










本地部署文档问答webdemo
- 支持 pdf
- 支持 txt
- 支持 doc/docx
- 支持 源文档索引
你的点赞和收藏是我持续分享优质内容的动力哦~
废话不多说直接看效果
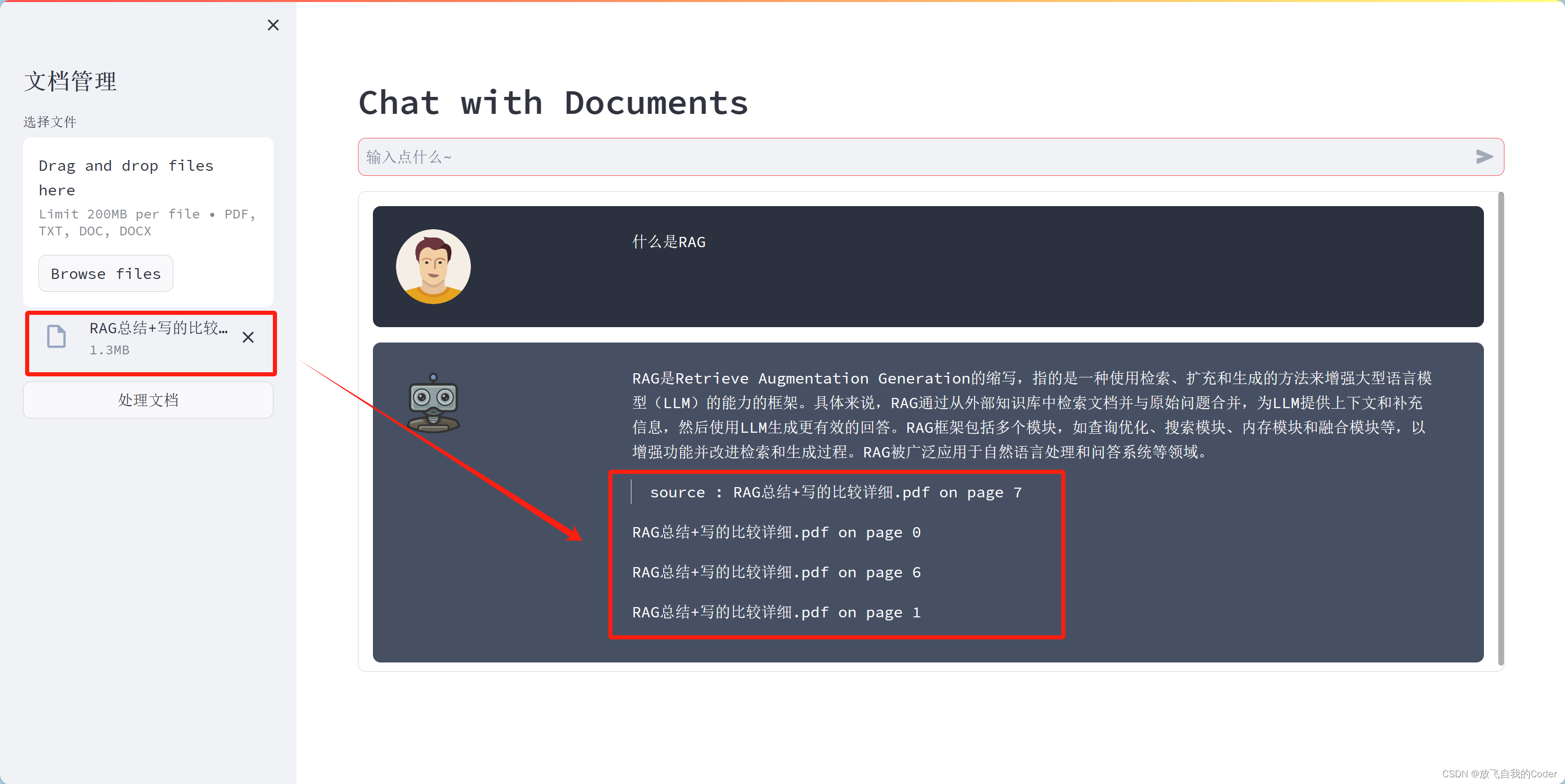
准备
- 首先创建一个新环境(选择性)
conda create -n chatwithdocs python=3.11
conda activate chatwithdocs
- 新建一个
requirements.txt文件
streamlit
python-docx
PyPDF2
faiss-gpu
langchain
langchain-core
langchain-community
- 然后安装相应的包
pip install -r requirements.txt -U
代码
创建一个app.py文件, 把下边的复制进去
注意:替换你自己的api-key和base-url
import streamlit as st
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import FAISS
from langchain_openai import ChatOpenAI
from langchain_openai import OpenAIEmbeddings
from langchain_core.documents import Document
from langchain.chains import ConversationalRetrievalChain
import docx
from PyPDF2 import PdfReader
import os
os.environ['OPENAI_API_KEY']='xxx'
# os.environ['OPENAI_BASE_URL']='xxx' # 看你的情况
st.set_page_config(page_title="Chat with Documents", page_icon=":robot:", layout="wide")
st.markdown(
"""<style>
.chat-message {
padding: 1.5rem; border-radius: 0.5rem; margin-bottom: 1rem; display: flex
}
.chat-message.user {
background-color: #2b313e
}
.chat-message.bot {
background-color: #475063
}
.chat-message .avatar {
width: 20%;
}
.chat-message .avatar img {
max-width: 78px;
max-height: 78px;
border-radius: 50%;
object-fit: cover;
}
.chat-message .message {
width: 80%;
padding: 0 1.5rem;
color: #fff;
}
.stDeployButton {
visibility: hidden;
}
#MainMenu {visibility: hidden;}
footer {visibility: hidden;}
.block-container {
padding: 2rem 4rem 2rem 4rem;
}
.st-emotion-cache-16txtl3 {
padding: 3rem 1.5rem;
}
</style>
# """,
unsafe_allow_html=True,
)
bot_template = """
<div class="chat-message bot">
<div class="avatar">
<img src="https://cdn.icon-icons.com/icons2/1371/PNG/512/robot02_90810.png" style="max-height: 78px; max-width: 78px; border-radius: 50%; object-fit: cover;">
</div>
<div class="message">{{MSG}}</div>
</div>
"""
user_template = """
<div class="chat-message user">
<div class="avatar">
<img src="https://www.shareicon.net/data/512x512/2015/09/18/103160_man_512x512.png" >
</div>
<div class="message">{{MSG}}</div>
</div>
"""
def get_pdf_text(pdf_docs):
docs = []
for document in pdf_docs:
if document.type == "application/pdf":
pdf_reader = PdfReader(document)
for idx, page in enumerate(pdf_reader.pages):
docs.append(
Document(
page_content=page.extract_text(),
metadata={"source": f"{document.name} on page {idx}"},
)
)
elif (
document.type
== "application/vnd.openxmlformats-officedocument.wordprocessingml.document"
):
doc = docx.Document(document)
for idx, paragraph in enumerate(doc.paragraphs):
docs.append(
Document(
page_content=paragraph.text,
metadata={"source": f"{document.name} in paragraph {idx}"},
)
)
elif document.type == "text/plain":
text = document.getvalue().decode("utf-8")
docs.append(Document(page_content=text, metadata={"source": document.name}))
return docs
def get_text_chunks(docs):
text_splitter = RecursiveCharacterTextSplitter(chunk_size=512, chunk_overlap=0)
docs_chunks = text_splitter.split_documents(docs)
return docs_chunks
def get_vectorstore(docs_chunks):
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(docs_chunks, embedding=embeddings)
return vectorstore
def get_conversation_chain(vectorstore):
llm = ChatOpenAI()
conversation_chain = ConversationalRetrievalChain.from_llm(
llm=llm,
retriever=vectorstore.as_retriever(),
return_source_documents=True,
)
return conversation_chain
def handle_userinput_pdf(user_question):
chat_history = st.session_state.chat_history
response = st.session_state.conversation(
{"question": user_question, "chat_history": chat_history}
)
st.session_state.chat_history.append(("user", user_question))
st.session_state.chat_history.append(("assistant", response["answer"]))
st.write(
user_template.replace("{{MSG}}", user_question),
unsafe_allow_html=True,
)
sources = response["source_documents"]
source_names = set([i.metadata["source"] for i in sources])
src = "\n\n".join(source_names)
src = f"\n\n> source : {src}"
message = st.session_state.chat_history[-1]
st.write(bot_template.replace("{{MSG}}", message[1] + src), unsafe_allow_html=True)
def show_history():
chat_history = st.session_state.chat_history
for i, message in enumerate(chat_history):
if i % 2 == 0:
st.write(
user_template.replace("{{MSG}}", message[1]),
unsafe_allow_html=True,
)
else:
st.write(
bot_template.replace("{{MSG}}", message[1]), unsafe_allow_html=True
)
def main():
st.header("Chat with Documents")
# 初始化会话状态
if "conversation" not in st.session_state:
st.session_state.conversation = None
if "chat_history" not in st.session_state:
st.session_state.chat_history = []
with st.sidebar:
st.title("文档管理")
pdf_docs = st.file_uploader(
"选择文件",
type=["pdf", "txt", "doc", "docx"],
accept_multiple_files=True,
)
if st.button(
"处理文档",
on_click=lambda: setattr(st.session_state, "last_action", "pdf"),
use_container_width=True,
):
if pdf_docs:
with st.spinner("Processing"):
docs = get_pdf_text(pdf_docs)
docs_chunks = get_text_chunks(docs)
vectorstore = get_vectorstore(docs_chunks)
st.session_state.conversation = get_conversation_chain(vectorstore)
else:
st.warning("记得上传文件哦~~")
def clear_history():
st.session_state.chat_history = []
if st.session_state.chat_history:
st.button("清空对话", on_click=clear_history, use_container_width=True)
with st.container():
user_question = st.chat_input("输入点什么~")
with st.container(height=400):
show_history()
if user_question:
if st.session_state.conversation is not None:
handle_userinput_pdf(user_question)
else:
st.warning("记得上传文件哦~~")
if __name__ == "__main__":
main()
启动
- 自动在浏览器打开
streamlit run app.py















 420
420











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











