







1、Dropout原理
为了应对神经网络很容易过拟合的问题,2014年 Hinton 提出了一个神器,
**Dropout: A Simple Way to Prevent Neural Networks from Overfitting **
(original paper: http://jmlr.org/papers/v15/srivastava14a.html)
实验结果:

dropout 是指在深度学习网络的训练过程中,按照一定的概率将一部分神经网络单元暂时从网络中丢弃,相当于从原始的网络中找到一个更瘦的网络

在大规模的神经网络中有这样两个缺点:1. 费时;2. 容易过拟合
对于一个有 N 个节点的神经网络,有了 dropou t后,就可以看做是 2^N 个模型的集合了,但此时要训练的参数数目却是不变的,这就缓解了费时的问题。
论文中做了这样的类比,无性繁殖可以保留大段的优秀基因,而有性繁殖则将基因随机拆了又拆,破坏了大段基因的联合适应性,但是自然选择中选择了有性繁殖,物竞天择,适者生存,可见有性繁殖的强大。
dropout 也能达到同样的效果,它强迫一个神经单元,和随机挑选出来的其他神经单元共同工作,消除减弱了神经元节点间的联合适应性,增强了泛化能力。
每层 Dropout 网络和传统网络计算的不同之处:

相应的公式:

对于单个神经元是这样的:
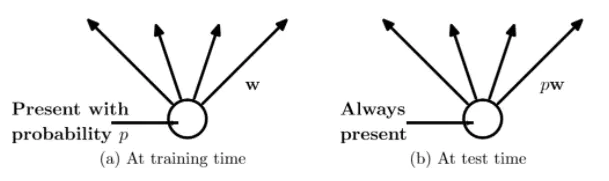
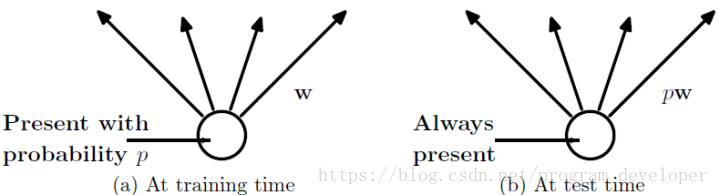
在训练时,每个神经单元都可能以概率 p 去除;
在测试阶段,每个神经单元都是存在的,权重参数w要乘以p,成为:pw。
问题:binary 分类,根据数据集,识别 rocks 和 mock-mines
数据集下载:存在 sonar.csv 里面,http://archive.ics.uci.edu/ml/machine-learning-databases/undocumented/connectionist-bench/sonar/sonar.all-data
Baseline 中,NN 具有两个 隐藏层,分别有 60 和 30 个神经元,用 SGD 训练,并用 10-fold cross validation 得到 classification accuracy 为: 86.04%



在两个隐藏层之间,第二个隐藏层和 output 层之间加入 dropout 后,accuracy 为:84.00%

可见本例并不适合用 dropout 的。
2、为什么标准的 Dropout一般是不能用于卷积层
最初的Dropout是用于输入层或者是全连接层,目的就是为了防止由于数据量或者模型过大导致的过拟合问题。
标准的 Dropout一般是不能用于卷积层的,原因是因为在卷积层中图像中相邻的像素共享很多相同的信息,如果它们中的任何一个被删除,那么它们所包含的信息可能仍然会从仍然活动的相邻像素传递。所以卷积层中的dropout只是增加了对噪声输入的鲁棒性,而不是在全连接层中观察到的模型平均效果。
Dropout一般用于全连接层。
3、pytorch dropout用法
1 、设置为训练模式
使用F.dropout ( nn.functional.dropout )的时候需要设置它的training这个状态参数与模型整体的一致.
错误示范
比如:
Class DropoutFC(nn.Module):
def __init__(self):
super(DropoutFC, self).__init__()
self.fc = nn.Linear(100,20)
def forward(self, input):
out = self.fc(input)
out = F.dropout(out, p=0.5)
return out
Net = DropoutFC()
Net.train()
# train the Net
这段代码中的F.dropout实际上是没有任何用的, 因为它的training状态一直是默认值False. 由于F.dropout只是相当于引用的一个外部函数, 模型整体的training状态变化也不会引起F.dropout这个函数的training状态发生变化. 所以, 此处的out = F.dropout(out) 就是 out = out. Ref:https://github.com/pytorch/pytorch/blob/master/torch/nn/functional.py#L535
正确的使用方法
如下, 将模型整体的training状态参数传入dropout函数
Class DropoutFC(nn.Module):
def __init__(self):
super(DropoutFC, self).__init__()
self.fc = nn.Linear(100,20)
def forward(self, input):
out = self.fc(input)
out = F.dropout(out, p=0.5, training=self.training)
return out
Net = DropoutFC()
Net.train()
# train the Net
或者直接使用nn.Dropout() (nn.Dropout()实际上是对F.dropout的一个包装, 也将self.training传入了) Ref: https://github.com/pytorch/pytorch/blob/master/torch/nn/modules/dropout.py#L46
Class DropoutFC(nn.Module):
def __init__(self):
super(DropoutFC, self).__init__()
self.fc = nn.Linear(100,20)
self.dropout = nn.Dropout(p=0.5)
def forward(self, input):
out = self.fc(input)
out = self.dropout(out)
return out
Net = DropoutFC()
Net.train()
# train the Net
2 、注意事项
代码层面实现让某个神经元以概率p停止工作,其实就是让它的激活函数值以概率p变为0。比如我们某一层网络神经元的个数为1000个,其激活函数输出值为y1、y2、y3、…、y1000,我们dropout比率选择0.4,那么这一层神经元经过dropout后,1000个神经元中会有大约400个的值被置为0。
注意: 经过上面屏蔽掉某些神经元,使其激活值为0以后,我们还需要对向量y1……y1000进行缩放,也就是乘以1/(1-p)。如果你在训练的时候,经过置0后,没有对y1……y1000进行缩放(rescale),那么在测试的时候,就需要对权重进行缩放,操作如下。
测试阶段Dropout公式:
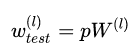
3.通过代码理解
# coding:utf-8
import numpy as np
# dropout函数的实现,函数中,x是本层网络的激活值。Level就是dropout就是每个神经元要被丢弃的概率。
def dropout(x, level):
if level < 0. or level >= 1: #level是概率值,必须在0~1之间
raise ValueError('Dropout level must be in interval [0, 1[.')
retain_prob = 1. - level
# 我们通过binomial函数,生成与x一样的维数向量。binomial函数就像抛硬币一样,我们可以把每个神经元当做抛硬币一样
# 硬币 正面的概率为p,n表示每个神经元试验的次数
# 因为我们每个神经元只需要抛一次就可以了所以n=1,size参数是我们有多少个硬币。
random_tensor = np.random.binomial(n=1, p=retain_prob, size=x.shape) #即将生成一个0、1分布的向量,0表示这个神经元被屏蔽,不工作了,也就是dropout了
print(random_tensor)
x *= random_tensor
print(x)
x /= retain_prob
return x
#对dropout的测试,大家可以跑一下上面的函数,了解一个输入x向量,经过dropout的结果
x=np.asarray([1,2,3,4,5,6,7,8,9,10],dtype=np.float32)
dropout(x,0.4)
从论文解读:https://blog.csdn.net/stdcoutzyx/article/details/49022443
在BP网络的实现:https://blog.csdn.net/qq_28888837/article/details/84673884
完整代码:https://github.com/viki6666/Pytorch_learn/blob/master/dropout.ipynb















 324
324











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









