







作者及发刊详情
J. Xia, C. Cheng, X. Zhou, Y. Hu and P. Chun, “Kunpeng 920: The First 7-nm Chiplet-Based 64-Core ARM SoC for Cloud Services,” in IEEE Micro, vol. 41, no. 5, pp. 67-75, 1 Sept.-Oct. 2021, doi: 10.1109/MM.2021.3085578.
摘要
鲲鹏920是海思基于ARM架构设计的第二代服务器处理器。利用大量的chiplets以及hybrid工艺技术,鲲鹏920在处理不同负载的同时获取截稿的成效。通过这些灵活的chiplet的重组可以构建新的设计。鲲鹏系列处理器混合各类技术来提升效率,消除瓶颈,提升价值和性能。其关键特征如下:
支持向量扩展的超标量架构为高性能应用场景赋能;
通过一致性cache子系统将多核基于超低延迟、非阻塞、bufferless的ring设计集成进单chiplet中;
为2D封装的die间互连设计了一个专用的并行small-IO block,以此获得高带宽;
重新设计了IO die,使用新的标准接口(例如PCIe4.0)扩展SoC;
通过cache一致性NUMA架构使得两个或四个鲲鹏920可以作为单个系统级多处理器协同工作。
正文
鲲鹏920的设计目标
对于细分市场的强可扩展性
高能效和高性能
die的可复用性
鲲鹏920面向的工作负载场景特征
处理大数据场景需要强大的算力
HBase/Redis工作负载下的单线程的IPC通常小于1
DDR访问的延迟将导致计算效率的降低
分布式的存储需要低延迟的多线程IO交互
边缘端的工作负载迁移到云端导致云端架构具备了边缘端架构的特征
具体包括横向扩展的能力、虚拟机特征、QoS的部署。
更多计算密集型工作负载由特定领域加速器处理
访存密集型工作负载对服务器变的更加重要,而这种工作负载需要低访存延迟。
根据面向的应用场景定义鲲鹏920的设计原则
一个能有效处理单线程任务的高性能CPU核
消除长尾效应
大规模芯片中能够处理多级cache一致性挑战的cache一致性机制
设计一个无死锁、bufferless、多ring环路的片上网络
应用于云服务场景:低延迟、高带宽、QoS兼容
为实现die间通信,开发一个合适的一致性并行互连机制
通过CoWoS封装技术,一致性die间通信能达到低于15ns的延迟和约400GB/s的高吞吐率。
支持PCIe4.0的低成本、高性能的IO die
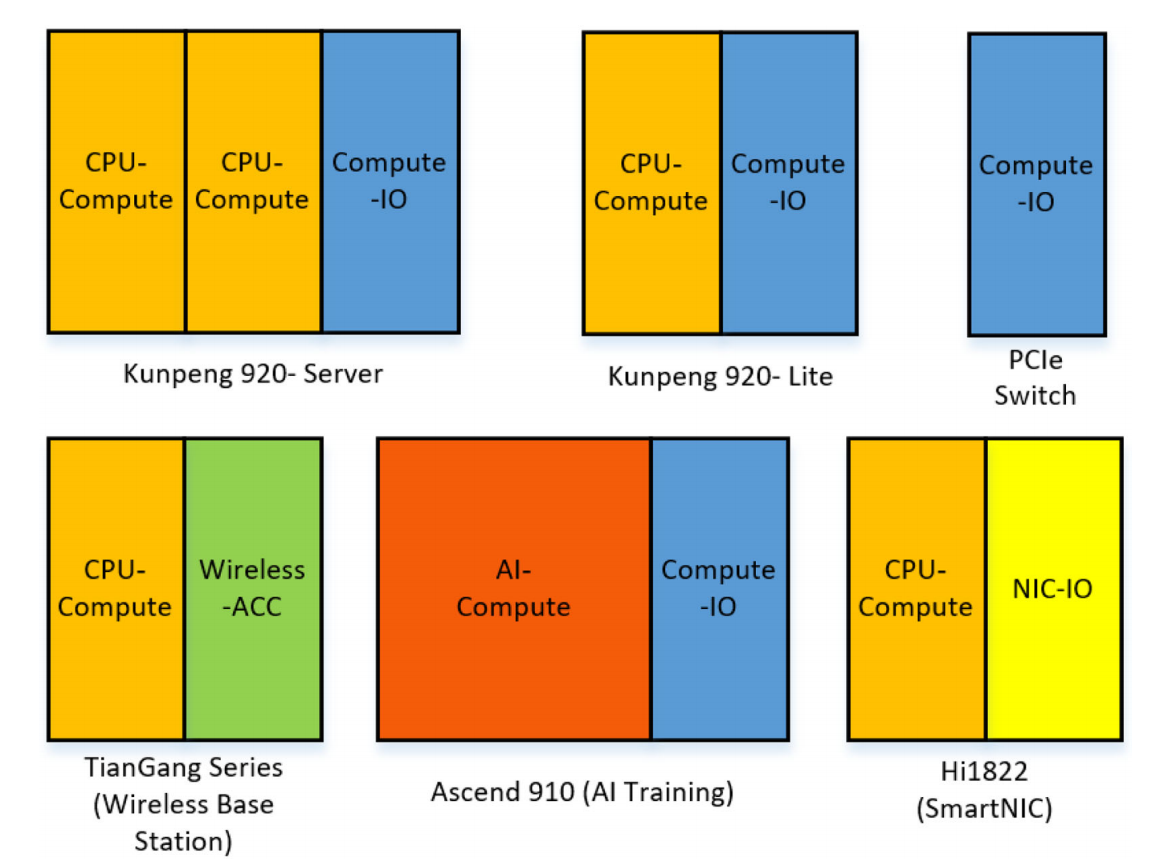
鲲鹏920:“乐高”式的chiplet架构
海思选择不同工艺、类型的die通过die组装技术和高带宽的一致性互连技术构建不同应用场景的产品。
五种主要的chiplet
CPU计算die、AI计算die、计算IO die、NIC-IO die以及无线加速die。
计算IO die可以用作PCIe Switch。
高性能的硅中介层
通过TSMC CoWoS 65nm的BEOL技术,die间带宽能达到400 GB/s,比基于MCM互连的AMD Zen2更高。
通过高速的die间互连,鲲鹏920在UMA场景下可以获得NUMA相近的性能。
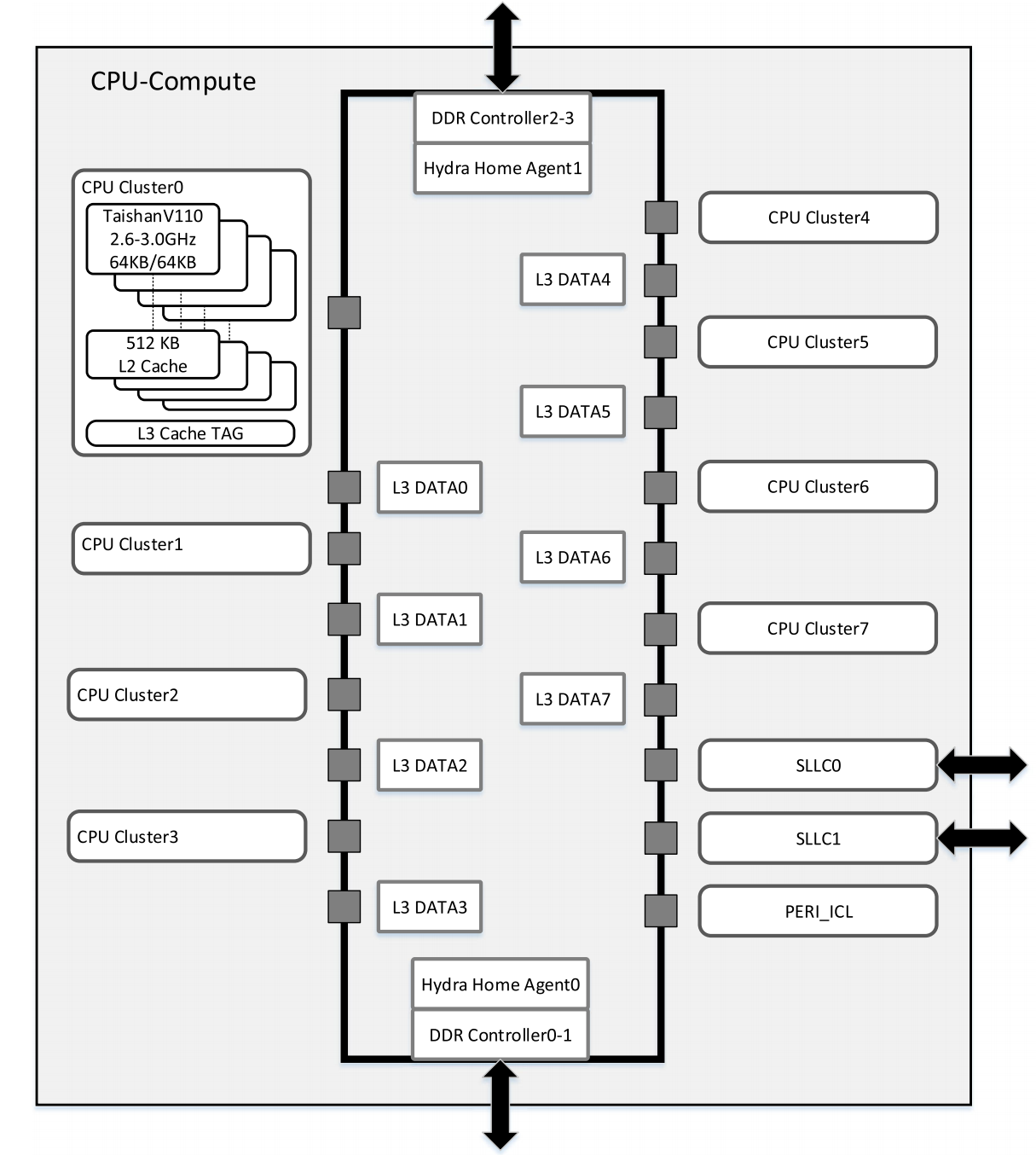
CPU-Compute die的设计架构
每个CPU-compute die将CPU cluster、DDR控制器、L3 cache等部件通过ring总线连接
- 8个CPU集群(cluster)
- 每个CPU集群有4个Taishan V110核,整个die共32个core
- 单CPU cluster共享LLC TAG,LLC DATA则挂载在NoC网络中与该cluster最近的L3 DATA
- 四路DDR控制器相对摆放
- 双HHA(Hydra Home Agent)用于die内的一致性管理
- GIC用于中断管理
- 双SLLC(super cluster link layer)用于cache一致性的die间通信
- Peri_ICL用于系统功能管理
泰山V110 core:高性能的标量/向量计算、高效的load/store操作
- 超标量流水线
- SIMD扩展
- 高效的load/store和cache
- 较高的PPA
- 私有的L1和L2 cache
LLC:采用高效的内存一致性策略
NoC:采用bufferless的双ring架构
bufferless相比bufferable面积更小、设计更简单、频率更高
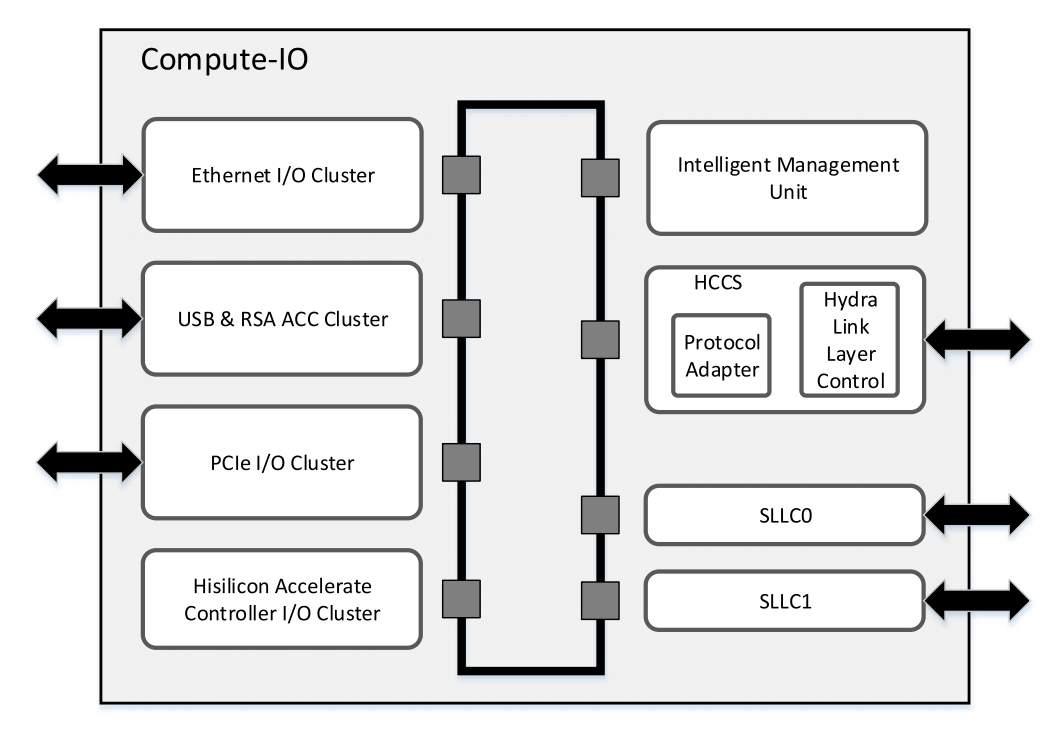
Compute-IO die的设计架构
Compute-IO die用于实现IO功能,也可以用于昇腾910,也可以用作PCIe switch。主要面向高吞吐量,以及长距离通信、存储访问、交互性任务加速。
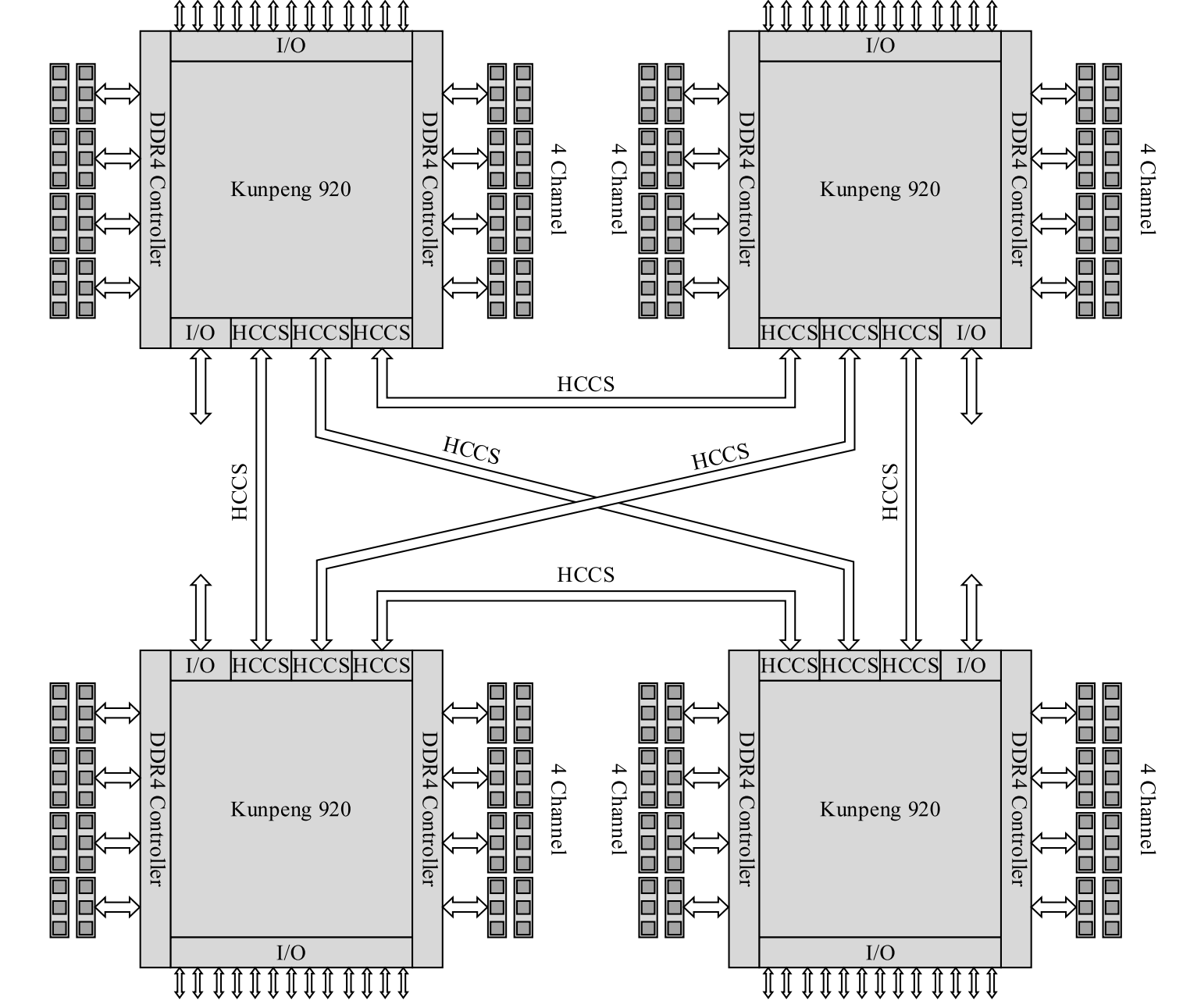
HCCS:片间一致性协议为云计算工作负载的扩展提供了很好支持
芯片与芯片间的总线,非die-to-die
D2D和C2C的多级互连架构
SLLC用于处理D2D通信的一致性
物理层:为先进封装定制化
为CoWoS而设计并兼容MCM,定制化small IO
链路层:使用virtual channel确保了die间通信的有效性
基于credit的流量控制确保了发送器和接收器间的有效交互
低延迟和高性能
HCCS实现鲲鹏920多芯片的两两互连
物理层:提供有效驱动的定制化PHY
协议层:为解决长距离传输导致的load/store延迟增加优化了一致性协议的多次请求迭代
参考文献
[11] C. Fallin, C. Craik, and O. Mutlu, “Chipper: A lowcomplexity bufferless deflection router,” in Proc.IEEE 17th Int. Symp. High Perform. Comput. Architecture, 2011, pp. 144–155, doi: 10.1109/HPCA.2011.5749724.
评
本文由鲲鹏920架构师团队介绍了设计目标、设计架构。虽然介绍了海思乐高式的chiplet产品设计策略,但对于笔者关心的鲲鹏920的die间通信协议仅寥寥几句,实在索然无味。


















 2024
2024

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











