







论文介绍
谷歌提出的GoogLeNet(Inception-V1)深度卷积神经网络结构,在ImageNet 2014年图像分类竞赛以top-5误差6.7%获得冠军(亚军为VGG)。
使用Inception模块,引入并行结构和不同尺寸的卷积核,对传统的串行堆叠CNN充分分解、解耦。
加入1 x 1卷积,降低参数量和计算量。辅助分类头将梯度注入网络浅层实现正则化,实现多层次预测。
其后续变种包括BN-Inception、Inception-V2、V3、V4、Inception-ResNet、Xception。
题目:Going Deeper with Convolutions
DOI:10.1109/CVPR.2015.7298594
时间:2014-09-17上传于arxiv
会议:2015-CVPR
机构:Google
作者:Christian Szegedy和贾扬清 等
论文链接:https://arxiv.org/abs/1409.4842
代码链接:ttps://pytorch.org/docs/1.1.0/_modules/torchvision/models/googlenet.html#googlenet
视频讲解:https://www.bilibili.com/video/BV17g411L7Se
GoogLeNet(Inception-V1)不是一味的增加深度,而且注重模块的改进。
Inception——出自电影《盗梦空间》
LeNet——大写L向手写数字识别LeNet-5[10]致敬
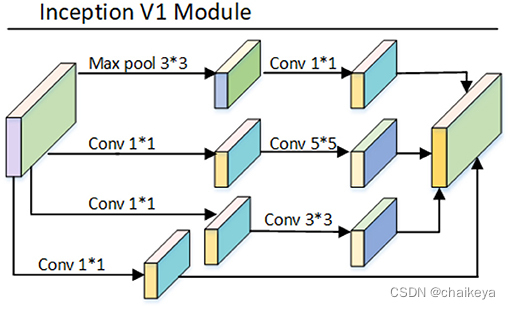
Inception Module
图(a)最初的Inception 模块;有四个通道,有1*1、3*3、5*5卷积核,该结构有几个特点:
- 使用这些大小卷积核,没有什么特殊含义,主要方便对齐,只要padding = 0、1、2,就可以得到相同大小的特征图,可以顺利concat。
- 采用大小不同的卷积核,意味着感受野的大小不同,就可以得到不同尺度的特征。
- 采用比较大的卷积核即5*5,因为有些相关性可能隔的比较远,用大的卷积核才能学到此特征。


【Network In Network】[12]两个贡献:
- 1x1卷积核先降维,再升维,减少参数量。
- 用Global Average Pooling(GAP)取代全连接层,减少参数数量。
1x1卷积作用:
- 降维或升维(调节1x1卷积核的个数进行降维或者升维)
- 跨通道信息交融(实现降维和升维的操作其实就是channel间信息的线性组合变化)
- 减少参数量(CNN参数个数 = 卷积核尺寸×卷积核深度 × 卷积核组数 = 卷积核尺寸 × 输入特征矩阵深度 × 输出特征矩阵深度)
- 增加模型的深度,提高了模型的非线性表达能力。
Inception-V1 Module
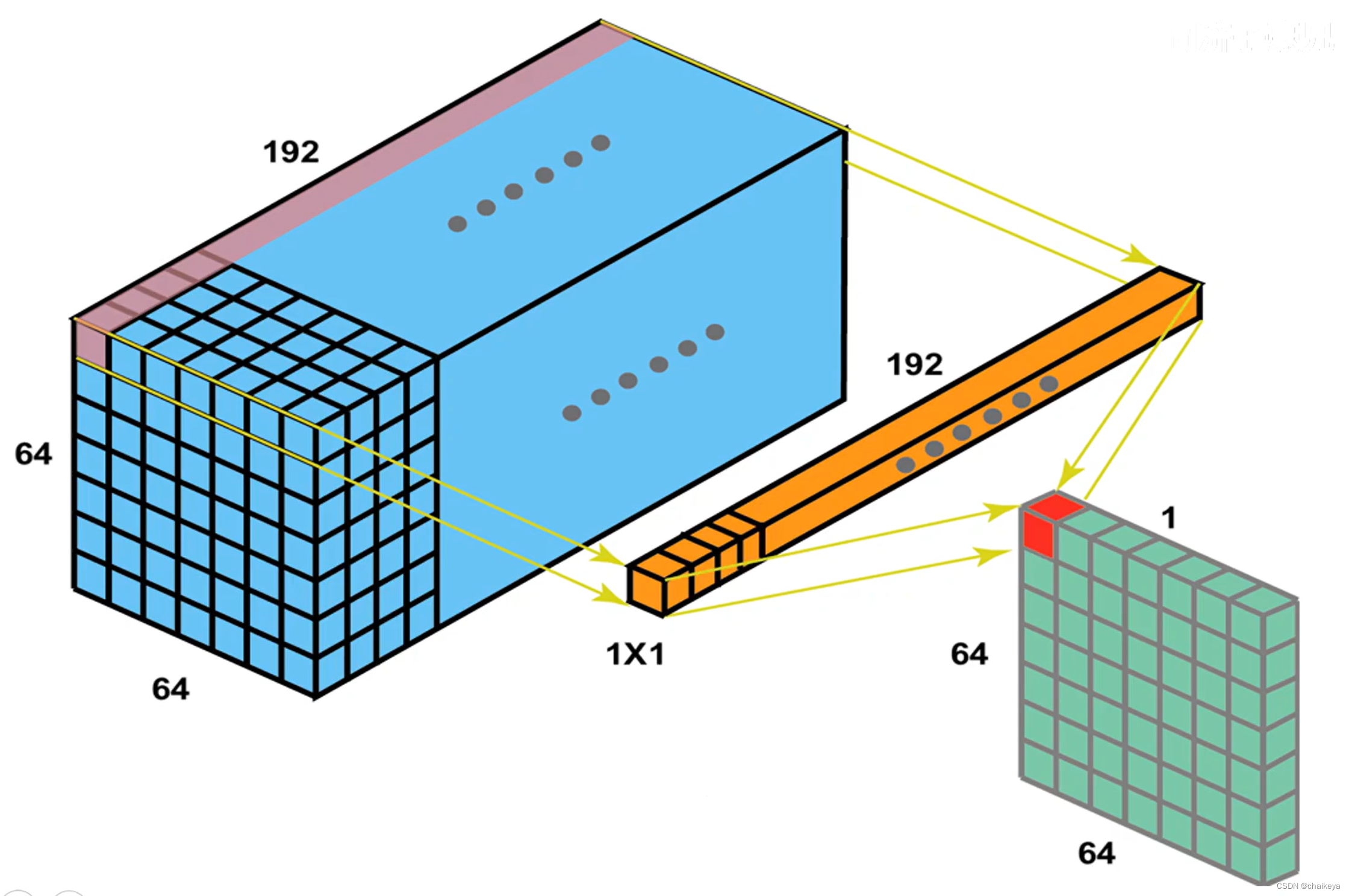
最初的Inception模块有个缺点,5*5的卷积核的计算量太大。那么作者想到了第二个结构,用1*1的卷积核进行降维。
每一个卷积核生成一个二维的feature map,调节1x1卷积核的个数进行降维或者升维。
1*1 的卷积被用来在使用 3*3 和 5*5 卷积之前降维,同时也被用来修正线性激活特性。
(b) 降维之后的 Inception 模型;

GAP:
GAP取每一层的平均值,减少参数。
全连接存在的问题:参数量过大,降低了训练的速度,且很容易过拟合。全连接层将卷积层生成的 feature map 展平成一维向量之后再进行分类,而 GAP 的思路就是将上述两个过程合二为一。

卷积—GAP—每个权重乘每个channel—结果反应了类别在原图上的关注区域。
GAP保留了原来channel的信息,w信息—channel信息—空间信息。
用于图像分类,也可以完成定位或者语义分割的弱监督学习或半监督学习。
池化层会引入平移不变性,虽然池化层丢失了空间像素精确信息,但我们依然能用CNN进行定位和目标检测。


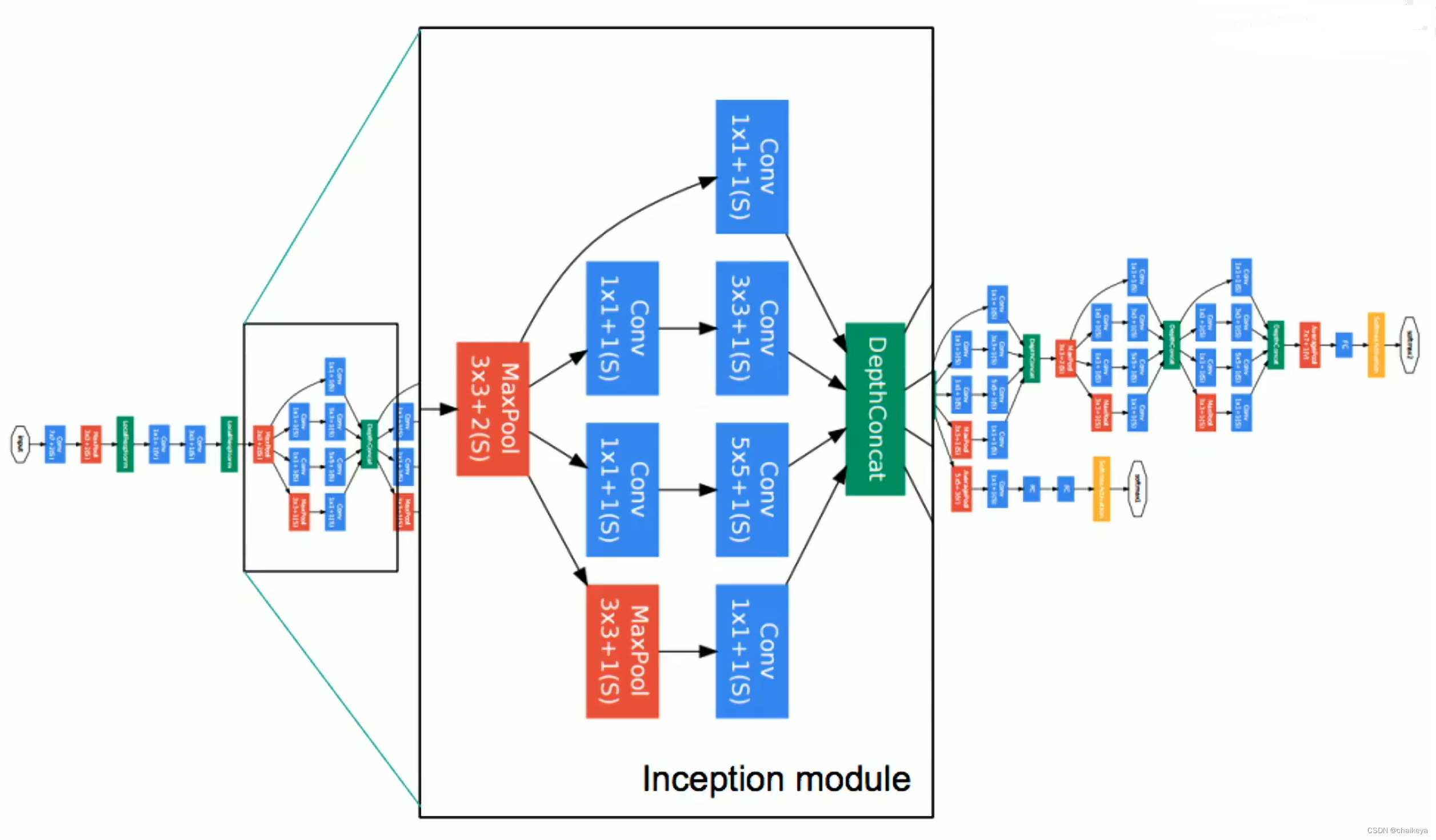
GoogLeNet网络模型
- 设计一个代号为 Inception 的深度卷积神经网络架构。(基于赫布学习规则(Hebbian principle)和多尺度处理的直觉知识来设计的)
- 多尺度的卷积核并行处理:利用视觉信息多尺度并行分开处理再融合汇总[2]。下一步可以从不同尺度提取特征。不管目标在图像的哪个位置总有一个卷积核可以提取到它的特征。
- 用稀疏连接取代密集连接:每一个Inception是密集的,但是GoogLeNet把它变成了四路,再把四路进行融合,就变成了一个稀疏的运算。用密集的模块去近似出局部最优稀疏结构。并利用现有资源的基础上,实现了模型的稀疏性。
- 用到了1*1卷积和全局平均池化GAP:充分利用计算资源,提高网络计算资源的利用率,在计算量不变的情况下,可以增加模型的宽度和深度,在堆叠模块时计算量不会爆炸。[12]
- 另外还有两个辅助分类器:用在4a输出和4d输出,总有三个输出层,可以尽快学到可分类的特征。(正则化,防止梯度消失)
- 为了训练时的内存效率,底层先用普通卷积层,后面用Inception模块堆叠。



辅助分类器:
通过添加连接中间层的附加分类器,我们将能在分类中较早的步骤就增强识别性,增强获得的反向传播的梯度信号,并给予额外的正规化。这些分类器把更小的卷积网络添加到 Inception(4a)和(4d)模块的输出之上。在训练的时候,它们造成的损失按照折算出来的权重被添加到网络的总损失里面(附加分类器所占的权重为 0.3)。在测试阶段这些辅助网络就会被丢弃。
- 一个拥有尺寸为 5*5 的滤波器而且步长为 3 的平均池化层,在(4a)输出 4*4*512,在(4d)步骤输出 4*4*528。
- 一个拥有 128 个滤波器的 1*1 的卷积来降维和修正线性激活
- 一个有 1024 个神经元和修正线性激活的全连接层
- 一个 70%比例下降输出的 dropout 层
- 一个拥有用 softmax 损失来作为分类器的线性层(作为主要分类器来预测 1000 个类,但是在测试的时候移除)

损失函数:
L=L最后+0.3*L辅助1+0.3*L辅助2
实验结果

Inception-V1:在用了1x1卷积之后计算量(ops)减少
Inception-V2:一个5x5变成两个3x3,减少参数量,引入非线性,并且感受野是一样的。
Inception-V3:即可沿深度方向拆分,也可以沿宽度方向拆。




参考论文:
用稀疏分散的网络取代以前庞大臃肿的网络:[2] Provable bounds for learning some deep representations
R-CNN:[6] Rich feature hierarchies for accurate object detection and semantic segmentation
LeNet-5奠定CNN的基础结构:[10] Backpropagation applied to handwritten zip code recognition
1x1卷积/GAP:[12] Network In Network
Deepose :[19] Deeppose: Human pose estimation via deep neural networks














 1531
1531











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









