









 本文探讨了chiplet系统设计的关键要素,包括封装-设计协同、性能损失、异构处理器的挑战、互联设计中的带宽/延迟问题,以及封装方案的选择。作者还深入剖析了系统架构分类(如封装集成与SoC分解),并讨论了死锁管理和互联拓扑优化策略,为chiplet架构设计提供了全面的视角。
本文探讨了chiplet系统设计的关键要素,包括封装-设计协同、性能损失、异构处理器的挑战、互联设计中的带宽/延迟问题,以及封装方案的选择。作者还深入剖析了系统架构分类(如封装集成与SoC分解),并讨论了死锁管理和互联拓扑优化策略,为chiplet架构设计提供了全面的视角。
作者
Liu Yafei1, Li Xiangyu2, YIN ShouYi1, Review of chiplet-based design: system architecture and interconnection, SCIENCE CHINA Information Sciences, 2024, ISSN 1674-733X, https://doi.org/10.1007/s11432-023-3926-8.
1School of Integrated Circuit, Tsinghua University, Beijing 100084, China;
2Laboratory of Integrated Circuits and Intelligence Systems, Research Institute of Tsinghua University in Shenzhen,
Shenzhen, 518057, China
摘要
正文
业界尚未提出通用的和清晰的系统级架构设计方法。
设计挑战
封装-设计的协同优化对获取chiplet系统良好的PPAC很关键。
系统架构的挑战
选择合适的chiplet划分方案,以减少由于划分导致的潜在的性能损失,这种性能损失包括带宽和延迟。
除了普遍要考虑的访存瓶颈和掩模版限制,同构的多核处理器主要关心可扩展性和非一致性访问延迟,而后者正是异构多处理机SoC(MPSoC)主要关心的与计算效率相关的东西;
额外的成本考虑,包括接口电路的硅面积、额外的封装成本、额外的掩膜成本、以及接口电路的功耗。
chiplets的可复用性也影响了整体系统的成本。
互连网络的损失
带宽/延迟的损失和碎片化的片上网络导致互联设计的困难
由于物理限制,inter-chiplet相比intra-chiplet有更低的带宽和更高的延迟
chiplet方法使设计更加碎片化,而各个部分独立设计和验证导致额外的“通信跳跃”和传输的不确定性,比如死锁问题。
封装方案决定了D2D接口的带宽和链路上的延迟,封装成本也在考虑之内
系统架构分类
系统架构可以分成两个类别,封装集成和SoC分解。
封装集成是将板级设计的集成映射到封装种,比如处理器和存储的集成,不同架构处理器的集成。
SoC分解是将大芯片的SoC分成多个chiplet。
封装集成
包括处理器和存储的集成,CPU和GPU等异构处理器的集成。
为了解决日益增长的处理器内存带宽需求,使用嵌入式存储或者封装集成存储,比如Intel Haswell 处理器将eDRAM和CPU通过on-package-IO集成在一个封装种;AMD在RadeonTM Fury芯片中通过silicon interposer技术将GPU和high bandwidth memory(HBM)堆叠在一起。
异构处理器在同一封装中集成提升系统性能。例如Intel的Kaby Lake-G处理器在同一封装中通过PCIe接口集成了AMD的显卡,性能相比板级连接提升了40%,并节省了50%的板级空间。此外,网卡设备、DPU等也受益于封装集成技术的高带宽接口。
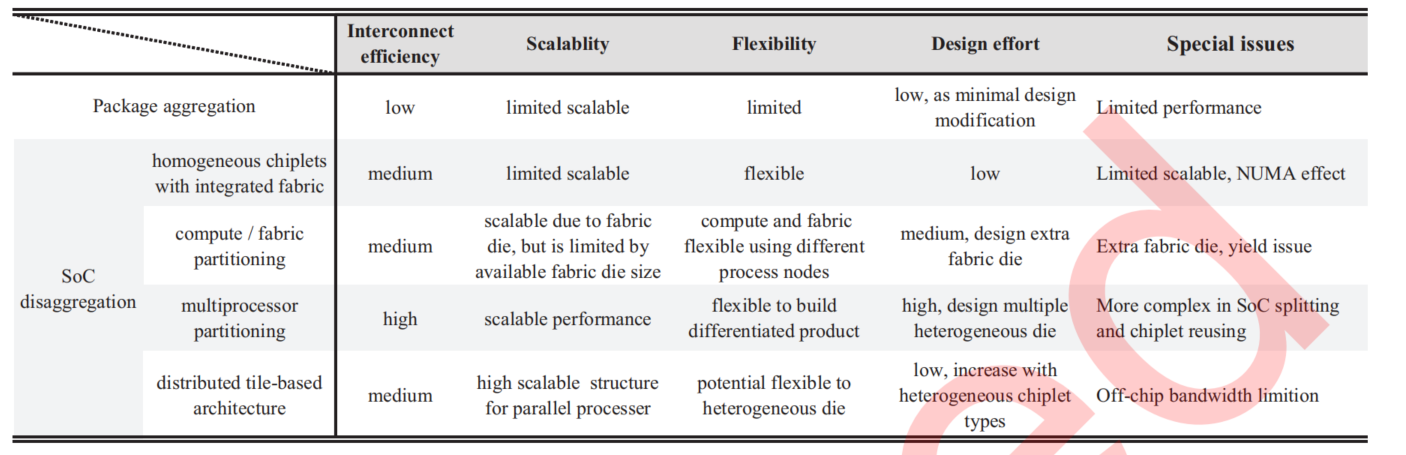
通过同构chiplets连接拓扑的SoC分解
通过计算/架构划分的SoC分解
通过一个架构die,即通常所说的IO die,作为系统的互联中心,连接计算和存储chiplets。
中心化的互联促进了chiplet间通信延迟的一致性,减少了NUMA影响;fabric die和计算die可以使用不同的工艺节点,减少了系统成本。同时由于路由逻辑转移到fabric die中,简化了计算die的设计难度;fabric die也简化了封装设计难度。
通过多处理器划分的SoC分解
将MPSoC基于功能单元分解为多个异构处理器。
例如志强可扩展平台“Granite Rapids”,使用计算性能核(P-core)+ IO chiplet的架构,性能核可以达到8个。
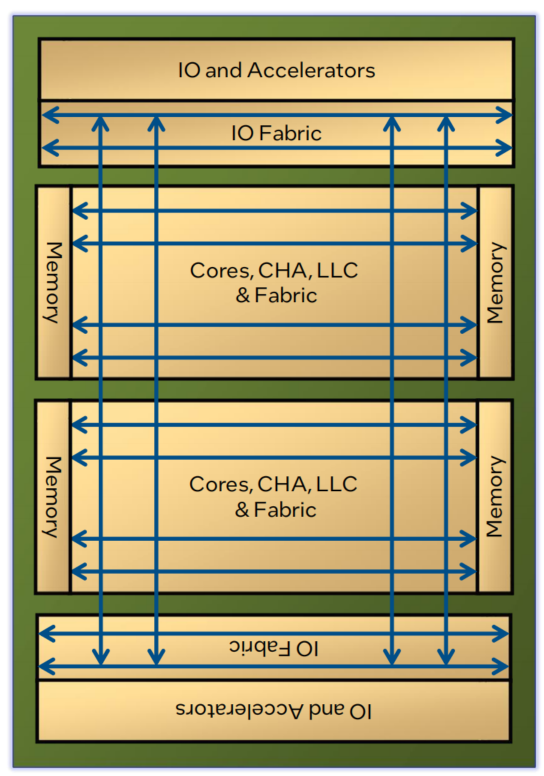
基于tile分布架构
Nvidia SIMBA深度神经网络加速器
特殊的chiplets系统设计
cache chiplets技术促进了内存设计的进化
Intel的Ponte Vecchio处理器的RAMBO作为额外的三级cache节点。
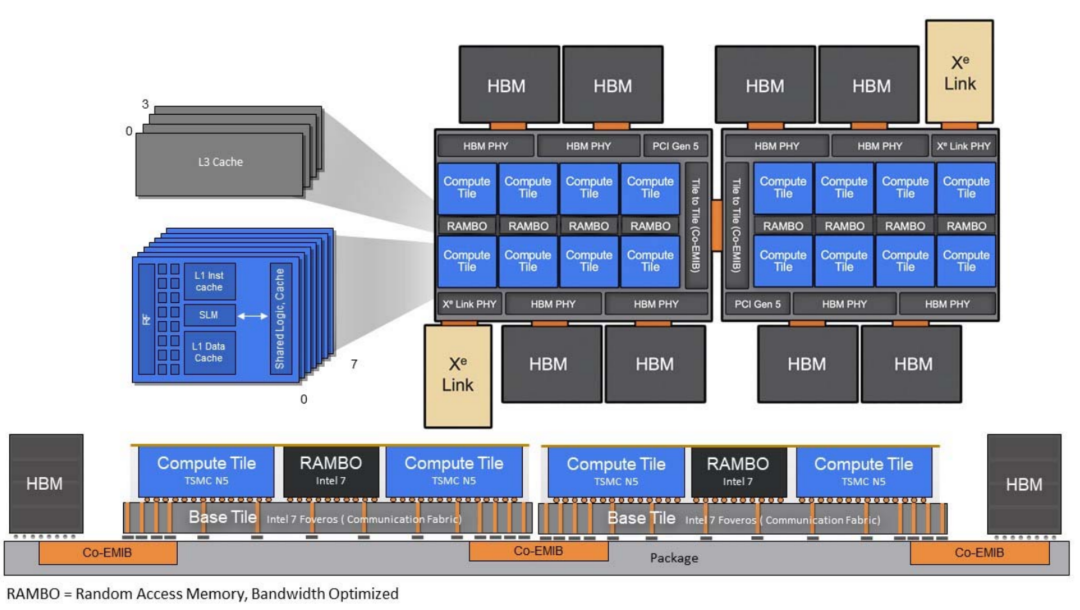 AMD的3D V-cache技术可以灵活的扩展cache的容量。
AMD的3D V-cache技术可以灵活的扩展cache的容量。
封装平台和可复用的基板降低了开发成本,减少了开发时间
自动化设计工具辅助设计空间探索和架构仿真
互联拓扑
ring互联设计简单,序属性简化了cache一致性的实现
AMD Zen2
更高半径、可扩展的mesh互联可解决大量chiplets互联的问题
Nvidia SIMBA深度神经网络加速器
SIAM in-memory-compute计算架构
互联拓扑的优化
silicon interposer相比传统的MCM方案可获得更高的带宽和更低的功耗
active相比passive interposer可以有更好的性能和链路长度
有源中阶层需要更大的面积,但通常导致更低的良率。
自定义的拓扑结构相比标准的拓扑有更好的能效和性能
无死锁路由
虽然单独的die被设计的无死锁,但当不同的die互联后,新的死锁会产生。
根据路由实现的特征,有两种路由策略:分布式和集中式。
中心化路由通过控制网络获取网络中每个节点的工作状态,软件根据路由信息灵活的自适应路由
software-defined NoC(SDNoC),控制网络和数据网络分离。
参考文献
评
本文主要介绍了当前主要chiplet系统的分解方案及其优劣,对异构chiplets系统的互连拓扑做了详细分析,介绍了chiplets间的死锁原因和解锁策略,同时对不同chiplets系统的封装方案也做了辅助介绍,也特别强调了架构-封装设计的协同。整体来说,是一篇对chiplets架构设计做了全面论述的好文章。
网络直径diameter:top中任意两点之间最短路径集合的最大值
跳数hop count:一个路由节点到下一个路由节点称为一跳


















 2752
2752

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











