







参考书籍《Aritificial Intelligence with Python》,本篇文章只是解释代码以及自己学习后对决策树的理解,属于初学者,之后可能会根据自身知识体系的完善程度进行补充。数据以及代码链接,里面会有可视化的程序。
决策树概念
就像数据从根节点开始跑,根据每个节点的条件去到下一个分支,这种方式更具全局观,不同的因素影响力不同且有些因素可能相互行成了更好的判断力。决策树要做的就是找到使模型性能更好的节点,从而自动建树。
决策树的简单应用 – 分类
数据是两个参数和一个标签组成,标签用0和1区别
# 读取
input_file = 'data_decision_trees.txt'
data = np.loadtxt(input_file, delimiter=',')
X, y = data[:, :-1], data[:, -1]
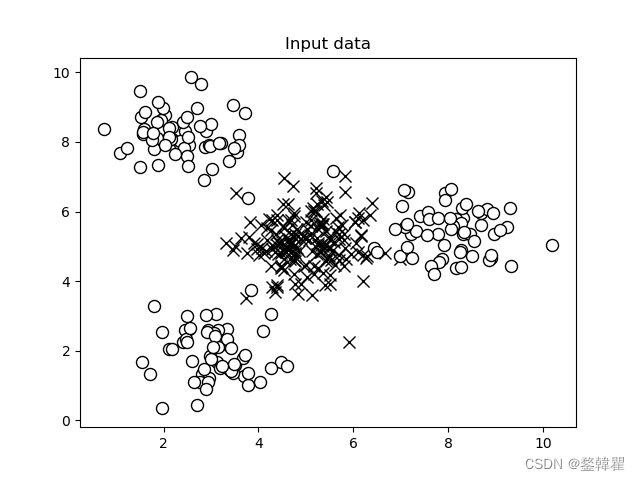
该数据可以先由标签分成两组数据,然后画出该数据的散点分布图
# Visualize input data
plt.figure()
plt.scatter(class_0[:, 0], class_0[:, 1], s=75, facecolors='black',
edgecolors='black', linewidth=1, marker='x')
plt.scatter(class_1[:, 0], class_1[:, 1], s=75, facecolors='white',
edgecolors='black', linewidth=1, marker='o')
plt.title('Input data')
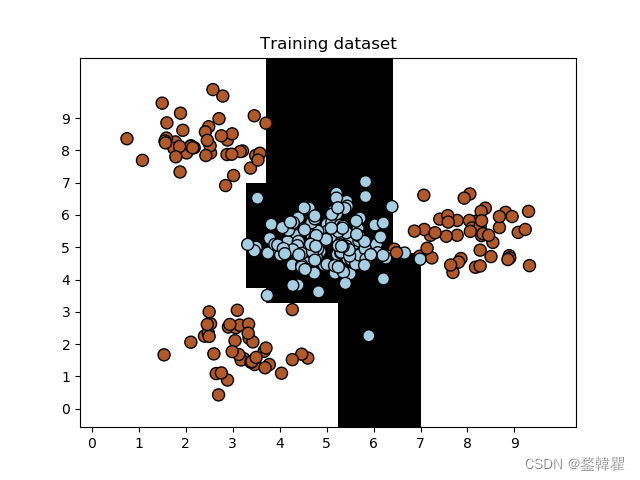
将数据分为训练集和测试集
X_train, X_test, y_train, y_test = model_selection.train_test_split(
X, y, test_size=0.25, random_state=5)
构造分类器
params = {'random_state': 0, 'max_depth': 4}
classifier = DecisionTreeClassifier(**params) # *表示传任意数量的参数 **是字典形式 *是元组形式
classifier.fit(X_train, y_train)
将训练集以及分类函数可视化
visualize_classifier(classifier, X_train, y_train, 'Training dataset')
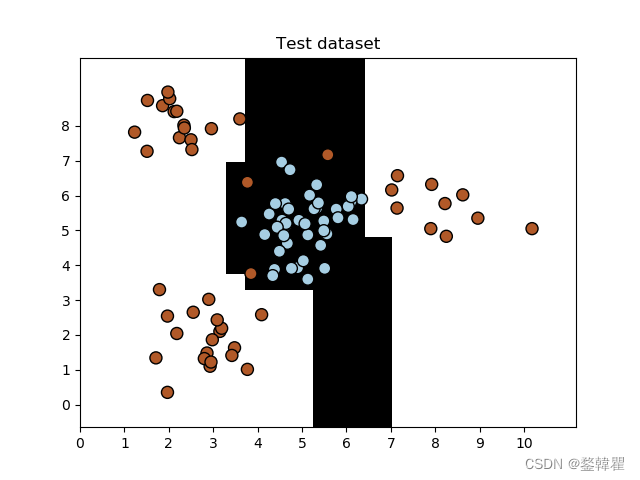
再将测试集数据以及分类器可视化,可以明显看出分类器的效果
visualize_classifier(classifier, X_test, y_test, 'Test dataset')
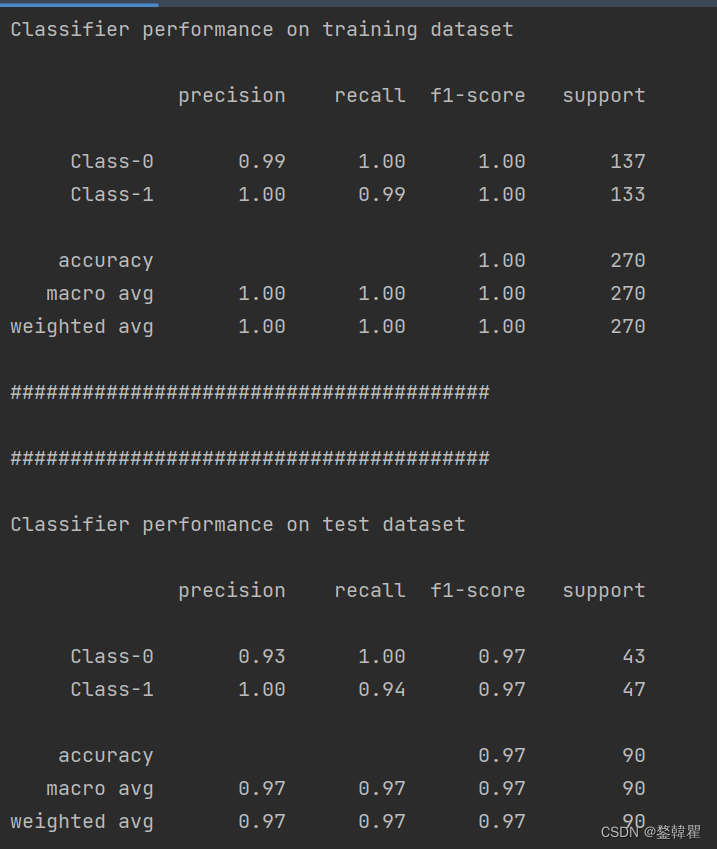
分类器的性能指标
class_names = ['Class-0', 'Class-1']
print("\n" + "#" * 40)
print("\nClassifier performance on training dataset\n")
print(classification_report(y_train, classifier.predict(X_train), target_names=class_names))
print("#" * 40 + "\n")
y_test_pred = classifier.predict(X_test)
print("#" * 40)
print("\nClassifier performance on test dataset\n")
print(classification_report(y_test, y_test_pred, target_names=class_names))
print("#" * 40 + "\n")















 2194
2194











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









