







本章的目的是帮助网络工程师确定网络的理想 OSPF 配置。本章将回答以下问题
- 应何时在数据中使用OSPF ?
- 配置 OSPF 的关键设计原则是什么?
- OSPFv2 和 OSPFv3 之间有什么区别,应如何使用?
- 如何在路由协议栈中配置 OSPF ?
- 如何在服务器上配置 OSPF,例如为容器提供路由环境?
- 如何使用 OSPF 来协助升级路由器软件?
OSPF是最流行的IGP
- 目前针对IPv4协议使用的是OSPF Version 2(RFC2328);针对IPv6协议使用OSPF Version 3(RFC2740)。
- 运行OSPF路由器之间交互的是LS(Link State,链路状态)信息,而不是直接交互路由。LS信息是OSPF能够正常进行拓扑及路由计算的关键信息。
- OSPF路由器将网络中的LS信息收集起来,存储在LSDB中。路由器都清楚区域内的网络拓扑结构,这有助于路由器计算无环路径。
- 每台OSPF路由器都采用SPF算法计算达到目的地的最短路径。路由器依据这些路径形成路由加载到路由表中。
- OSPF支持VLSM(Variable Length Subnet Mask,可变长子网掩码),支持手工路由汇总。
- 多区域的设计使得OSPF能够支持更大规模的网络。
需要解决的问题
图13-1展示了用于示例的两种基本Clos网络架构。
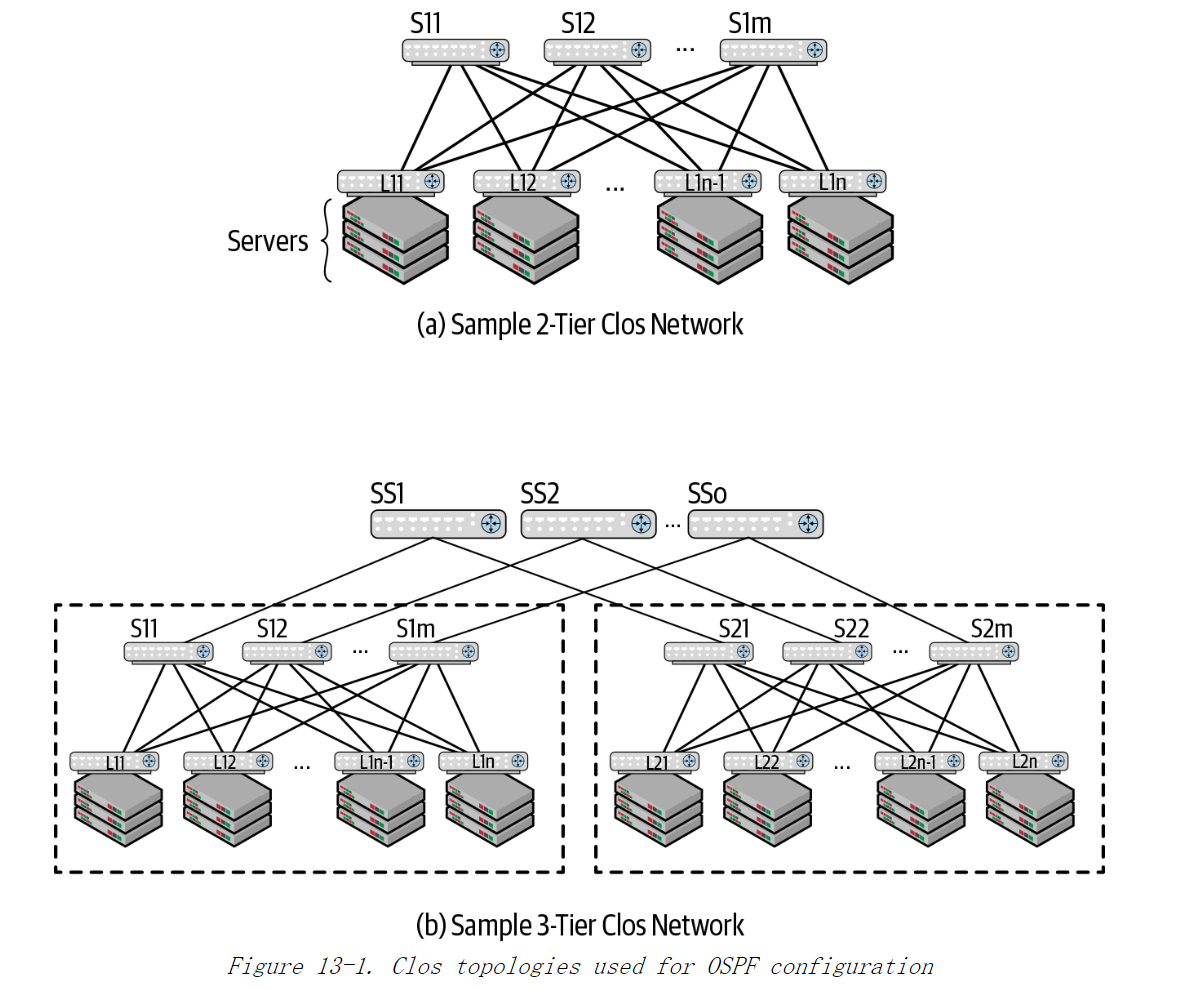
如第5章所述,在使用链路状态路由协议时,一个路由域中的每台路由器都知道该域中所有其他路由器的本地链路状态信息,并使用这些链接状态信息来计算自己到目的地址的路由。因为路由器可以准确地知道其本地链路的状态,所以使用这种方式来计算转发路径,可以在链路或节点出现故障时使网络迅速收敛到稳定状态。
确定链接状态的泛洪域
一台路由器只与其配置的邻居进行通信。例如,在图 13-1(a) 中,L1 仅与 spine 路由器 S1至 Sm 交换信息。为确保网络中的每个路由器都有其他所有路由器的本地信息,路由器必须将从一个邻居接收的信息传播到其所有其他邻居。因此,S1 将从 L1 收到的信息未经修改地传播到从 L2 到 Ln 的所有邻居。将从一个路由器接收到的路由信息未修改地转发到其他邻居的过程在 OSPF 中被称为泛洪。
在大型网络中,如果在节点上保存网络中每个路由器的链接状态,则会占用节点的大量内存。为了解决该问题,所有的链路状态协议都会将路由域划分为较小的段或组,以此限制链路状态信息在路由域中的传播。这种较小的分段在 OSPF 中成为“区域”,泛洪的范围被限制于一个区域中。每个路由器接口都属于一个区域,可以将不同的路由器接口分配给不同的区域。
OSPF 支持两级的分层结构。该分层结构的顶层称为骨干区域,是主要的区域。任何 OSPF路由域都必须具有一个骨干区域。层次结构中的第二级称为非骨干区域。任何 OSPF 路由域可以有多个非骨干区域,但只能有一个骨干区域。多个非骨干区域通过骨干区域连接在一起。骨干区域无法再进行分区,即骨干区域必须是一个连续的段。换句话说,如果来自一部分骨干区域的流量必须穿越非骨干区域才能到达骨干区域的另一部分,那么 OSPF 将无法工作。
OSPF采用一个 32 位数字来标识区域,该数字可以写作一个由0和1组成的二进制字符串,也可以写作一个像 IPv4 地址那样的点分十进制字符串 (例如 0.0.0.1) 。
骨干区域的标识符是0或0.0.0.0。
注意区分Router ID 和 Area ID
| 属性 | Router ID | Area ID |
|---|---|---|
| 定义 | 路由器的唯一标识符 | OSPF 区域的标识符 |
| 长度 | 32 位数字(点分十进制格式,如 1.1.1.1) | 32 位数字(点分十进制格式,如 0.0.0.0) |
| 作用 | 唯一标识 OSPF 路由器 | 标识 OSPF 区域 |
| 唯一性 | 在 OSPF 域中必须唯一 | 在整个 OSPF 网络中可以重复使用,但每个区域的ID唯一 |
| 使用场景 | 建立邻居关系、生成 LSA、计算 SPF 树等 | 划分网络区域,优化路由计算 |
| 配置方式 | 在 OSPF 路由进程中配置(router-id) | 在 OSPF 网络命令中为每个网络分配(area) |
| 更改的影响 | 需要重启 OSPF 进程 | 不需要重启 OSPF 进程 |
Router-ID(Router Identifier,路由器标识符),用于在一个OSPF域中唯一地标识一台路由器。
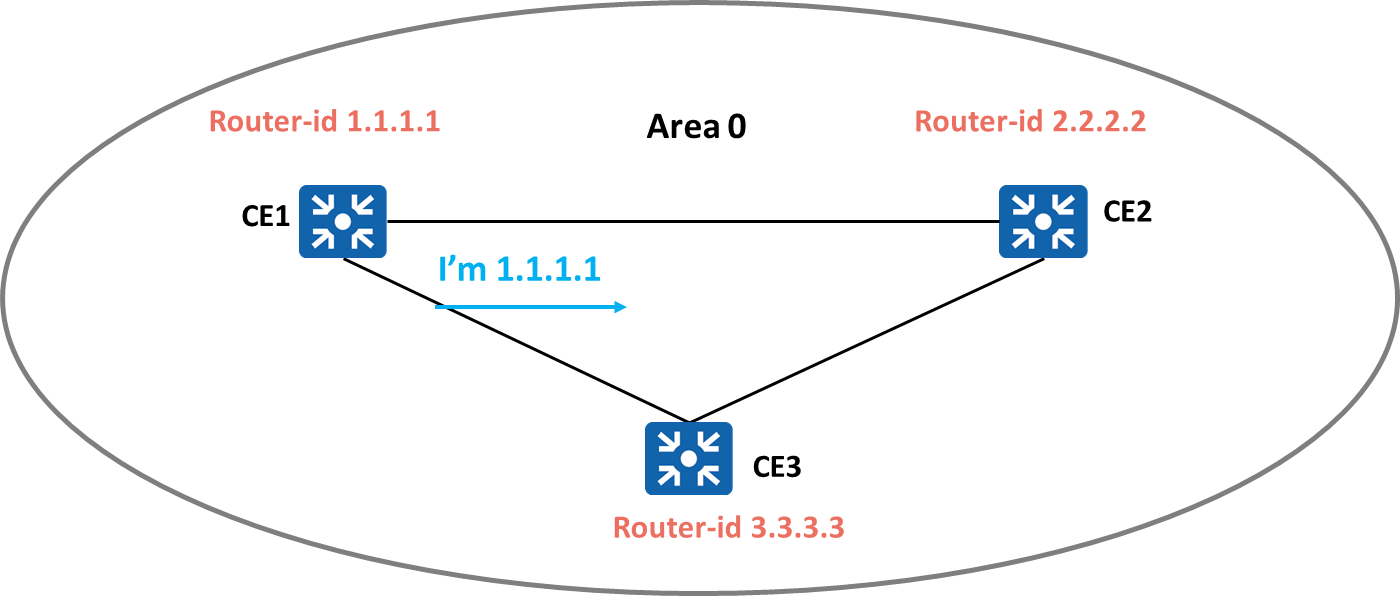
router ospf 1
router-id 1.1.1.1
network 192.168.12.0 0.0.0.255 area 0
network 192.168.13.0 0.0.0.255 area 0
对于我们的示例网络,第一个问题是如何将OSPF区域映射到图 13-1 中所示的拓扑上。这在图 13-1(a) 中很简单,OSPF 只在路由器之间运行,因此图中所有路由器间的链路都在骨干区域中。在图 13-1(b)中,有两个可能的选择:可以将整个网络划分为一个区域,为每个 pod 创建一个单独的区域,并创建一个跨多个 pod 的骨干区域,即在spine路由器和super spine路由器之间创建一个骨干区域。在后一种情况下骨干区域将覆盖 spine 路由器和 super spine 路由器,每个 pod 位于非骨干区域。
OSPF 区域的逻辑划分与物理拓扑的关系:在 OSPF 中,一个路由器可以属于多个区域。例如,一个 Spine 路由器的接口可以连接到属于不同 OSPF 区域的多个 Leaf 路由器,同时该 Spine 路由器自身的另一个接口可以属于骨干区域。因此,Spine 路由器可以位于骨干区域,但它的某些接口连接到的 Pod 是非骨干区域。
Spine 路由器作为区域边界路由器(ABR):Spine 路由器通常充当 OSPF 的区域边界路由器(ABR),这意味着它们连接了一个骨干区域(Spine 和 Super Spine 路由器之间)和一个或多个非骨干区域(每个 Pod 内部的区域)。因此,Spine 路由器的某些接口在骨干区域内,而其他接口连接到不同的非骨干区域。
已编号与无编号 0SPF
最常见的OSPFv2部署模型假设 OSPF链路两端的接口都已编号。链路的每一端都有一个有效的IP地址,更确切地说,链路两端的接口被分配了来自同一子网的IP地址。如果是IPv4,此地址通常来自子网掩码为 /30 或 /31 的子网。因为该子网地址只用于单个链路的两端,所以建议使用 /31 以避免浪费 IPV4 地址。在网络软硬件解耦的初期,当商用交换芯片的路由表较小时,网络运营商会关闭这些只包含接口地址的路由通告。IPv6 引入了链路本地地址 (以 fe80 开头的地址)来专门处理这种情况。
无编号接口可以使路由表变得更小,降低安全攻击的概率,并且在链路或节点上/下线时减少路由表中的变化。除此以外,在不借助编程的情况下实现 IP 地址在接口上的自动分配是非常困难的。综上所述,能够避免使用接口 IP 地址是一件好事。
OSPFv2 从一开始就支持无编号接口。 在 OSPFV2 中,如果接口有一个子网掩码为/32 的地址,则将被视为无编号接口,通常情况下,这是借用的回环接口的地址。要将这个地址通告到邻居节点之外,需要将这个地址添加到回环接口上(或任何其也不下线的接口,如Linux 中的主 VRF 接口)。因此,在 OSPFV2 中使用无编号接口时,我们将回环接口的 IP 地址分配给需要运行 OSPF 的每个链路。这种使用单一地址的方式,与另一端无关,极大地简化了网络自动化。
IPv6支持
如前所述,需要对OSPF进行全面修改才能支持 IPV6,从而产生了一个称为OSPFv3 的新协议。这导致大多数路由协议栈有两种不同的 OSPF 实现: 最初的OSPFv2和新的OSPFv3。即使这样,也很少有协议栈同时支持 OSPF的IPV4和IPv6 实现。Cisco NX-OS 和Juniper 对此的支持已经有一段时间,Arista 在 4.17.0F版本中增加了对此的支持。FRR 支持 OSPFv3,但不支持多个地址族。开源路由套件 BIRD不但在 OSPFv3 中支持多个地址族,甚至用单个代码库同时支持了 OSPFV2和 v3。
本章使用了 FRR 作为基本路由套件来演示OSPF的配置,我们使用 FRR 的多协议模式来显示对 IPv6的支持。
VRF支持
OSPFv2和v3 都支持 VRF,每个 VRF运行一个单独的路由协议实例。在FRR中,只有OSPFv2从7.0版本开始支持VRF。在OSPF 中使用VRF的情况并不常见当在EVPN中用于构建 Underlay 网络时,Underlay 网络运行在默认 VRF 中。
在服务器上运行 OSPF 的要求
在服务器上使用 OSPF 会遇到以下问题:
当服务器添加了另一层层次结构时,应该如何划分区域?
在图 13-1(a)所示的三层 Clos 拓扑中,运行 OSPF的服务器被分配到非骨干区域。在三层 Clos 拓扑中,服务器被分配到非骨干区域,而从 leaf到 super spine 的所有路由器都被分配到骨干区域。使用 FRR,还可以在 pod 中的 spine 路由器上运行两个单独的OSPF实例。
- 一个实例 (在FRR 中为单独的OSPF进程)用于连接服务器,leaf和 spine。
- 一个实例用于连接 spine 和 super spine。
我们可以将从一个 OSPF 实例学到的路由重分发到另一个 OSPF 实例中。
如何确保服务器免受过多链接状态协议消息的影响?
为了将区域内每个路由器的本地状态信息变化更新到网络中,链路状态协议会发送大量消息。由于服务器只有一条通往外部网络的路径,因此并不需要知道所有这些路由更新。在 OSPF 中,可以将一个非骨干区域定义为完全末节区域以避免该区域中的路由器收到网络中其余部分的更新消息。通过将服务器放置在这样的区域中,可以防止它们受到网络其他部分波动的影响。这也可以防止服务器的路由表过大,并减少运行 OSPF 协议的开销。
OSPF路由类型
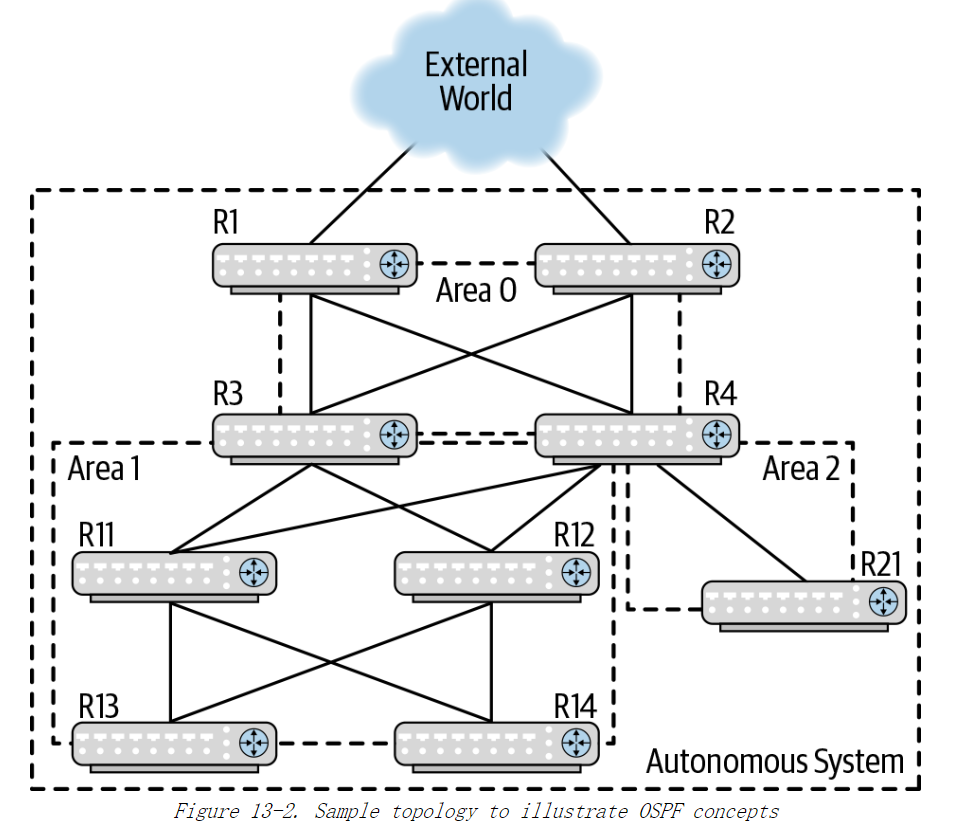
在路由网络中,AS (Autonomous System,自治系统)代表一组自主管理的网络。 例如单个组织的企业网络被视为一个 AS。在图 13-2 中,外侧线框内整个网络是一个 AS。
如前所述,在 OSPF中,路由器的不同网络接口可以属于不同的区域。图 13-2 中的 AS 的骨干区域由路由器 R1到 R4 之间的接口组成,如顶部方框所示。区域 1由R11 到 R14 四个路由器以及它们与 R3 和 R4 的连接组成。区域 2 由单个路由器 R21及其与 R4 的连接组成。
R1 和 R2 连接到外部网络。图中将外部网络简化为了一个云的图形,而忽略了其内部的结构。但实际上,R1 可能比 R2 更接近外部网络中的某些目的地,类似地,R2也可能比 R1 更接近另外一些外部目的地。因此,R3 (和 R4) 最好能将目的地接近R1的流量发向 R1,并且将目的地接近 R2的流量发向 R2。
在这样的网络中,R1和R2 通常运行多种路由协议。R1和R2除了采用OSPF与AS内部的路由器 R3 和R4 进行通信,通常还会使用 BGP 与 AS 外部的路由器进行通信。通过同时运行这两种协议,R1和R2 可以将内部网络与外部网络无缝地结合在一起。他们使用 BGP 来了解外部网络中的目的地,并在自己的 AS 中发布到这些外部目的地的路由通告。同时,他们还使用 OSPF 来了解 AS 内部的目的地,并将外部目的地通告给内部网络。
在小型网络中,可以对 R1和 R2 进行静态配置,使用一个默认路由来指向外部网络中的下一跳路由器,同时可以在外部路由器上通过静态配置单个子网 (或很少的几个子网) 的路由来覆盖整个内部网络。在这种情况下,路由器仍需要使用 OSPF 通告静态配置的默认路由。因此,路由协议需要具有通告通过OSPF以外的其他方式(例如静态配置或通过 BGP) 得到的路由的能力。
将在一种协议中学习到的路由通过另一种协议通告出去,这称为路由重分发,也可以对静态配置的路由进行重分发。在 OSPF 中,被重分发的路由称为外部路由,因为它们是在 OSPF 之外得到的。与之相反,在 AS 区域的路由器之间获得的路由称为内部路由,因为它们是通过 OSPF 得到的。在 OSPF中,R1和R2 被称为 ASBR(Autonomous System Border Routers,自治系统边界路由器) ,因为它们是该AS与外部世界之间的边界。OSPF 将这一概念进行了泛化,任何通告外部路由的路由器都被称为 ASBR。因此,如果 R13 重分发一个静态路由或直连路由,即使 R13 在AS内部,它也是一个 ASBR。
RI和 R2 通过 OSPF 学习到的路由将被通告给外部世界,这样外部世界就可以知道如何与该网络进行通信。这些向外部发送的路由通告通常会隐藏内部网络的详细信息,仅通告汇总后的路由。例如,如果内部网络采用/24 子网,并在内部将其划分为区域1和2的两个/25 子网,则R1和R2 将仅通告/24 子网,而不会通告两个/25 子网。
R3和R4在多个区域中都有链路,它们同时连接到骨干区域(通过到R1和R2的链路)和非骨干区域 1(通过到R11 和R12的链路)。 此外,R4 还连接到非骨干区域2(通过到 R21的链接)。在OSPF 中,R3和R4 被称为 ABR(Area Border Router,区域边界路由器)。区域 1 中的路由器通过该区域中的常规 OSPF 泛洪来学习彼此的路由,它们还通过 R3 和 R4 学习到了 R21 的路由,可能还有外部路由。在区域内学习得到的路由称为区域内路由,而从 ABR 学到的路由称为区域间路由。通过 ABR 学到的外部路由仍然是外部路由。在计算路径时,OSPF的算法会首先选择区域间路由其次是区域内路由,最后才是外部路由。在 Clos 网络中,区域间路由和区域内路由的优先级无关紧要,因为两个区域并没有直接连接。 例如,在图 13-2 中,区域之间的流量必须经过 R3 和 R4。
OSPF路由器根据其位置或功能不同,有这样几种类型:
- 区域内路由器(Internal Router)
- 区域边界路由器ABR(Area Border Router)
- 骨干路由器(Backbone Router)
- 自治系统边界路由器ASBR(AS Boundary Router)
混乱的末节区域
对于 OSPF路由器来说,区域间路由和外部路由是一些需要存储和处理的附加信息。在较早的时期,由于路由器的内存较小或 CPU 功耗较低,很多路由器不能处理大量信息。甚至在现在,这些低功耗路由器也被用于分支机构之类的地方,除了通往外部的缺省路径之外,它们不需要处理其他任何有关外部世界的信息。这样的路由器只需要一条简单的通往分支机构外部的默认路由即可。服务器和分支路由器都只需要一条通往其他地方的默认路由,从这种意义上说,可以认为服务器等同于低功率路由器或分支路由器。
OSPF 定义了多种类型的非骨干区域来解决这些问题。如果一个区域的 ABR只通告一条到达该区域外的默认路由,则该区域称为完全末节区域 (totally stubbyarea) 。为了简化计算,该默认路由被作为区域间路由进行通告。OSPF 的规则禁完全末节区域通告任何外部路由,换句话说,你不能在完全末节区域中的路由器上使用 redistribute 命令进行路由重分发
在很多情况下,这种处理方式的作用有限并且存在问题,因此思科推出了一种称为NSSA (not-so-stubby area,次末节区域)的新型未节区域。由于OSPFV2的LSA结构不够灵活,使得原本应该很简单的操作在 ABR 上变得异常复杂。在一个末节区域中,ASBR 使用7类LSA 来通告外部路由。该区域中的 ABR将7类LSA 转换为易于理解的 5类 LSA,以供其他人使用。
对那些在服务器上运行 OSPF 的网络运营商而言,所有这些工作的结果是将服务器置于一个完全末节区域中,并且不使用路由重分发。另一种可选的方式是将区域配置为 NSSA,但是这种方式为故障定位引入了不必要的麻烦。
OSPF计时器
与其他的协议类似,OSPF 中也有一些计时器,这些计时器会影响 OSPF 中路由信息的收敛等一些功能。设计良好的路由协议栈会为给定的环境提供合理的默认值,因此通常不必担心如何配置这些计时器。例如FRR 就为各种部署环境设置了默认值数据中心是这些部署环境其中之一。虽然提供了缺省值,但了解 OSPF 中使用的各种计时器以及如何确定这些计数器的值还是很有用的。
Hello Interval
这是 OSPF keepalive 计时器,它确定 OSPF 多久向其邻居发送一次 Hello数据包以表明它还活着。Hello Interval 通常设置为 10 秒。如果发生了线缆故障,例如线缆只能进行单向通信,OSPF 可以通过该计数器判断和对端的连接中断,以使网络绕过这条故障线缆进行路由。使用此计时器的另一个原因是需要确保 OSPF进程本身没有挂死。
将此计时器设置过小会导致 OSPF 进程需要以较快的速度处理其所有对等节点发送的保活数据包,这会增加 CPU 的负荷。缺省情况下,管理员会使用 **BFD(Bidirectional Fault Detetion,双向故障检测)**来发现有故障的线缆,因此使用Hello 计时器的唯一作用是用来发现有问题的 OSPF 进程。如果使用的是一个设计良好的路由栈,则最好采用默认值。
Dead Interval
这是在宣布对端失效之前要等待的时间。该值通常设置为 Hello Interval的四倍。换句话说,必须在丢失对端节点的四个连续的 Hello 数据包后才能认为对端已经失效。此计时器确保只在四个连续的 hello interval 时间窗口之后,才将对端节点声明为已失效。如果只是由于线路丢包或进程忙于 SPF 计算之类的操作而丢失了一两个 hello 数据包,则对端不会认为路由器已失效。Dead Interval的默认值为 40 秒,与“ Hello Interval”一样,这个默认值很合适。如果更改了“Hello Interval”,那么也要更改此计时器,以和“Hello Interval”匹配。
Retransmit Interval
在发送包含链路状态信息的数据包后,如果在指定时间内没有收到对方的确认消息,就会重新发送该数据包,“Retransmit Interval”就是重发数据包前的等待时间。此类数据包的例子有 LSA 数据包,链接状态请求 (LSR)数据包和数据库描述(DBD)数据包。该计时器的默认值为五秒钟,最好也保持其默认值。但如果对端是一个低功耗路由器,需要更长的时间来处理和确认链接状态数据包,则需要增大该计时器的值。
Transmit Delay
每个 OSPF LSA 数据包中都包含该数据包的生存时间。LSA 有一个最大生存时间,如果一个 LSA 的生存时间超过该最大值,则将会删除该 LSA 并重新计算路径。为了保证 LSA 生存时间的准确性,每个 OSPF 路由器都会将 LSA 的生存时间增加一个指定的值,以代表该路由器对 LSA 进行处理和传播导致的延迟,该值就是“Transmit Delay”。 默认情况下设置为一秒钟,我建议将该值保留为默认值。
SPF Computation Timers
在获知网络状态发送变化之后,OSPF 使用一组计时器来确定开始重新计算路径的最佳时机。路径重计算可能需要很大的计算量,这在大型网络中尤其突出。
此外,在设计 OSPF 之初,当时路由器的 CPU 与现代 CPU 相比还比较弱,因此OSPF 的实施者希望能够对路径计算进行优化。该优化需要在等待时间上取得平衡,既要避免在网络变化(例如路由器启动或关闭) 后的等待时间过长,也要避免由于等待时间不足导致没有获得重计算所需的所有信息。传统的路由栈实现通常在接收到第一次更新消息后等待 200 毫秒 (称为 SPF 延迟计时器),然后再开始计算路径。如果持续接收到更新消息,则之后的重新计算将延迟10秒(称为最大 SPF 保持计时器,max SPF hold timer)进行,并以1秒(称为保持计时器hold timer)的增量递增。
现在有一种称为增量 SPF 的新算法,该算法只会对受到影响的路径重新进行计算,而不会重新计算整个网络。在 FRR 中,SPF 延迟计时器的默认值设置为 0最大 SPF 保持计时器的默认值设置为 5秒,保持计时器的默认值设置为 50 毫秒由于拥有更快的CPU,并且使用了增量 SPF算法,减少这些计时器的值是可以的。但是除非有充足的理由,否则建议不要修改这些缺省值。
对等连接的路由器必须具有相同的 Hello Interval 计时器和 Dead Interval 计时器。否则 OSPF 将会拒绝在这些邻居之间建立的对等关系。
表 13-1 OSPF 邻居状态及其含义
| State | 含义 |
|---|---|
| One-way | 节点在一个接口上发出了一条 Hello 消息 |
| Two-way | 节点在一个接口上发出并收到了一条 Hello 消息 |
| ExStart | 节点正在和其对端协商如何交换链路状态数据库 |
| Exchange | 两端的节点正在相互同步对方的链路状态数据库 |
| Full | 两端的节点已经完成了和对方的链路状态数据库同步 |
表 13-1 简要说明了当在接口上建立OSPF路由会话时的 OSPF状态,这里我们假设采用的是点对点接口。
此处列出的状态有助于定位 OSPF对等会话失败的问题
OSPF 配置解析
本节将介绍下面的 OSPF 命令
ospf router-id <router-id>:
- 这个命令用于指定OSPFv2的路由器ID。
<router-id>是一个32位的标识符,通常用点分十进制格式表示,如1.1.1.1。路由器ID是OSPF操作中唯一标识每个路由器的关键元素。
ospf6 router-id <router-id>:
- 这个命令用于指定OSPFv3(用于IPv6)的路由器ID。与OSPFv2相似,
<router-id>是一个32位的标识符,用于唯一标识每个路由器。
ip ospf area <area>:
- 这个命令用于将一个接口分配到指定的OSPF区域。
<area>是区域ID,可以是一个整数或点分十进制格式。
interface <ifname> area <area>:
- 在特定接口上启用OSPF,并将其分配到指定的区域。
<ifname>是接口名称,<area>是区域ID。
ip ospf network point-to-point:
- 这个命令用于将接口配置为点对点网络类型。在点对点网络中,只有两个路由器直接相连,不需要DR/BDR选举。
ipv6 ospf6 network point-to-point:
- 这个命令用于将OSPFv3接口配置为点对点网络类型,适用于IPv6。
area <area> stub no-summary:
- 配置一个区域为完全Stub区域(Totally Stubby Area)。
<area>是区域ID。此配置使得该区域不接收外部LSA(类型5)和其他区域的总结LSA(类型3),只接收默认路由。
area <area> range <prefix>:
- 配置区域间的地址汇总。
<area>是区域ID,<prefix>是要汇总的地址前缀。这减少了LSDB中LSA的数量,提高了网络的可扩展性和稳定性。
max-metric:
- 配置路由器宣布一个极高的OSPF度量值,以避免它成为转发路径的一部分。通常在计划维护或关闭路由器时使用。
stub-router:
- 配置路由器为Stub路由器,临时宣告自己为不可达。通常在路由器启动或计划关闭时使用,以防止数据流经这个路由器。
passive-interface:
- 配置一个接口为被动接口,在这个接口上不发送OSPF Hello报文,从而不建立邻居关系,但仍然会将这个接口的网络公告到OSPF中。
ipv6 ospf6 passive-interface:
- 配置OSPFv3接口为被动接口。在这个接口上不发送OSPF Hello报文,适用于IPv6。
network <prefix> area <area>:
- 定义一个网络并将其分配到指定的OSPF区域。
<prefix>是网络前缀,<area>是区域ID。
redistribute connected:
- 将直接连接的路由(直连路由)重新分发到OSPF中,使得这些路由能够在OSPF路由域中传播。
二层 Clos 拓扑中的 Leaf-Spine 配置:IPv4
OSPF 已编号配置的两种方法。已编号模式是最常见的配置方式,但这种模式显然不利于网络自动化。我们将逐渐向无编号模式发展,使用Ansible 脚本实现自动化配置。
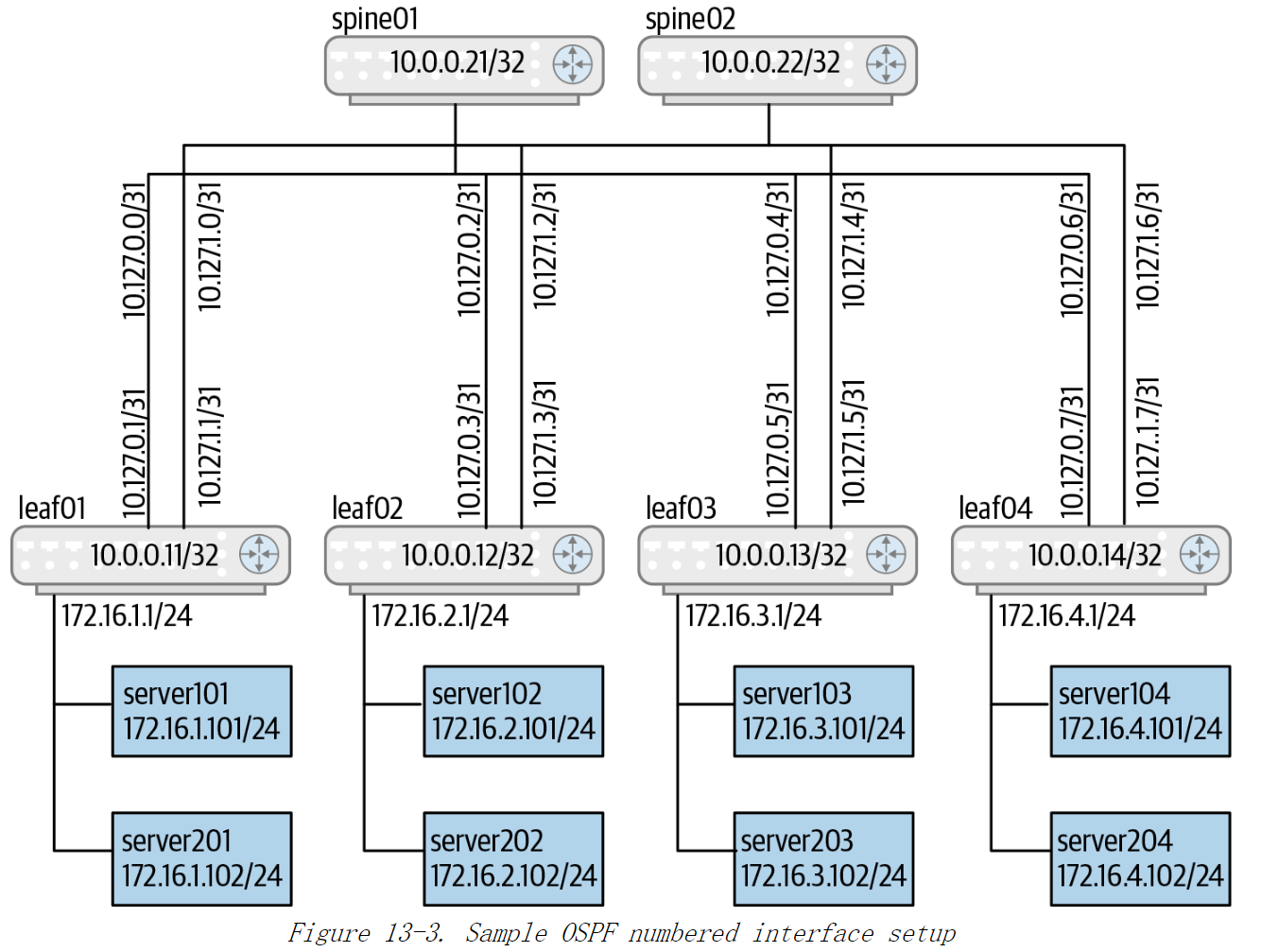
我们将图13-3 中的网络架构用于本节中的示例。为了简单起见,我们将关注点集中到leaf01和spine01。图中每个路由器内部的IP地址是其回环IP地址。服务器通过桥接网络连接到与其关联的 leaf 路由器。在图中标出了桥接网络的子网以及子网中每个接口的IP地址。
示例13-1 常见的OSPF配置风格
spine01配置
! Configuration for spine01
!
interface lo
ip address 10.0.0.21/32
!
interface swp1
ip address 10.127.0.0/31
ip ospf bfd # 这将启用和指定OSPF对等节点之间的BFD
!
interface swp2
ip address 10.127.0.2/31
ip ospf bfd
!
interface swp3
ip address 10.127.0.4/31
ip ospf bfd
!
interface swp4
ip address 10.127.0.6/31
ip ospf bfd
!
# 将10.127.0.0/31、10.127.0.2/31、10.127.0.4/31和10.127.0.6/31的网络通告到OSPF的区域0。
router ospf
ospf router-id 10.0.0.21
network 10.127.0.0/31 area 0
network 10.127.0.2/31 area 0
network 10.127.0.4/31 area 0
network 10.127.0.6/31 area 0
redistribute connected
leaf01配置
! Configuration for leaf01
!
interface lo
ip address 10.0.0.11/32
!
interface swp1
ip address 10.127.0.1/31
ip ospf bfd
!
interface swp2
ip address 10.127.1.1/31
ip ospf bfd
!
! This next statement is for the servers subnet
!
interface vlan10
ip address 172.16.0.1/24
!
router ospf
ospf router-id 10.0.0.11
network 10.127.0.1/31 area 0
network 10.127.1.1/31 area 0
redistribute connected
此配置存在以下问题:
- 难以实现自动化配置,原因是每个节点的配置都各不相同,spine01 的配置与其他 spine 不同,leaf01 的配置与其他 leaf 也不同,依此类推。
- 这种配置很容易出错,因为我们在接口配置和 network 语句中重复使用相同的IP 地址。
- 难以通过目测等简单的方法发现配置中的错误,因为错误可能来自配置中不同行之间的交互,因此需要验证多条信息才能发现错误。
- OSPF 需要花费更多时间来交换路由信息,原因是在配置中没有声明这些链路是点对点链路。在缺省情况下,OSPF 假定路由器之间的链路是桥接链路,在链路上有两个以上的路由器。这将导致 OSPF 进行“指定路由器选举”,但在这种情况下,指定路由器选举其实是不必要的,增加了路由器交换信息的时长。
- 在配置中,重新发布直连路由信息只是复制所有接口的 IP 地址信息而已,因为我们已经通过 network 语句交换了这些信息。如果有很多需要路由的 VLAN,则使用直连路由重分发是避免在配置中写入很多行的一个简便方法。但是,这种节省是以复制某些路由信息,在路径计算步骤中增加一些时间(即使很小) 为代价的。
示例13-2 一种更清晰的已编号 OSPF 配置
spine01配置
! Configuration for spine01
!
interface lo
ip address 10.0.0.21/32
ip ospf area 0
!
interface swp1
ip address 10.127.0.0/31
ip ospf network point-to-point
ip ospf area 0
ip ospf bfd
!
interface swp2
ip address 10.127.0.2/31
ip ospf network point-to-point
ip ospf area 0
ip ospf bfd
!
interface swp3
ip address 10.127.0.4/31
ip ospf network point-to-point
ip ospf area 0
ip ospf bfd
!
interface swp4
ip address 10.127.0.6/31
ip ospf network point-to-point
ip ospf area 0
ip ospf bfd
!
router ospf
ospf router-id 10.0.0.21
passive-interface lo
leaf01配置
! Configuration for leaf01
!
interface lo
ip address 10.0.0.11/32
ip ospf area 0
!
interface swp1
ip address 10.127.0.1/31
ip ospf network point-to-point
ip ospf area 0
ip ospf bfd
!
interface swp2
ip address 10.127.1.1/31
ip ospf network point-to-point
ip ospf area 0
ip ospf bfd
!
! This next statement is for the servers subnet
!
interface vlan10
ip address 172.16.0.1/24
ip ospf area 0
!
router ospf
ospf router-id 10.0.0.11
passive-interface default
no passive-interface swp1
no passive-interface swp2
- 有在 network 语句中重复使用接口的地址信息。
- 声明接口对于 OSPF来说是点对点的,从而避免了不必要的指定路由器选举加快了收敛速度。
- 通过删除 redistribute 语句避免了重复信息的分发,同时也去掉了外部路由。由于 OSPF 在其路径计算逻辑中需要处理外部路由,因此这种做法进一步减少了收敛时间。
- 由于仍然需要在配置中指定接口地址信息,因此我们将需要路由的 VLAN接口添加到OSPF中。示例中的 passive-interface 语用于表明一个接口是被动接口,即该接口只是连接在 OSPF 上,但并不和其他节点形成对等关系并参与路由信息交换。上面的示例中使用了两种不同的方式来指明被动接口,以减少配置文件的大小。如果有许多需要路由的 VLAN 接口 (即有许多被动接口) ,则可以使用示例中 leaf01 的声明方式,以使得配置文件更小。对于 spine 节点来说,只有回环接口是被动接口,因此可以采用示例中 spine01 的申明方式,以得到较小的配置。如果你偏好于其中一种方式,在这两种情况下都使用该方式来申明被动接口,那也是可以的。
示例13-3 OSPF无编号配置
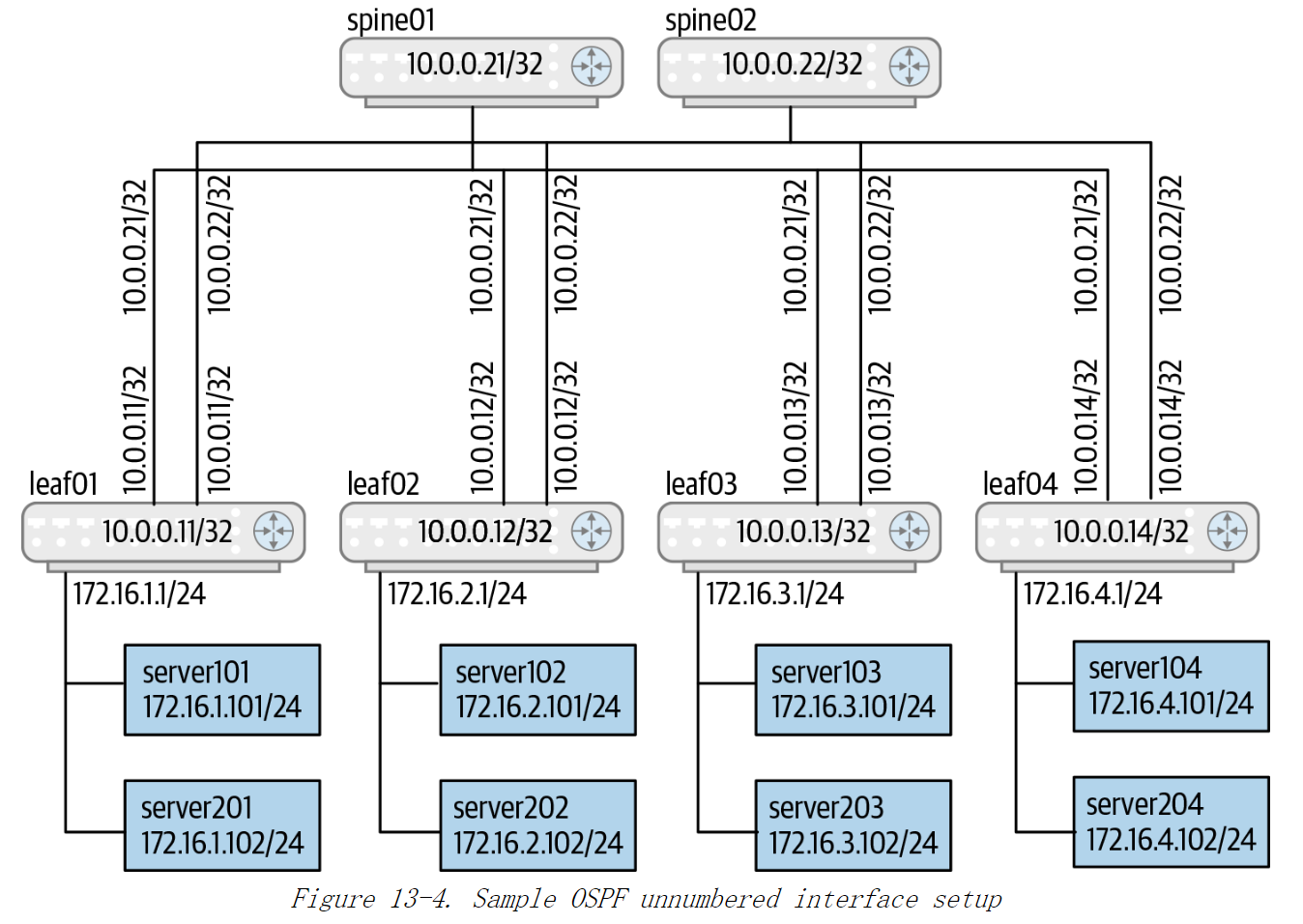
图13-3 OSPF无编号接口设置示例
spine01配置
! Configuration for spine01
!
interface lo
ip address 10.0.0.21/32
ip ospf area 0
!
interface swp1
ip address 10.0.0.21/32
ip ospf network point-to-point
ip ospf area 0
ip ospf bfd
!
interface swp2
ip address 10.0.0.21/32
ip ospf network point-to-point
ip ospf area 0
ip ospf bfd
!
interface swp3
ip address 10.0.0.21/32
ip ospf network point-to-point
ip ospf area 0
ip ospf bfd
!
interface swp4
ip address 10.0.0.21/32
ip ospf network point-to-point
ip ospf area 0
ip ospf bfd
!
router ospf
ospf router-id 10.0.0.21
passive-interface lo
leaf01配置
! Configuration for leaf01
!
interface lo
ip address 10.0.0.11/32
ip ospf area 0
!
interface swp1
ip address 10.0.0.11/32
ip ospf network point-to-point
ip ospf area 0
ip ospf bfd
!
interface swp2
ip address 10.0.0.11/32
ip ospf network point-to-point
ip ospf area 0
ip ospf bfd
!
! This next statement is for the servers subnet
!
interface vlan10
ip address 172.16.0.1/24
ip ospf area 0
!
router ospf
ospf router-id 10.0.0.11
passive-interface default
no passive-interface swp1
no passive-interface swp2
**所有路由器间链路只使用了一个地址,并且该地址与回环地址相同。回环地址也被用作路由器 ID。**总而言之,单个地址就可以满足除了服务器所在子网之外的所有其他配置。
如果你的路由器支持接口范围,那么在一个64口的leaf路由器上,可以像下面这样配置:
! Configuration for spine01
interface lo
ip address 10.0.0.11/32
interface swp[1-64]
ip address 10.0.0.11/32
ip ospf network point-to-point
ip ospf area 0
ip ospf bfd
router ospf
ospf router-id 10.0.0.11
passive-interface lo
三层 Clos 拓扑的 OSPF配置
当使用 OSPF 来配置三层 Clos 网络时,有两种可能的情况:一种是在服务器上运行 OSPF,另一种则不在服务器上运行 OSPF。在后一种情况下,每个 pod 是一个单独的非骨干区域,pod 的 spine 交换机与 super spine 交换机之间的链路则组成了骨干区域,即区域 0。可以为每个 pod分配相同的非骨干区域编号,即都设置为区域 1。
配置运行 OSPF的服务器:IPv4
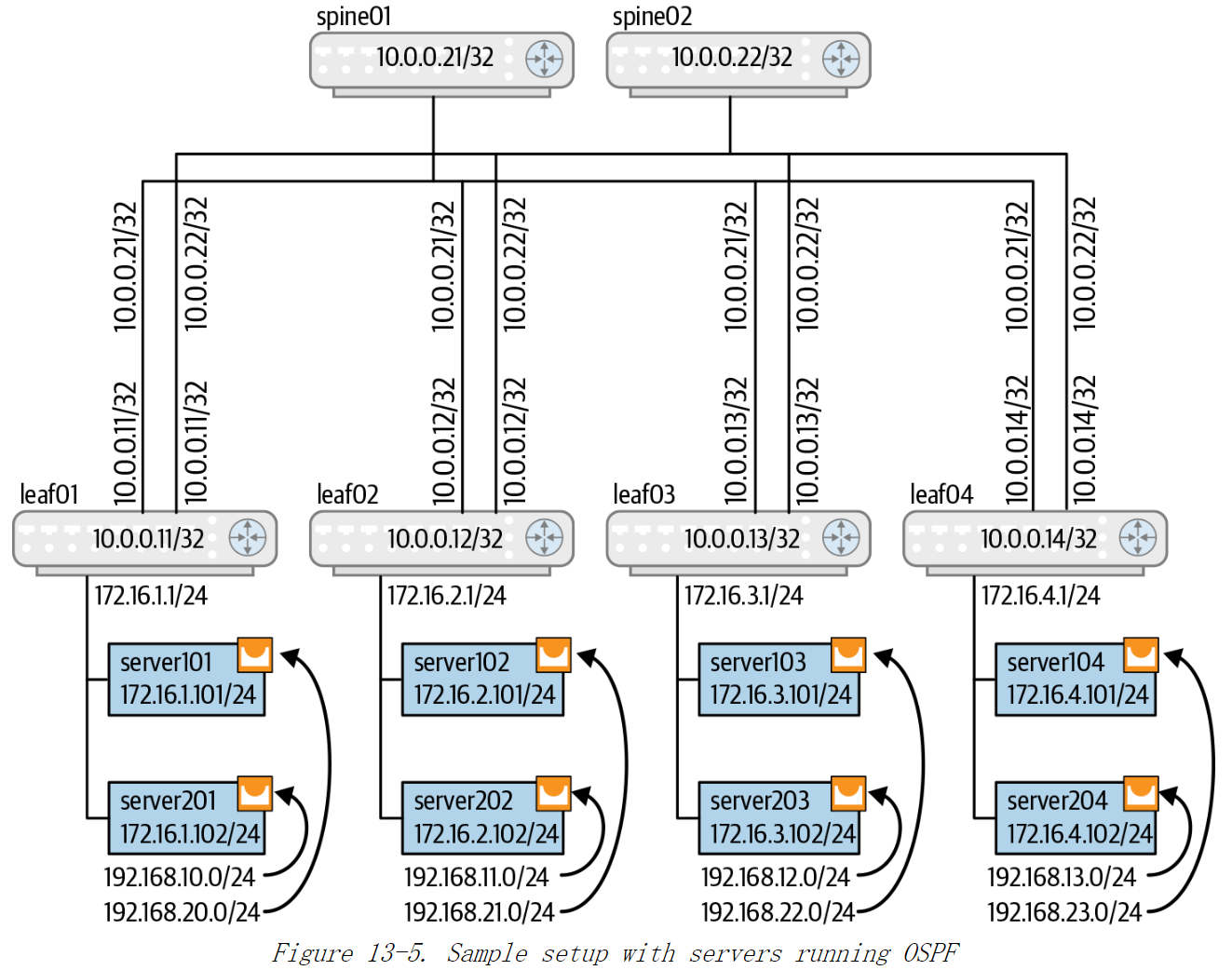
当与容器一起使用时,一些客户在主机上使用 OSPF 来通告容器 IP 地址或容器的桥接IP子网。如我们在前面讨论的那样,在这种情况下,leaf路由器认为服务器属于一个完全末节区域,因此只会向服务器通告一个默认路由。我们看一下如何对路由器 leaf01 以及与其相连的服务器 server101 进行配置。这里假设在配置中使用无编号接口,以减少需要考虑的内容。
第一项任务是连接服务器。这需要将 leaf01 上面向服务器的端口转换为可路由端口。在前面的示例中,这些面向服务器的路由器端口是 VLAN 的一部分,也就是说,它们是桥接端口。如果使用网桥来连接 leaf01 和与服务器,那么网桥上的每个OSPF路由器都会与同一个网桥上的其他路由器建立对等关系。在上图中,leaf01 将分别与 server101和 server201 建立 OSPF 对等关系,server101 和 server201 也会建立OSPF对等关系。 但是在 server101 和server201之间建立的对等关系其实是不必要的,只会增加在服务器上运行 OSPF 的复杂性和开销。
我们来看看每个机架放 40 台服务器的常见部署下,这些开销有多大。在这种部署下leaf01 将会有 40个OSPF 对等节点,即每个服务器就是一个对等节点。这 40 个服务器相互之间也会建立对等关系。因此,每个服务器有 40 个 OSPF 对等节点: 39个服务器和一个leaf01。这总共会产生 1600 个 OSPF 会话,在该区域中增加了大量的会话消息和资源开销。然而这些开销都是没有必需的,因为路由更新只能通过指定路由器 leaf01 进行(需要额外的配置以确保它始终成为指定路由器)。
相反地,如果将面向服务器的交换机端口设置为纯路由端口(在此示例中为leaf01),所有服务器只和它们相连的 leaf 交换机建立对等关系,那么一切将恢复正常。图 13-5 展示了这种设置,图中每个服务器内部有一个IP地址属于 192.168.x.x子网的 docker 网桥,服务器中的容器都连接到该网桥上,服务器自身的网卡则属于172.16.x.x 子网。
根据本章“混乱的末节区域”中的讨论,应该将所有服务器放在一个单独的完全未节区域(非骨于区域)中。假设docker 网桥名为 docker0,则leaf01 和主机server101 的配置参见示例 13-6。
示例 13-6: leaf01和 server101的OSPF 无编号配置
! Configuration for leaf01
!
interface lo
ip address 10.0.0.11/32
ip ospf area 0
!
interface swp1
ip address 10.0.0.11/32
ip ospf network point-to-point
ip ospf area 0
ip ospf bfd
!
interface swp2
ip address 10.0.0.11/32
ip ospf network point-to-point
ip ospf area 0
ip ospf bfd
!
! Now the server connections
!
interface swp3
ip address 10.0.0.11/32
ip ospf network point-to-point
ip ospf area 1
ip ospf bfd
!
interface swp4
ip address 10.0.0.11/32
ip ospf network point-to-point
ip ospf area 1
ip ospf bfd
!
router ospf
ospf router-id 10.0.0.11
passive-interface lo
area 1 stub no-summary
! Configuration for server101
!
interface lo
ip address 172.16.0.101/32
ip ospf area 1
!
interface eth1
ip address 172.16.0.101/32
ip ospf network point-to-point
ip ospf area 1
ip ospf bfd
!
interface docker0
ip ospf area 1
ip ospf bfd
!
router ospf
ospf router-id 172.16.0.101
passive-interface lo
passive-interface docker0
area 1 stub no-summary
和没有在服务器上运行 OSPF 的配置相比,该配置的主要区别是 leaf 路由器上那些面向服务器的端口的设置,现在这些端口上也运行了 OSPF。另一个不同之处是通过命令area 1 stub no-summary将区域1定义为完全末节区域。值得注意的是,需要同时在服务器和leaf路由器上使用该命令来声明完全未节区域。如果没有这样做,OSPF将不会在leaf 和服务器之间建立对等关系。no-summary关键字表示来自其他区域的路由汇总也不需要发送到该区域中,该区域仅提供缺省路由即可,这使它成为一个完全末节区域。因为完全末节区域不能是 ASBR,所以不能在服务器上进行直连路由重分发或者其他重分发操作。
在该配置中还宣告了缺省 docker 网桥 docker 的 IP地址。要使该配置正常工作,需要确保Docker在容器数据包离开服务器时不会对其IP地址进行NAT。
Docker 通过文件
/etc/docker/daemon.json为 docker0 网桥设置IP地址
运行该配置,查看spine01上的路由表
vagrant@spine01:~$ ip ro
10.0.0.11 via 10.0.0.11 dev swp1 proto ospf metric 20 onlink
10.0.0.12 via 10.0.0.12 dev swp2 proto ospf metric 20 onlink
10.0.0.13 via 10.0.0.13 dev swp3 proto ospf metric 20 onlink
10.0.0.14 via 10.0.0.14 dev swp4 proto ospf metric 20 onlink
10.0.0.22 proto ospf metric 20
nexthop via 10.0.0.11 dev swp1 weight 1 onlink
nexthop via 10.0.0.12 dev swp2 weight 1 onlink
nexthop via 10.0.0.14 dev swp4 weight 1 onlink
nexthop via 10.0.0.13 dev swp3 weight 1 onlink
172.16.1.101 via 10.0.0.11 dev swp1 proto ospf metric 20 onlink
172.16.1.102 via 10.0.0.11 dev swp1 proto ospf metric 20 onlink
172.16.2.101 via 10.0.0.12 dev swp2 proto ospf metric 20 onlink
172.16.2.101 via 10.0.0.12 dev swp2 proto ospf metric 20 onlink
172.16.2.102 via 10.0.0.12 dev swp2 proto ospf metric 20 onlink
172.16.3.101 via 10.0.0.13 dev swp2 proto ospf metric 20 onlink
172.16.3.102 via 10.0.0.13 dev swp2 proto ospf metric 20 onlink
172.16.4.101 via 10.0.0.14 dev swp4 proto ospf metric 20 onlink
172.16.4.102 via 10.0.0.14 dev swp4 proto ospf metric 20 onlink
将上面的输出与没有在服务器上运行OSPF的同一命令的输出进行比较:
vagrant@spine01:~$ ip ro
10.0.0.11 via 10.0.0.11 dev swp1 proto ospf metric 20 onlink
10.0.0.12 via 10.0.0.12 dev swp2 proto ospf metric 20 onlink
10.0.0.13 via 10.0.0.13 dev swp3 proto ospf metric 20 onlink
10.0.0.14 via 10.0.0.14 dev swp4 proto ospf metric 20 onlink
10.0.0.22 proto ospf metric 20
nexthop via 10.0.0.11 dev swp1 weight 1 onlink
nexthop via 10.0.0.12 dev swp2 weight 1 onlink
nexthop via 10.0.0.14 dev swp4 weight 1 onlink
nexthop via 10.0.0.13 dev swp3 weight 1 onlink
172.16.1.0/24 via 10.0.0.11 dev swp1 proto ospf metric 20 onlink
172.16.2.0/24 via 10.0.0.12 dev swp2 proto ospf metric 20 onlink
172.16.3.0/24 via 10.0.0.13 dev swp2 proto ospf metric 20 onlink
172.16.4.0/24 via 10.0.0.14 dev swp4 proto ospf metric 20 onlink
在后一个输出中可以看到,spine 路由器中只有汇总的子网路由,而不是到每个服务器的路由。相比在路由器节点中携带每个服务器的IP地址而言,汇总路由的方式显然更容易扩展。
综上所述,你应该怎么做? 当运行一个大型的三层 Clos 网络时,这将是一个问题每个 pod 都应该看到其他 pod 中的所有路由吗? 还是可以使用默认路由来处理? 在这种情况下,我们应该如何进行路由汇总?接下来我们将解决这个问题。
OSPF中的路由汇总
对于服务器来说,leaf路由器是 ABR,因此,leaf路由器可以将针对单个服务器的路由汇总为子网路由,就像在服务器没有运行OSPF时那样。
这是进行路由汇总的命令:
area <area> range <ip-summary-route> advertise
例如可以在 leaf01 下运行下面的命令进行路由汇总:
area 1 range 172.16.1.0/24 advertise
在三层 Clos 拓扑中,唯一可能进行路由汇总的地方是 pod 中的 spine 路由器,因为当服务器未运行 OSPF时,只有这些 spine 路由器才是 ABR。如果可以将 pod的leaf路由器的路由汇总为几个子网路由,则可以使用 area 命令在 spine 路由器上进行汇总。
就像我们在“Clos 网络中的路由汇总”中讨论过的那样,在进行路由汇总时,一个需要考虑的重要因素是在发生故障时的行为。对于运行 OSPF 的服务器来说,只有当主机连接到了两个路由器上,并且主机和其中一个路由器的链路断开时,才会导致 leaf路由器上的路由汇总出现问题。
OSPF 和升级
能够在不影响流经路由器的流量的情况下升级路由器的能力非常有用。要实现这一点,主要方法是先切走路由器中的所有存量流量,然后再对路由器进行升级。
在OSPFv2 中使用的命令是 max-metric。在进行路径计算时,链路状态协议会使用链路的 metric 值来选择开销最小的路径。max-metric 命令会把经过一个路由器的所有链路的 metric 改为可能的最大值,这样网络中的所有其他路由器会在将计算路由路径时将该路由器排除在外。该改动不会影响目前正在传输的流量,但是新的流量不会再经过该路由器。路由器会对自身的链路进行监控,并在流量下降到足够低的值时安全地进行升级。
最佳实践
- 如果支持的话,尽可能使用无编号接口。
- pod 的区域号或服务器的区域号可以重复使用。两个不同的 leaf 路由器可以使用相同的区域号来标识连接到它们的服务器。同样,两个不同的 pod 也可以使用相同的区域号,例如,都使用1作为区域号。这样设置的话,网络中只有两个区域0和区域1。
- 在对已编号接口进行配置时使用
ip ospf area而不是 network 语句,这样可以避免在配置中的多处位置重复拷贝IP 地址。在无编号接口的方式下,则只能使用ip ospf area语句。 - 无论是在服务器还是在路由器上使用无编号接口,一定要为回环接口也分配一个IP 地址,并确保回环接口被声明为 passive 接口,并设置在正确的区域中。
- 使用 BFD 并且保持计时器的缺省值不变,这将使得配置更健壮和更简单
- 始终通过
log-adjacency-changes detail配置命令启用 OSPF 对等连接状态变化的详细日志记录。FRR 默认启用了该功能,因此在本章前面的 FRR 示例配置中没有该命令。 - 避免使用
redistribute connected命令。使用redistribute connected看起来似乎简化了配置,但其实却通告了不必要的重复信息。此外,避免使用外部路由还可以简化路由器上的 OSPF 处理。 - 将 OSPF 配置保持为最小,以确保一个健壮的网络















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









