







作者及发刊详情
Li B , Pandey S , Fang H ,et al.FTRANS: energy-efficient acceleration of transformers using FPGA[J].ACM, 2020.DOI:10.1145/3370748.3406567.
摘要
正文
主要工作贡献
与CPU和GPU在执行Transformer和RoBERTa相比,提出的FTRANS框架获得了极低的成本和能耗。
先进的transformer架构的块循环矩阵压缩方法(block-circulant matrix, BCM)
处理了传统BCM压缩导致的精度损失,提出了先进的BCM压缩方法来减少transformer的权重
FPGA平台上transform的整体优化
在模型压缩的前提下,提出了一个两级优化方法,调度计算资源,优化延迟和吞吐率
降低硬件资源和能耗
提出了一个FPGA架构设计来支持模型压缩技术,开发了设计自动化和优化技术。
实验评估
实验验证平台:VCU118
选用模型: shallow Transformer和RoBERTa (base configuration)
- shallow Transformer
架构包括encoder和decoder。
使用WikiText-2数据集1任务进行评估,这是一个无监督的序列到序列的问题,需要解码器部分。 - RoBERTa
基本配置,预训练的Transformer架构,只有encoder
使用情绪分类任务划分,是一种监督学习,无需decoder
如图是两种模型的关键参数:

工具:Xilinx SDX2017.1
优化前后精度对比
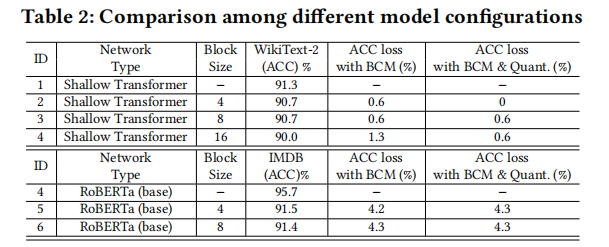
PPA表现
- 减小了16倍的NLP模型的大小
不同模型下资源占用、功耗、吞吐
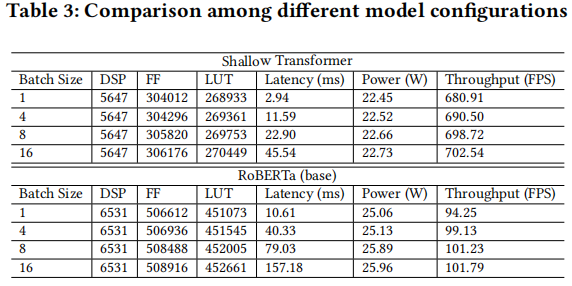
不同平台的对比
将同一剪枝后模型、同一benchmark(IMDB)部署在四个设备上,
相比CPU(i7-8700K),FPGA设计获得了27.07倍的性能提升和81倍的能效提升
相比GPU(RTX5000,Pascal-family,8GB memory),GPU设计的功耗是FPGA设计的5.01倍,而FPGA在能效方面有8.8倍的提升
相比嵌入式GPU(Jason TX2),获得了24倍的能效提升
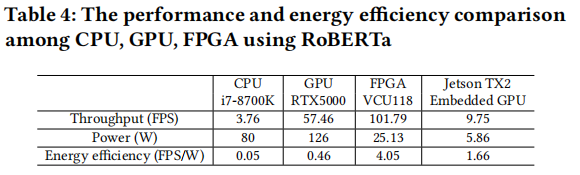
软件优化
FPGA架构设计
主要思想
Transformer的参数超过了FPGA的BRAM容量(在模型压缩后的前提下),因此将模型划分为embedding层和encoder/decoder栈。
浅层神经网络(shallow network)可以直接在FPGA上实现,但是先进的设计比如BERT和RoBERTa中有很多decoder/encoder,此时FPGA中DSP资源是不够的,这种情况下有必要进行PE的复用
将embedding层卸载到片外
embedding层占据了30.89%的参数,本质上是一个将离散的token转换成连续空间的查找表,计算相对encoder/decoder栈较小,因此可以卸载embedding层到片外存储中,从而将计算最密集的权重部署在片上ram中
开发新模块缓解IO约束
本文开发了层间粗粒度流水线、层内细粒度流水线和计算调度。
FPGA架构组成
FPGA设计包含了Encoder/Decoder计算单元、片上存储bank、transformer控制器以及片外存储(DDR)。

Transformer控制器
Transformer控制器控制来自PCIe、BRAM和计算单元的输入的计算流和数据流
Encoder/Decoder计算单元
encoder和decoder有共同的操作,因此可以将其分成不同的计算原语,包括不同大小的矩阵乘,向量指数运算等,Transformer控制器可以通过将multi-head attention, linear, 和add/norm 模块组合构成encoder和decoder模块。
Multi-Head Attention单元
该鄙见包含了多个PE (Processing elements,来实现矩阵乘) bank、多个buffer、一个归一化模块、一个掩码功能模块和一个softmax模块。
输入数据从DDR输入进encoder流水线中,然后与BRAM中的Q、K相乘,中间数据结果传递到buffer中;接着执行归一化操作、softmax、后续的矩阵层操作。
每个head都已一个控制器来控制计算流和数据流,同时支持mask操作

PE设计和softmax计算单元
本文开发了三种不同的可配置PE:PE-A, PE-B,和 PE-FFT/IFFT.
对于BCM矩阵乘,采用PE-FFT/IFFT,其余采用PE-A, PE-B进行矩阵乘。
PE-A, PE-B包含2个累加器、除法器和指数运算单元来支持scaling和softmax操作,乘法的输出给除法器或者累加器,因此scaling和softmax可以和矩阵乘重叠执行。
PE-FFT/IFFT,如下图所示,包括了一个FFT/IFFT计算核、一个累加器、一个加法器。累加器是一个N输入(和FFT/IFFT计算核一样大)的加法树,FFT的实现参考Radix-2 Cooley Tukey算法[^6]
softmax,由于指数计算资源占用较大,因此采用分段线性函数来估计指数的输出。包括一个buffer保存
e
x
p
(
x
i
)
exp(x_i)
exp(xi),一个累加器计算
e
x
p
(
x
j
)
exp(x_j)
exp(xj)的和。

设计自动化最大化资源利用
参考文献
[6]: S Lennart Johnsson and Robert L Krawitz. 1992. Cooley-tukey fft on the connection machine. Parallel Computing, 18, 11, 1201–1221.
评
提出了一个FPGA设计,算子颗粒度较小,可以组合形成基本的操作,但没有详细说明FPGA设计的数据流。
Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. [n. d.] Pointer sentinel mixture models. In 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017 ↩︎


















 2291
2291

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











