







一、目标检测基本概念
(1)目标检测的定义
目标检测是计算机视觉领域的一项关键任务,它旨在识别图像或视频帧中出现的所有感兴趣目标(物体)的位置和类别。简而言之,目标检测不仅需要判断图像中存在哪些类型的物体,还要精确地标记出每个物体的具体位置,通常通过在物体周围绘制一个边界框(BoundingBox)来实现。这项技术结合了图像分类和对象定位,是自动驾驶、视频监控、医学影像分析等多种应用的基础。

(2)目标框的定义方式
目标框(Bounding Box)是用来界定目标物体在图像中精确位置的矩形框。通常有两种方法:
- 方法一:目标框由四个坐标值定义,左上角的x和y坐标,以及右下角的x和y坐标。这四个值确定了一个恰好包围物体的矩形区域,使得每个目标物体都能被明确地区分和定位。
- 方法二:使用中心点坐标加上宽度和高度。这种方式下,目标框由五个值定义,中心点的x和y坐标,以及边界框的宽度和高度。中心点坐标表示目标框中心在图像中的位置,而宽度和高度则给出了边界框的尺寸。这种表示法有时候更便于计算和调整边界框的位置,尤其是在需要对目标框进行缩放或平移操作时。

在实际应用中,目标框的坐标可以是绝对像素值,也可以是相对于图像尺寸的比例值。
(3)什么是交并比(IoU)
交并比(Interp over Union)是衡量两个边界框重叠程度的一个重要指标,广泛应用于目标检测、图像分割等计算机视觉任务的评估中。IoU计算方法是取两个边界框相交面积与它们并集面积的比值。数学表达式为:
其中,交集面积是两个边界框共同覆盖的区域大小,而并集面积是这两个边界框覆盖的所有区域大小的总和。
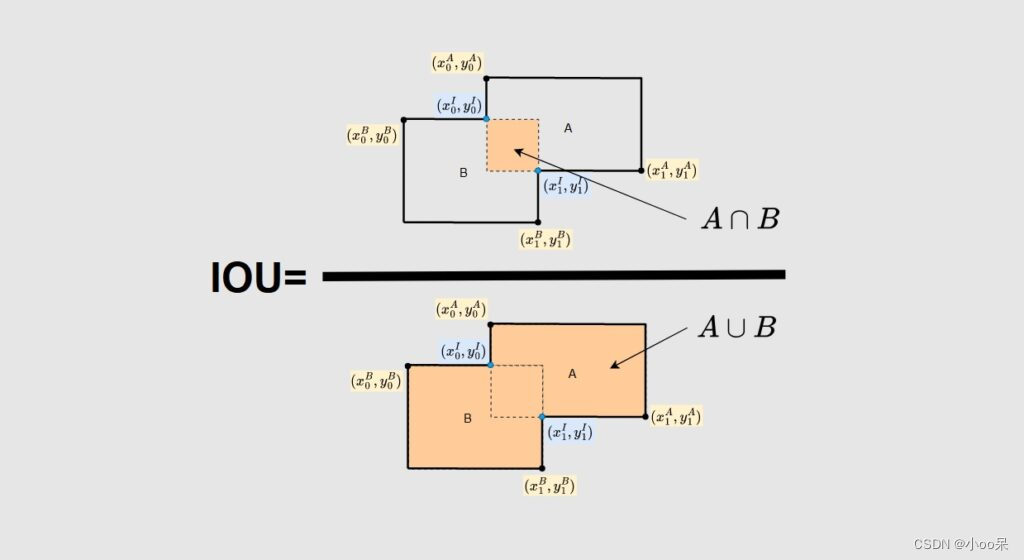
IoU的值范围从0到1,值越接近1表示两个框的重叠程度越高,通常在目标检测中,如果IoU超过某个阈值(如0.5),则认为是有效检测,否则视为误检或漏检。在训练目标检测模型时,IoU也是优化目标函数中的一个重要参数,用来调整预测框与真实框之间的匹配精度。
(4)什么是锚框(Anchor)
在计算机视觉特别是目标检测领域,Anchor(也称为锚框、参考框、先验框或者默认框)是一个核心概念,主要用于帮助模型定位图像中的目标物体。Anchor是一种事先定义好的、具有固定大小和纵横比的矩形框,它们被均匀地铺设在整个图像或者特征图上,用作目标可能存在的预设位置和尺度的猜测。
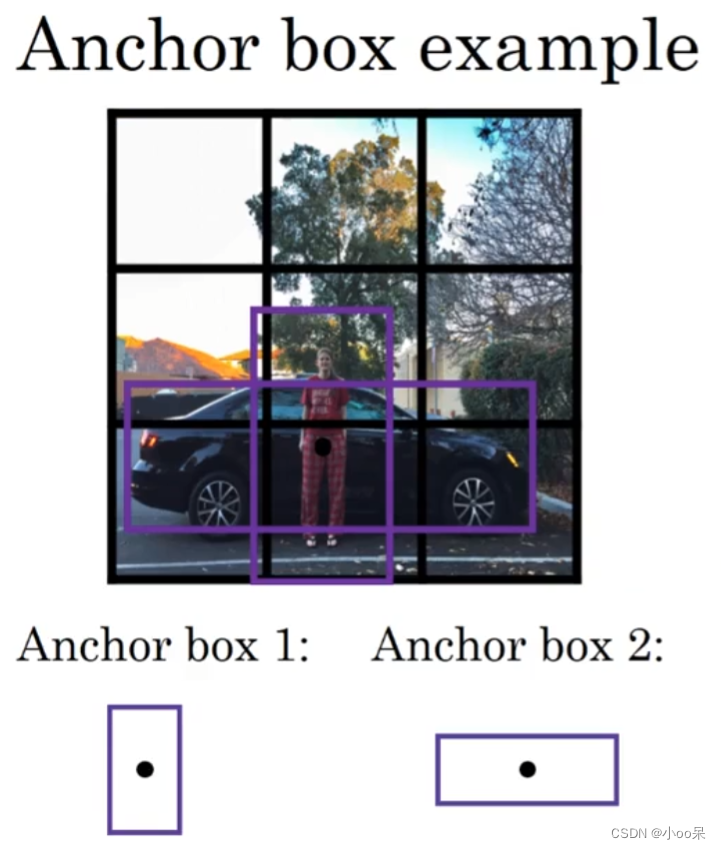
Anchor的作用包括:
-
尺度和比例覆盖:由于目标物体可能出现在图像的不同位置且尺寸各异,通过设计多个不同大小和长宽比的Anchor,可以覆盖各种尺度和形状的目标,提高检测的全面性。
-
检测基础:在两阶段方法中,Anchor用于生成候选区域(Region Proposals),之后再对这些区域进行分类和边界框精修。在一阶段方法中,Anchor直接参与预测,模型学习到的是每个Anchor是否包含目标以及如何调整Anchor来精确匹配目标的位置和尺寸。
-
学习偏移量:模型不是直接预测目标的绝对位置和尺寸,而是预测相对于Anchor的偏移量以及Anchor内目标的类别概率,这样可以减少搜索空间并简化学习任务。
-
优化与筛选:在训练过程中,通过与真实标注框进行比较,模型会学习到哪些Anchor是有效的(即与真实目标有足够重叠的IOU,Intersection over Union),并调整这些Anchor来提高检测精度。无效的Anchor可以通过非极大值抑制(NMS)等策略去除,以减少计算负担和提高效率。
二、目标检测的基本思路
(1)基本思路
目标检测技术的核心思想可以概括为同时解决“定位”(Localization)与“识别”(Recognition)这两个基本任务。
-
定位(Localization): 定位是指在图像中找到一个或多个特定目标存在的位置。这通常通过在图像上划定一个边界框(Bounding Box)来实现,该边界框精确地包围目标物体,从而明确了物体的空间范围。定位不仅要求框出目标,还期望这个框尽可能紧贴目标边缘,减少多余的背景信息,提高检测精度。
-
识别(Recognition): 识别则是指确定边界框内目标物体的类别。这是个分类问题,目标是将框定的物体映射到预定义的一组类别中去,比如人、车、猫等。这一过程通常涉及深度学习模型,如卷积神经网络(CNNs),它们能够从图像特征中学习并区分不同类别的物体。
(2)关键步骤
结合这两步,目标检测系统不仅告诉你图像中有哪些感兴趣的物体,还能精确指出它们在哪里。这一过程往往包括以下几个关键步骤:
- 特征提取:利用深度学习模型从图像中提取有助于识别和定位的特征。
- 候选区域生成:生成可能包含目标物体的区域提议,减少搜索空间。
- 分类与回归:对候选区域进行类别判断,并微调边界框位置使其更准确地匹配目标物体。
- 非极大值抑制(Non-Maximum Suppression, NMS):去除重叠的边界框,确保每个目标只被检测一次。
三、目标检测的常见算法
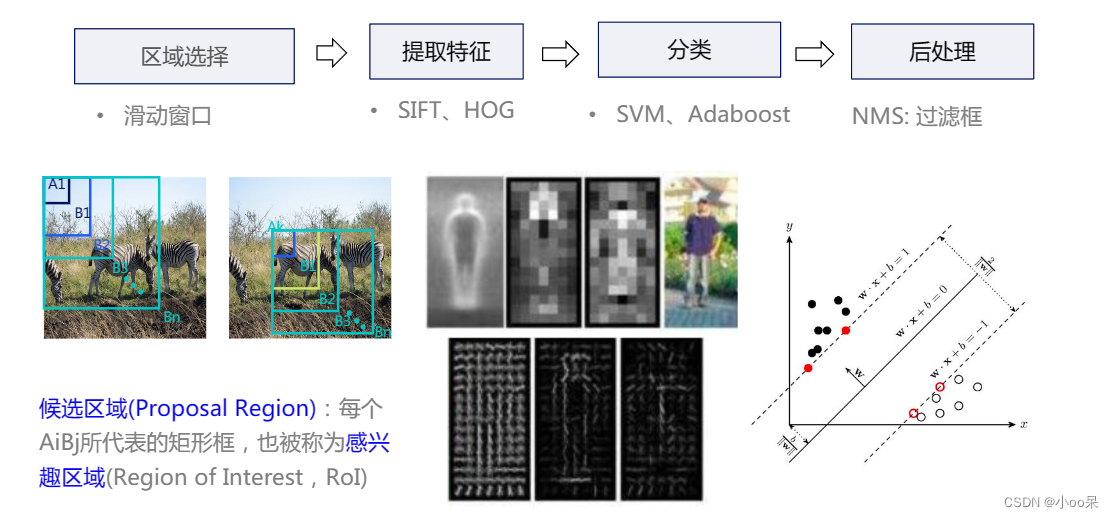
(1)传统目标检测算法
传统的目标检测框架,主要包括三个步骤:
① 利用滑动窗口框定候选区域
- 使用不同尺寸的滑动窗口:在传统目标检测算法中,首先会使用不同尺寸的滑动窗口在图像上滑动,以框住图像中的部分区域作为目标检测的候选区域。这就像你在寻宝游戏中,用放大镜扫过藏宝图,希望抓住可能隐藏宝藏的线索。
- 滑动窗口的问题:现实中,一张图像中的目标物体可能因远近不同而呈现多种尺寸。为了能检测到不同大小的目标,我们不得不采用多个尺度的滑动窗口去遍历整个图像。但这样会导致计算量巨大,因为需要对每个窗口进行特征提取和分类。这就好比穷举了藏宝图上所有可能的位置,效率并不高。
② 提取候选区域视觉特征
- 常用特征描述子:得到候选区域后,我们需要提取这些区域的特征。在传统目标检测算法中,常用的特征描述子包括Harr特征(常用于人脸检测)和HOG特征(广泛用于行人和其他目标检测)。这些特征描述子能够有效表示图像中的特定属性,比如边缘、纹理等信息,帮助算法识别目标。
- 特征提取的局限性:虽然手工设计的特征描述子在某些任务中表现不错,但它们的泛化能力有限,对于多样性变化大的数据集,性能就会下降。这就像不同类型的锁需要不同的钥匙,一种特征描述子并不能适用于所有情况。
③ 利用分类器进行识别
- SVM等分类器:提取了特征之后,我们会用分类器对这些特征进行识别。在传统目标检测算法中,支持向量机(SVM)是一个非常流行的选择。SVM试图在多维空间中找到最优的决策边界,将不同类别的目标分开。
- 多分类问题:在目标检测中,不仅要判断候选区域是背景还是某个特定的目标,还可能要识别多个目标类别。这就需要训练多个二分类器,或者使用多类SVM进行分类。如同你不仅需要区分哪些是石头,哪些是宝石,还需要进一步鉴定宝石的种类。
(2)基于深度学习算法的目标检测

现代深度学习目标检测技术可以根据其处理流程大致分为"两阶段"和"一阶段"两大类
① 两阶段目标检测算法(如 Faster R-CNN, Mask R-CNN)
特点:
- 分步处理:首先生成一系列潜在的目标候选区域(Region Proposals),然后对这些候选区域进行进一步的分类和定位精炼。
- 高精度:由于候选区域的生成和后续的精细处理分离,这类方法往往能够达到更高的检测精度,特别是在小目标和重叠目标的检测上表现更优。
- 计算成本:相较于一阶段方法,两阶段方法通常计算量更大,尤其是在生成候选区域这一步骤上,虽然Faster R-CNN通过引入RPN降低了这一成本。
- 适用场景:适合对精度要求较高的应用,如医疗影像分析、自动驾驶等。
① 一阶段目标检测算法(如 YOLO, SSD)
特点:
- 快速响应:将目标检测视为一个单一的回归问题,直接在输入图像上预测边界框和类别,无需生成候选区域,因此速度非常快。
- 实时性:由于其简洁的流程,一阶段方法特别适合需要实时处理的场景,如视频监控、无人机导航等。
- 精度与效率权衡:虽然近年来一阶段方法的精度有了显著提升,但通常在极端情况下的精度(如非常小或重叠的对象)上还是不如两阶段方法。
- 模型结构:一阶段模型通常更为简洁,易于训练和部署,但可能需要更多的技巧来解决正负样本不平衡等问题,如RetinaNet中的focal loss。
| 两阶段(2-stage) | 一阶段(1-stage) | ||
| R-CNN | R-CNN是最早将深度学习应用于目标检测的算法之一。它通过选择性搜索算法提取候选框,然后利用CNN提取特征,最后通过SVM进行分类和边框回归。虽然R-CNN开创了使用深度学习进行目标检测的先河,但其处理过程分多个步骤,无法端到端训练,且速度较慢 | SSD | SSD算法直接在特征图上预测类别和边框,不需要候选框提取步骤。它使用不同尺度的特征图来检测不同大小的物体,从而实现对各种尺寸物体的有效检测。SSD算法结构简单,速度快,适合实时应用 |
| Fast R-CNN | Fast R-CNN对R-CNN进行了优化,它先对整个图像进行一次CNN特征提取,然后在提取的特征图上选取候选框,再进行分类和边框回归。这个过程实现了特征提取的共享,大大提高了计算效率,同时也实现了端到端的训练 | YOLO系列 | YOLO(You Only Look Once)算法将目标检测任务转化为一个回归问题,直接在图像上预测边界框和类别概率。从YOLOv1到最新的YOLOv5,YOLO算法在保持高速检测的同时,通过各种技术改进,不断提升检测精度 |
| Faster R-CNN | Faster R-CNN在Fast R-CNN的基础上进一步改进,它引入了一个区域提议网络(Region Proposal Network, RPN),直接在特征图上生成候选框,省去了使用选择性搜索算法的时间,使目标检测的速度和准确性都得到了提升 | ||















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









