







摘要
由于大规模模型的端到端训练,视觉与语言预训练的成本变得越来越高。本文提出了BLIP-2,一种通用且高效的预训练策略,它从现成的冻结预训练图像编码器和冻结大型语言模型中引导视觉-语言预训练。BLIP-2通过一个轻量级的查询转换器(Querying Transformer)来弥合模态差距,该转换器在两个阶段进行预训练。第一阶段从一个冻结的图像编码器引导视觉-语言表示学习。第二阶段从一个冻结的语言模型引导视觉到语言的生成学习。BLIP-2在各种视觉-语言任务上实现了最先进的性能,尽管其可训练参数数量显著少于现有方法。例如,我们的模型在零样本VQAv2上比Flamingo80B高出8.7%,而可训练参数数量却少了54倍。我们还展示了模型在零样本图像到文本生成方面的新兴能力,能够遵循自然语言指令。
1. 引言
视觉-语言预训练(VLP)研究在过去几年中见证了快速的进展,其中预训练模型的规模越来越大,不断推动各种下游任务的最新技术水平(Radford等,2021;Li等,2021;2022;Wang等,2022a;Alayrac等,2022;Wang等,2022b)。然而,大多数最先进的视觉-语言模型在预训练期间由于使用大规模模型和数据集的端到端训练而产生了高计算成本。视觉-语言研究位于视觉和语言的交叉点,因此自然期望视觉-语言模型能够从视觉和自然语言社区中现成的单模态模型中获益。在本文中,我们提出了一种通用且计算效率高的VLP方法,通过从现成的预训练视觉模型和语言模型中引导。预训练的视觉模型提供了高质量的视觉表示。预训练的语言模型,特别是大型语言模型(LLMs),提供了强大的语言生成和零样本迁移能力。为了减少计算成本并抵消灾难性遗忘的问题,单模态预训练模型在预训练期间保持冻结。
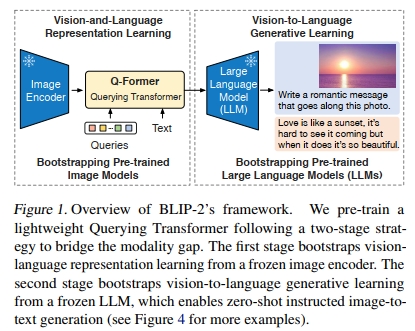
为了利用预训练的单模态模型进行视觉-语言预训练(VLP),关键在于促进跨模态对齐。然而,由于大型语言模型(LLMs)在单模态预训练期间未见过图像,冻结它们使得视觉-语言对齐尤其具有挑战性。在这方面,现有方法(例如Frozen(Tsimpoukelli等,2021)、Flamingo(Alayrac等,2022))依赖于图像到文本生成的损失,我们证明这不足以弥合模态差距。为了实现与冻结单模态模型的有效视觉-语言对齐,我们提出了一种查询转换器(Querying Transformer,Q-Former),它通过一种新的两阶段预训练策略进行预训练。如图1所示,Q-Former是一个轻量级的转换器,它采用一组可学习的查询向量从冻结的图像编码器中提取视觉特征。它充当冻结图像编码器和冻结LLM之间的信息瓶颈,其中它将最有用的视觉特征提供给LLM以输出所需的文本。在第一个预训练阶段,我们进行视觉-语言表示学习,强制Q-Former学习与文本最相关的视觉表示。在第二个预训练阶段,我们通过将Q-Former的输出连接到冻结的LLM来进行视觉到语言的生成学习,并训练Q-Former,使其输出的视觉表示可以被LLM解释。
我们将我们的VLP框架命名为BLIP-2:使用冻结单模态模型进行语言-图像预训练引导。BLIP-2的关键优势包括:
- BLIP-2有效地利用了冻结的预训练图像模型和语言模型。我们通过一个在两阶段预训练的Q-Former来弥合模态差距:表示学习阶段和生成学习阶段。BLIP-2在包括视觉问答、图像描述和图像-文本检索在内的各种视觉-语言任务上实现了最先进的性能。
- 由LLMs(例如OPT(Zhang等,2022)、FlanT5(Chung等,2022))驱动,BLIP-2可以被提示执行遵循自然语言指令的零样本图像到文本生成,这使得新兴能力如视觉知识推理、视觉对话等成为可能(参见图4中的示例)。
- 由于使用了冻结的单模态模型和轻量级的Q-Former,BLIP-2比现有的最先进方法更具计算效率。例如,BLIP-2在零样本VQAv2上比Flamingo(Alayrac等,2022)高出8.7%,同时使用的可训练参数数量少了54倍。此外,我们的结果表明,BLIP-2是一种通用方法,可以利用更先进的单模态模型以获得更好的VLP性能。
2. 相关工作
2.1. 端到端视觉-语言预训练
视觉-语言预训练旨在学习多模态基础模型,以提高各种视觉和语言任务的性能。根据下游任务的不同,提出了不同的模型架构,包括双编码器架构(Radford等,2021;Jia等,2021)、融合编码器架构(Tan & Bansal,2019;Li等,2021)、编码器-解码器架构(Cho等,2021;Wang等,2021b;Chen等,2022b),以及最近的统一转换器架构(Li等,2022;Wang等,2022b)。多年来,还提出了各种预训练目标,并逐渐收敛到一些经过时间考验的目标:图像-文本对比学习(Radford等,2021;Yao等,2022;Li等,2021;2022)、图像-文本匹配(Li等,2021;2022;Wang等,2021a)和(掩码)语言建模(Li等,2021;2022;Yu等,2022;Wang等,2022b)。大多数VLP方法使用大规模图像-文本对数据集进行端到端预训练。随着模型规模的不断增加,预训练可能会产生极高的计算成本。此外,端到端预训练模型利用现成的单模态预训练模型(如LLMs(Brown等,2020;Zhang等,2022;Chung等,2022))是不灵活的。
2.2. 模块化视觉-语言预训练
与我们更相似的是那些利用现成预训练模型并在VLP期间保持其冻结的方法。一些方法冻结图像编码器,包括早期采用冻结对象检测器提取视觉特征的工作(Chen等,2020;Li等,2020;Zhang等,2021),以及最近的LiT(Zhai等,2022),它使用冻结的预训练图像编码器进行CLIP(Radford等,2021)预训练。一些方法冻结语言模型以利用LLMs的知识进行视觉到语言的生成任务(Tsimpoukelli等,2021;Alayrac等,2022;Chen等,2022a;Manas等,2023;Tiong等,2022;Guo等,2022)。使用冻结LLM的关键挑战是将视觉特征与文本空间对齐。为了实现这一点,Frozen(Tsimpoukelli等,2021)微调了一个图像编码器,其输出直接用作LLM的软提示。Flamingo(Alayrac等,2022)将新的交叉注意力层插入LLM以注入视觉特征,并在数十亿图像-文本对上预训练新层。两种方法都采用了语言建模损失,其中语言模型根据图像生成文本。与现有方法不同,BLIP-2可以有效地利用冻结的图像编码器和冻结的LLMs进行各种视觉-语言任务,以更低的计算成本实现更强的性能。
3. 方法
我们提出了BLIP-2,一种新的视觉-语言预训练方法,它从冻结的预训练单模态模型中引导。为了弥合模态差距,我们提出了一种查询转换器(Q-Former),它在两个阶段进行预训练:(1)使用冻结图像编码器的视觉-语言表示学习阶段和(2)使用冻结LLM的视觉到语言生成学习阶段。本节首先介绍Q-Former的模型架构,然后描述两阶段预训练过程。
3.1. 模型架构
我们提出Q-Former作为可训练模块,以弥合冻结图像编码器和冻结LLM之间的差距。它从图像编码器中提取固定数量的输出特征,与输入图像分辨率无关。如图2所示,Q-Former由两个共享相同自注意力层的转换器子模块组成:(1)一个与冻结图像编码器交互以提取视觉特征的图像转换器,(2)一个既可以作为文本编码器又可以作为文本解码器的文本转换器。我们创建了一组固定数量的可学习查询嵌入作为图像转换器的输入。查询通过自注意力层相互交互,并通过交叉注意力层(每隔一个转换器块插入)与冻结的图像特征交互。查询还可以通过相同的自注意力层与文本交互。根据预训练任务,我们应用不同的自注意力掩码来控制查询-文本交互。我们使用BERTbase(Devlin等,2019)的预训练权重初始化Q-Former,而交叉注意力层是随机初始化的。Q-Former总共包含188M参数。请注意,查询被视为模型参数。
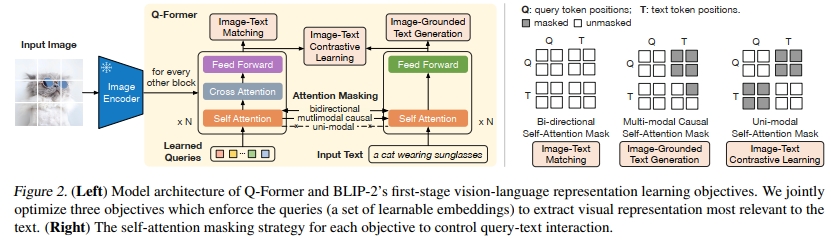
在我们的实验中,我们使用了32个查询,每个查询的维度为768(与Q-Former的隐藏维度相同)。我们用Z表示输出查询表示。Z的大小(32 × 768)远小于冻结图像特征的大小(例如,ViT-L/14的大小为257 × 1024)。这种瓶颈架构与我们的预训练目标共同作用,迫使查询提取与文本最相关的视觉信息。
3.2. 从冻结图像编码器中引导视觉-语言表示学习
在表示学习阶段,我们将Q-Former连接到冻结的图像编码器,并使用图像-文本对进行预训练。我们的目标是训练Q-Former,使得查询能够学习提取对文本最具信息量的视觉表示。受BLIP(Li等,2022)的启发,我们联合优化了三个预训练目标,这些目标共享相同的输入格式和模型参数。每个目标在查询和文本之间采用不同的注意力掩码策略来控制它们的交互(见图2)。
图像-文本对比学习(ITC)学习对齐图像表示和文本表示,以最大化它们的互信息。它通过对比正对的图像-文本相似性与负对的相似性来实现这一点。我们将图像转换器的输出查询表示Z与文本转换器的文本表示t对齐,其中t是[CLS]标记的输出嵌入。由于Z包含多个输出嵌入(每个查询一个),我们首先计算每个查询输出与t之间的成对相似性,然后选择最高的一个作为图像-文本相似性。为了避免信息泄露,我们采用了单模态自注意力掩码,其中查询和文本不允许相互看到。由于使用了冻结的图像编码器,与端到端方法相比,我们可以在每个GPU上容纳更多的样本。因此,我们使用批次内负样本而不是BLIP中的动量队列。
基于图像的文本生成(ITG)损失训练Q-Former在给定输入图像作为条件的情况下生成文本。由于Q-Former的架构不允许冻结的图像编码器和文本标记之间的直接交互,生成文本所需的信息必须首先由查询提取,然后通过自注意力层传递给文本标记。因此,查询被迫提取捕捉文本所有信息的视觉特征。我们采用多模态因果自注意力掩码来控制查询-文本交互,类似于UniLM(Dong等,2019)中使用的掩码。查询可以相互关注,但不能关注文本标记。每个文本标记可以关注所有查询及其之前的文本标记。我们还将[CLS]标记替换为新的[DEC]标记作为第一个文本标记,以指示解码任务。
图像-文本匹配(ITM)旨在学习图像和文本表示之间的细粒度对齐。这是一个二元分类任务,模型需要预测图像-文本对是正对(匹配)还是负对(不匹配)。我们使用双向自注意力掩码,其中所有查询和文本可以相互关注。因此,输出查询嵌入Z捕捉了多模态信息。我们将每个输出查询嵌入输入到一个二类线性分类器中以获得一个logit,并平均所有查询的logits作为输出匹配分数。我们采用了Li等(2021;2022)中的硬负样本挖掘策略来创建信息丰富的负对。
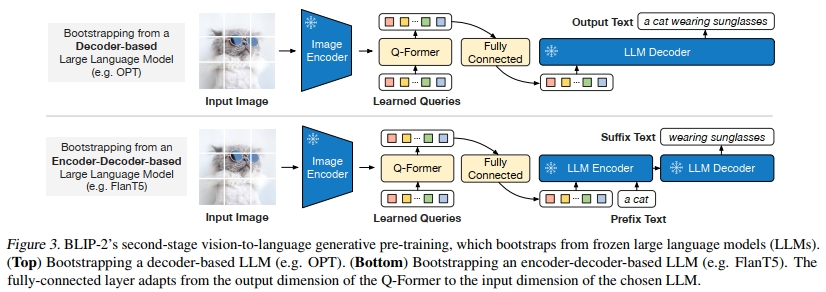
3.3. 从冻结的LLM中引导视觉到语言的生成学习
在生成预训练阶段,我们将Q-Former(附带冻结的图像编码器)连接到冻结的LLM,以利用LLM的生成语言能力。如图3所示,我们使用一个全连接(FC)层将输出查询嵌入Z线性投影到与LLM的文本嵌入相同的维度。投影后的查询嵌入随后被添加到输入文本嵌入之前。它们作为软视觉提示,将LLM条件化于Q-Former提取的视觉表示。由于Q-Former已经预训练为提取具有语言信息量的视觉表示,它有效地充当了信息瓶颈,将最有用的信息传递给LLM,同时去除不相关的视觉信息。这减轻了LLM学习视觉-语言对齐的负担,从而缓解了灾难性遗忘问题。
我们实验了两种类型的LLM:基于解码器的LLM和基于编码器-解码器的LLM。对于基于解码器的LLM,我们使用语言建模损失进行预训练,其中冻结的LLM的任务是基于Q-Former的视觉表示生成文本。对于基于编码器-解码器的LLM,我们使用前缀语言建模损失进行预训练,其中我们将文本分为两部分。前缀文本与视觉表示连接作为LLM编码器的输入,后缀文本用作LLM解码器的生成目标。
3.4. 模型预训练
预训练数据:我们使用与BLIP相同的预训练数据集,总计129M张图像,包括COCO(Lin等,2014)、Visual Genome(Krishna等,2017)、CC3M(Sharma等,2018)、CC12M(Changpinyo等,2021)、SBU(Ordonez等,2011)以及来自LAION400M数据集(Schuhmann等,2021)的115M张图像。我们采用CapFilt方法(Li等,2022)为网络图像创建合成标题。具体来说,我们使用BLIPlarge标题生成模型生成10个标题,并根据CLIP ViT-L/14模型生成的图像-文本相似性对合成标题和原始网络标题进行排序。我们为每张图像保留前两个标题作为训练数据,并在每个预训练步骤中随机选择一个。
预训练图像编码器和LLM:对于冻结的图像编码器,我们探索了两种最先进的预训练视觉Transformer模型:(1)来自CLIP的ViT-L/14(Radford等,2021)和(2)来自EVA-CLIP的ViT-g/14(Fang等,2022)。我们移除了ViT的最后一层,并使用倒数第二层的输出特征,这略微提高了性能。对于冻结的语言模型,我们探索了基于解码器的LLM的无监督训练OPT模型家族(Zhang等,2022),以及基于编码器-解码器的LLM的指令训练FlanT5模型家族(Chung等,2022)。
预训练设置:我们在第一阶段预训练250k步,在第二阶段预训练80k步。在第一阶段,ViT-L/ViT-g的批量大小为2320/1680;在第二阶段,OPT/FlanT5的批量大小为1920/1520。在预训练期间,我们将冻结的ViT和LLM的参数转换为FP16,除了FlanT5使用BFloat16。我们发现与使用32位模型相比,性能没有下降。由于使用了冻结模型,我们的预训练比现有的大规模VLP方法更具计算友好性。例如,使用单台16-A100(40G)机器,我们最大的模型(ViT-g和FlanT5-XXL)在第一阶段需要不到6天,在第二阶段需要不到3天。所有模型使用相同的预训练超参数。我们使用AdamW优化器(Loshchilov & Hutter,2017),
β
1
=
0.9
,
β
1
=
0.98
,
\beta _ { 1 } = 0 . 9 , \, \beta _ { 1 } = 0 . 9 8 ,
β1=0.9,β1=0.98, 权重衰减为0.05。我们使用余弦学习率衰减,峰值学习率为1e-4,线性预热为2k步。第二阶段的最小学习率为5e-5。我们使用224x224大小的图像,并通过随机调整大小裁剪和水平翻转进行增强。


4. 实验
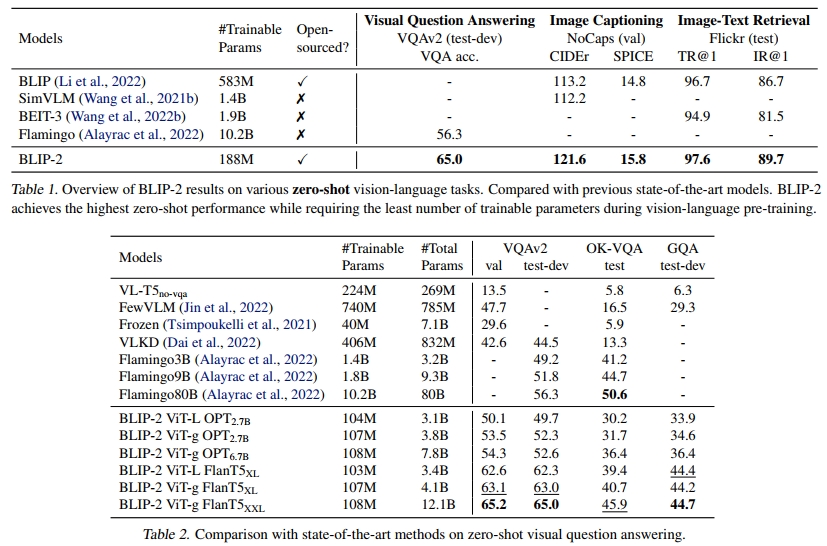
表1概述了BLIP-2在各种零样本视觉-语言任务上的表现。与之前的最先进模型相比,BLIP-2在视觉-语言预训练期间需要显著减少的可训练参数数量的同时,实现了性能的提升。
4.1. 指令驱动的零样本图像到文本生成
BLIP-2有效地使LLM能够理解图像,同时保留其遵循文本提示的能力,这使得我们可以通过指令控制图像到文本的生成。我们只需将文本提示附加到视觉提示之后作为LLM的输入。图4展示了广泛的零样本图像到文本生成能力的示例,包括视觉知识推理、视觉常识推理、视觉对话、个性化图像到文本生成等。
零样本视觉问答(VQA):我们对零样本视觉问答任务进行了定量评估。对于OPT模型,我们使用提示“Question: {} Answer:”。对于FlanT5模型,我们使用提示“Question: {} Short answer:”。在生成过程中,我们使用束搜索(beam search),束宽度为5。我们还将长度惩罚设置为-1,以鼓励生成更短的答案,从而更好地与人工标注对齐。如表2所示,BLIP-2在VQAv2(Goyal等,2017)和GQA(Hudson & Manning,2019)数据集上取得了最先进的结果。尽管可训练参数数量减少了54倍,BLIP-2在VQAv2上的表现优于Flamingo80B 8.7%。在OK-VQA(Marino等,2019)数据集上,BLIP-2仅次于Flamingo80B。我们推测这是因为OK-VQA更关注开放世界知识而非视觉理解,而Flamingo80B中使用的70B Chinchilla(Hoffmann等,2022)语言模型比11B FlanT5XXL拥有更多的知识。
我们从表2中得出了一个有希望的观察结果:更强的图像编码器或更强的LLM都能带来更好的性能。这一观察得到了以下几个事实的支持:(1)对于OPT和FlanT5,ViT-g的表现优于ViT-L。(2)在同一LLM家族中,较大的模型优于较小的模型。(3)FlanT5作为一种经过指令调优的LLM,在VQA任务上优于无监督训练的OPT。这一观察验证了BLIP-2作为一种通用的视觉-语言预训练方法,能够有效利用视觉和自然语言社区的快速发展。
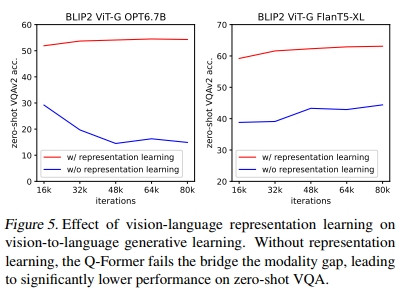
视觉-语言表示学习的效果:第一阶段的表示学习预训练使Q-Former学习与文本相关的视觉特征,从而减轻了LLM学习视觉-语言对齐的负担。如果没有表示学习阶段,Q-Former仅依赖视觉到语言的生成学习来弥合模态差距,这与Flamingo中的Perceiver Resampler类似。图5展示了表示学习对生成学习的影响。如果没有表示学习,两种类型的LLM在零样本VQA任务上的表现显著下降。特别是,OPT遭受了灾难性遗忘,随着训练的进行,性能急剧下降。
4.2. 图像描述生成
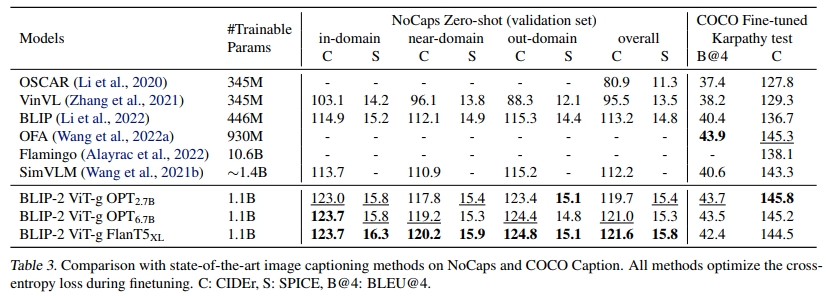
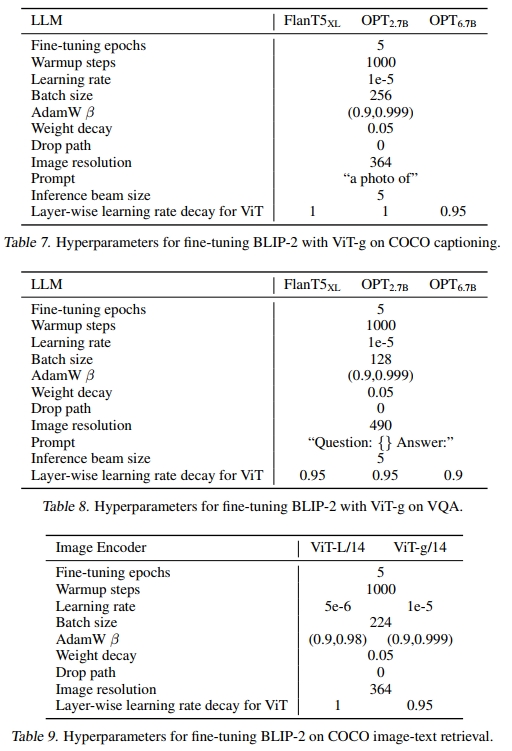
我们对BLIP-2模型进行了图像描述生成任务的微调,该任务要求模型为图像的视觉内容生成文本描述。我们使用提示“a photo of”作为LLM的初始输入,并通过语言建模损失训练模型生成描述。在微调过程中,我们保持LLM冻结,并更新Q-Former和图像编码器的参数。我们使用ViT-g和各种LLM进行了实验。详细的超参数可以在附录中找到。我们在COCO数据集上进行微调,并在COCO测试集和零样本迁移到NoCaps(Agrawal等,2019)验证集上进行评估。
结果如表3所示。BLIP-2在NoCaps数据集上取得了显著的性能提升,超越了现有方法,展示了其对域外图像的强大泛化能力。
4.3. 视觉问答
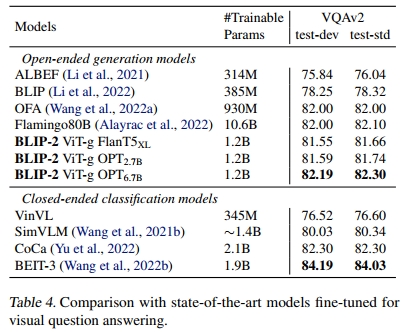
在给定标注的VQA数据的情况下,我们对Q-Former和图像编码器的参数进行了微调,同时保持LLM冻结。我们使用开放式答案生成损失进行微调,其中LLM接收Q-Former的输出和问题作为输入,并被要求生成答案。为了提取与问题更相关的图像特征,我们进一步将Q-Former条件化于问题。具体来说,问题标记作为输入提供给Q-Former,并通过自注意力层与查询交互,这可以引导Q-Former的交叉注意力层聚焦于更具信息量的图像区域。遵循BLIP的方法,我们的VQA数据包括来自VQAv2的训练和验证集,以及来自Visual Genome的训练样本。表4展示了BLIP-2在开放式生成模型中的最先进结果。
4.4. 图像-文本检索
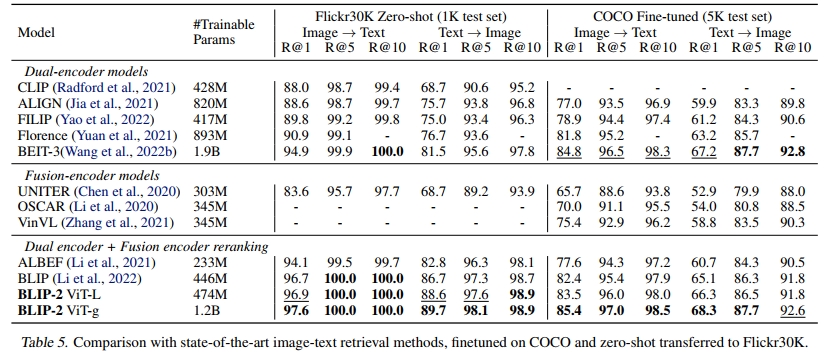
由于图像-文本检索不涉及语言生成,我们直接对第一阶段预训练的模型(不包含LLM)进行微调。具体来说,我们在COCO数据集上使用与预训练相同的目标(即ITC、ITM和ITG)对图像编码器和Q-Former进行微调。然后,我们在COCO和Flickr30K(Plummer等,2015)数据集上评估模型的图像到文本检索和文本到图像检索性能。在推理过程中,我们遵循Li等(2021;2022)的方法,首先基于图像-文本特征相似性选择k=128个候选样本,然后基于成对ITM分数进行重新排序。我们使用ViT-L和ViT-g作为图像编码器进行实验。详细的超参数可以在附录中找到。
结果如表5所示。BLIP-2在零样本图像-文本检索任务上取得了最先进的性能,显著优于现有方法。
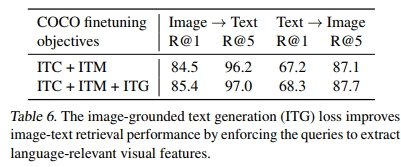
ITC和ITM损失对于图像-文本检索至关重要,因为它们直接学习图像-文本相似性。在表6中,我们展示了ITG(基于图像的文本生成)损失对图像-文本检索也有益处。这一结果支持了我们在设计表示学习目标时的直觉:ITG损失迫使查询提取与文本最相关的视觉特征,从而改善了视觉-语言对齐。
5. 局限性
最近的LLM可以在给定少量示例的情况下进行上下文学习。然而,我们在BLIP-2的实验中没有观察到在提供上下文VQA示例时LLM的VQA性能有所提升。我们将缺乏上下文学习能力归因于我们的预训练数据集,其中每个样本仅包含一个图像-文本对。LLM无法从中学习单个序列中多个图像-文本对之间的相关性。Flamingo论文中也报告了相同的观察结果,该论文使用了每个序列包含多个图像-文本对的闭源交错图像和文本数据集(M3W)。我们计划在未来的工作中创建类似的数据集。
BLIP-2的图像到文本生成可能会因各种原因产生不理想的结果,包括LLM的知识不准确、激活了错误的推理路径或没有关于新图像内容的最新信息(见图7)。此外,由于使用了冻结模型,BLIP-2继承了LLM的风险,例如输出冒犯性语言、传播社会偏见或泄露私人信息。补救方法包括使用指令引导模型生成或在去除有害内容的过滤数据集上进行训练。
6. 结论
我们提出了BLIP-2,一种通用且计算高效的视觉-语言预训练方法,利用冻结的预训练图像编码器和LLM。BLIP-2在各种视觉-语言任务上实现了最先进的性能,同时在预训练期间仅需少量可训练参数。BLIP-2还展示了在零样本指令驱动的图像到文本生成中的新兴能力。我们认为BLIP-2是构建多模态对话AI代理的重要一步。
论文名称:
BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
论文地址:
https://proceedings.mlr.press/v202/li23q/li23q.pdf


















 956
956

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











