









最近,使用curve_fit时遇到一个问题,百思不得其解,看了官网,上网查都没有找到这种问题所在,最后通过一些实验确定:应该是由于我这个问题中的数值存在较小值,如果在function中使用了除法会导致数值计算的问题,所以不正确。 接下来具体描述下我遇到的问题,和得出我这种猜测的支撑依据。
1.问题描述
在做交通流三参数模型拟合时,我使用了scipy的curve_fit函数。数据大概是这个样子的:
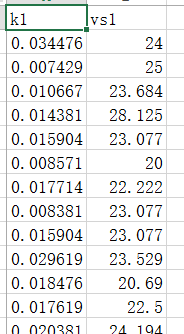
然后我使用下面的代码:

拟合出的曲线是这样的:

但是如果我将代码改成这样:

拟合结果就变成了:

我用spss做了验证,拟合出来的结果是完全一致的。所以说可以确定问题就是出在我定义的function里面,一个是定义成
v
s
=
v
f
∗
(
1
−
k
/
k
j
)
v_s=v_f*(1-k/k_j)
vs=vf∗(1−k/kj),另一个是定义成
v
s
=
a
∗
k
+
b
v_s=a*k+b
vs=a∗k+b,我们可以知道这两个式子是完全等效的,但是拟合结果是天差地别,让人费解,接下来我就来简单探究下问题。
2.简单实验
2.1排除公式因素
首先,我猜测会不会是因为除法所带来的呢,因为两个式子中唯一的区别就是一个式子带有除法另一个没有除法。我做了如下的实验,代码为:


可以发现确实不是除法所带来的,这边用了和上述失败的公式一模一样的公式,可是却拟合成功了。
2.2数值计算问题
于是进一步猜测应该是由于数值计算的原因所带来的。在我这个例子中k都是很小的数值,基本在0.01左右,甚至更小,而vs一般大于20。因此猜测引入除法会带来数值计算上的bug。于是用下述代码进行实验。


果然拟合失败了。
然后做一个对照实验,来确认问题原因。
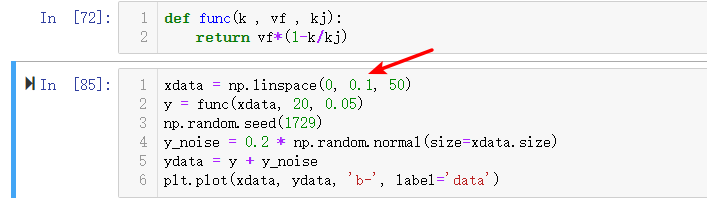

只需稍微将k(自变量)的值变大一些就可以拟合成功了,所以应该就是由于数值计算问题所带来的。
3.总结建议
所以说,总的来说curve_fit中的函数定义应该是没有限制的,但是建议是使用乘法,少用除法,因为除法更容易出现问题,如舍入误差、数值计算等,除法都有可能在有极小值时出现bug。若出现拟合问题,可以考虑下是不是由于数据里存在很小或很大的值所带来的。















 601
601











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









