层级,每一个虚拟网络都认为除了自身没有其他网络的存在。为了允许存在这种幻想,每一个虚拟网络都和其他虚拟网络彼此隔离。为了让拥有所有地址空间的幻想成真,一个数据包转发表会按照多个虚拟网络进行划分。为了确保虚拟网络的流量彼此隔离,要么将一个网络接口完全分配给某一个虚拟网络,要么为共享该链路的每个虚拟网络逻辑地划分出一个接口。
网络虚拟化在数据中心的应用
在当代数据中心,网络虚拟化主要有以下应用场景
- 强制流量经过特定的服务
- 在三层网络上提供二层连接
- 多租户
- 使交换机的管理流量和数据流量分离
强制将流量路由到特定路径上
第一个用例是使用网络虚拟化强制将流量路由到提供特定服务的节点上去。
展示了这种用例的一种典型设计。图6-1(a)展示了外部网络和单一内部网络的物理连接。图6-1(b)展示了通过为外部网络和内部网终创建分离的单一虚拟网终来实现网络隔离。内部网络和外部网络之间的流量必须通过防火墙,因为防火墙是唯一和内部网络及外部网络都有连接的网络节点。图6-1(b)也许看起来像一个传统的防火墙,但是这里的两个边缘路由器实际上是同一台路由器。它的路由表分成两部分,路由器的一侧(内部网络) 并不与另一侧 (外部网络) 直接通信。
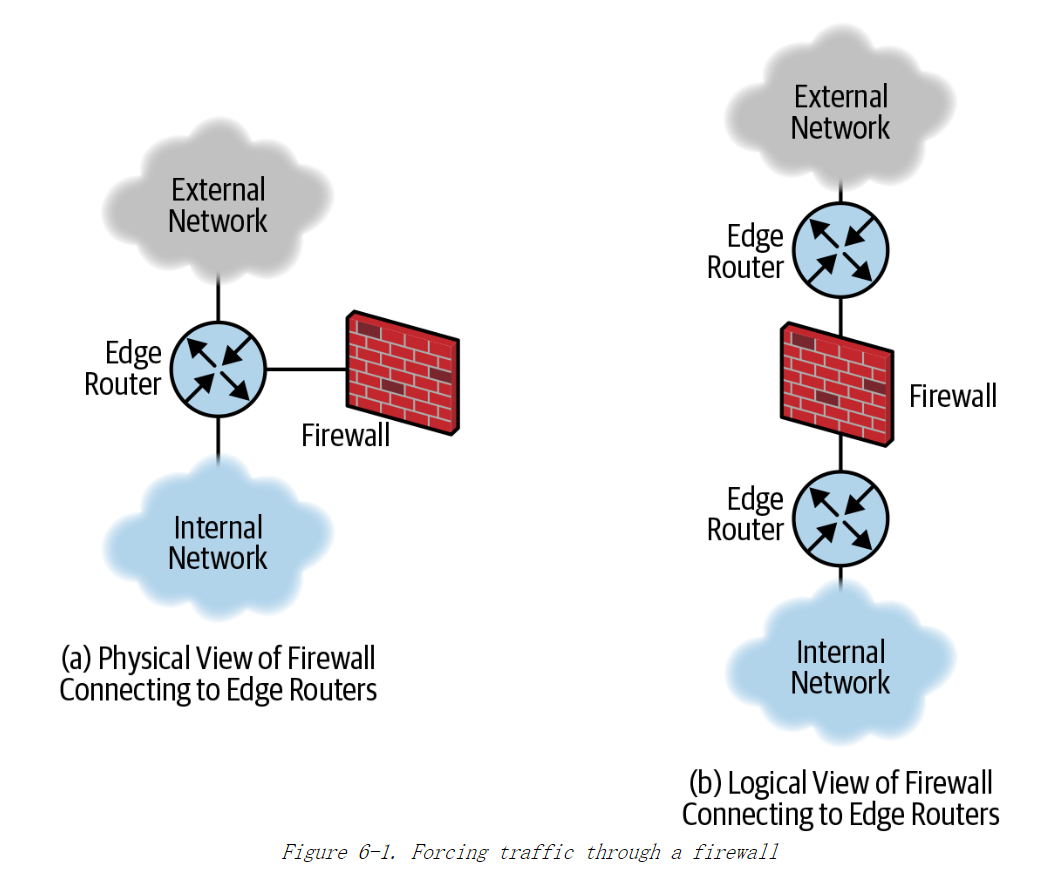
如果有多个内部网络,每一个内部网络都和外部网络采取不同的策略进行通信,那么创建多个虚拟网络是针对这种用例的常用的解决方案
当某个需求强制要求流量符合某个策略,即只有特定类别的流量被显式地授权之后才能真正进行节点之间的通信,那么网络虚拟化针对这类用例是很有价值的。
需要二层网络互联的应用程序
云
云本身就是支持多租户的,因为云服务提供商基于通用及共享的计算或网络基础设施来支持多个客户。网络虚拟化是支持此用例的基础技术。
交换机的管理网络和数据网络的分离
在数据中心内,网络虚拟化最普遍的使用方法是交换机管理网络和数据流量分离。每一台交换机都具有一个单独的带外以太网端口,该端口仅用于管理服务器与交换机的通信。例如镜像下载,SSH接入,借助网络自动化技术进行配置,通过 SNMP进行监控这类的交换机管理任务,以及其他解决方案全都是通过这种独立的带外管理网络来进行。此以太网管理端口并不会连接至转发芯片,也不需要利用转发芯片驱动程序来配置交换机。
这是我所遇到过的最普遍的一种运营人员用来管理交换机的方法 (交换机包括路由器或网桥,为了明确起见,这里加以区分) 。数据流量 (即存在于网络上的业务流量) 不会使用这张管理网络。
与管理网络的缺省路由不同,数据流量要求的是另一条缺省路由。一台交换机具有两条不同的缺省路由只能是借助VRF虚拟路由转发实现。
网络虚拟化模型
服务抽象:二层或者三层
传统上网络被划分为七层,但是从网络虚拟化的角度看,仅与二层和三层相关。在三层和三层之上,网络功能与其说是网络虑拟化不如说是一种服务虚拟化。
二层虚拟网络
作为一种二层服务抽象,二层虚拟网络不会对负责数据包路由的网络层做任何假设。二层虚拟网络仅假设包转发会使用二层 (或 MAC) 转发表,并且地址在整个二层网络是唯一的。但一个虚拟二层网络并不需要让IP地址像 MAC 地址一样在整个二层虚拟网络是唯一的。虚拟网络起源于 VLAN (virtual local area network,虚拟局城网),VLAN 提供了一种二层服务抽象。
在传统的桥接网络(包括VLAN)中,STP在整个桥接网络范围内构建单一的生成树用于转发所有包,包括单播包及多目的地址包(未知单播包,多播包以及广播包)。因此单播帧和多目的地址帧使用同样的转发路径。引入 VLAN 之后,通常都会为每个 VLAN 单独创建一个生成树。
三层虚拟网络
作为三层服务的抽象,虚拟三层网络会提供唯一的三层地址。正如在物理网络中一样,虚拟三层网络通常是 IP 网络 (但并非总是如此)。每一个虚拟三层网络会获取一份路由表的副本,并且此副本仅归此虚拟三层网络所有。每一个虚拟网络的路由表的生成方法类似物理网络:要么是预先配置好,要么根据某种协议或网络协议栈动态生成。如果路由表是按照路由协议生成,那么每个虚拟三层网络要么有各自单独的路由协议的实例,要么单个路由协议实例可以区分不同虚拟三层网络的地址这两种模型都很流行且通用。
最常用的虚拟三层网络技术是 VPN。各种 VPN 技术都依赖于支持虚拟三层网络所必需的一种基础抽象,被称为 VRF (Virtual Routing and Forwarding,虚拟路由和转发)。**VRF的主要任务就是为每一个虚拟三层网络提供单独的路由表。**通常由在路由查找表中添加 VRFID 字段来实现。在 VRF的最简单的实现里,VRFID 是来自数据包的接收接口。数据包本身并不提供任何可用于生成 VRFID 的信息。但是,VPN会在数据包中携带 VPN ID。
VPN 后来也发展到可以支持虚拟二层网络。因此,支持虚拟三层网络的 VPN 通常称为 L3VPN,以区别于 L2VPN。
内嵌虚拟网络与 Overlay 虚拟网络
虚拟网络还有另一类重要的分类标准,即虚拟网络是作为内嵌网络实现还是作为Overlay 网络实现。在内嵌模型中,源端和目的端的每一跳都会感知到数据包所属的虚拟网络的存在,并使用这类信息在转发表中做查询。在 Overlay 网络模型中,只有网络的边缘部分会关注虚拟网络,网络的内部并不知道虚拟网络的存在。VLAN和VRF是内嵌模型的例子,然而 MPLS,VXLAN以及其他基于IP的 VPN都是Overlay 网络的例子。
内嵌模型的主要优点是透明以及没有数据包头的开销。但是这种模型需要路径上的每个节点都能感知到虚拟网络的存在,这会使得内嵌模型不易于扩展且低效。内嵌模型之所以低效,是因为在核心网络中,每一台交换机或路由器都必须跟踪每一个虚拟网络以便正确的转发数据包。这种做法非常低效,因为任何对虚拟网络的改动都会影响网络中
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









