









论文
Muhammad Ghifary, David Balduzzi, W. Bastiaan Kleijn, and Mengjie Zhang. 2017. Scatter component analysis: A unified framework for domain adaptation and domain generalization. IEEE Trans. Pattern Anal. Mach. Intell. 39, 7 (2017), 1414–1430.
论文解读
本文是效果比较好一篇基于传统机器学习的域适应方法,发表在2017年TPAMI上。关于迁移学习以及域适应的一些基础概念,此处不在进行介绍。
论文中一些概念
Note:定义一个核函数k就相当于定义了一个可再生核希尔伯特空间H。
Domain:由输入空间X和标签空间Y共同构成的概率分布P。
Mean map:输入空间上的分布映射到可再生核希尔伯特空间中的点。
在输入空间X中引入核函数,H是对应的非线性映射Φ得到的可再生核希尔伯特空间,mean map能够将X中的分布映射到H中的点。几何上讲,mean map 是分布P的图像经过映射Φ后的质心(理解为分布P经过映射后的均值?)进一步的,scatter定义为分布图形中围绕其质心的点的方差。其中,通过mean map 得到的结果表示为:
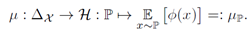
Scatter:原始输入空间X中的分布P经过非线性映射Φ后的scatter的定义为:
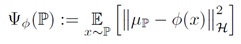
需要说明的是,一个domain的scatter是不能通过计算直接得到的(因为这个非线性映射Φ是不知道的?),而是通过观察得到,原始输入空间X一个的一个有限的样本及{x1,x2,…,xn}对应的scatter需要通过经验分布计算得到,这个经验分布计算公式为:
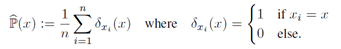
论文进一步证明:随着输入空间X中样本数目的增加,估计得到的scatter会与它的真实值越来越接近。(scatter bound理论)
Total variance 作为scatter,计算公式:
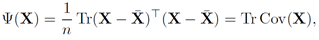
其中:
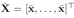
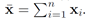
Scatter component analysis (SCA)
首先介绍四种scatter:
Total scatter:
定义:
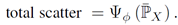
计算公式:
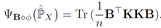
Domain scatter:
条件:
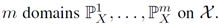
并且
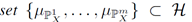
定义:

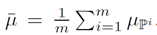
计算公式:
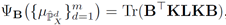
L是系数矩阵,

类似于TCA中的系数矩阵进行理解,因为使用了核技巧,所以需要额外构造这个系数矩阵。
Class scatter:
Between-class scatter:
定义:
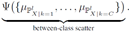
计算公式:
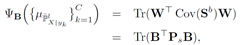
其中,
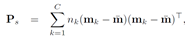

Within-class scatter:
定义:
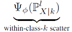
计算公式:

其中,
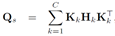
H是中心矩阵,与TCA中的相同。
下面介绍算法,SCA的目标是通过解决一个最优化问题找到(学习到)一个比较好的特征表示,这个最优化问题的形式为:

将前面定义的几个scatter代入上式可以得到:
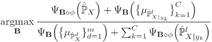
目标函数(引入约束条件
W
T
W
=
B
T
K
B
W^TW=B^TKB
WTW=BTKB ):

参数β、δ>0用于控制scatter。最终的目标就是通过解决这个最优化问题找到投影矩阵B,
目标函数:
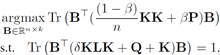
拉格朗日对偶形式:
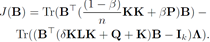
对B求偏导数使为0可得到一般化特征问题:
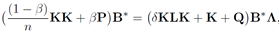
这个最优解交给python或者matlab都可以很容易解决,得到主导特征值构成的对角矩阵:
Λ
=
d
i
a
g
(
λ
1
,
.
.
.
,
λ
k
)
\Lambda =diag(\lambda_1,...,\lambda_k)
Λ=diag(λ1,...,λk) 以及主导特征向量构成的映射矩阵B:
B
=
[
b
1
,
b
2
,
.
.
.
,
b
k
]
B=[b_1,b_2,...,b_k]
B=[b1,b2,...,bk].
SCA伪代码

总结
SCA提出了一种比较新颖的特征表示方法,论文最核心的地方是对scatter的理解,简单解释,scatter就是在MMD的基础上改进后得到的可以用来表示domain以及between-class、within-class的差异的度量方式,SCA的最终的目标函数就是要最大化整体差异、类间差异,最小化域之间的差异以及类内的差异,这些差异的计算都是在可再生核希尔伯特空间中进行的。从论文给出的结果来看,SCA的性能要优于TCA,问题在于论文并没有给出与JDA的结果进行比较,与JDA论文中的实验结果进行比较来看,SCA的整体效果还是要稍微弱于JDA,应该是SCA论文中没有给出相应对比的原因,不过SCA中的思想,也就是那个最优化的目标函数还是很值得借鉴的,是一个很好的思路。
补充
Scatter Components Analysis 中scatter是作为动词解释,如果作为名词会更容易理解,在进行domain adaptation时,我们一般都要想办法保留数据的特征,也就是variance,不过在一些论文中是直接将这个variance写成scatter matrix,也就是原始数据的散矩阵,这样SCA论文中的方法就很好理解了,其最终的目标就是要最小化源域和目标域的divergence,同时最大化类间散度,最小化类内散度,这个想法其实比较常规的,最大化类间距离,最小化类内距离,然后使数据可分性更好,准确率也更高。














 720
720











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









