







1.K均值聚类
Kmeans算法是最常用的聚类算法,主要思想是:在给定K值和K个初始类簇中心点的情况下,把每个点(亦即数据记录)分到离其最近的类簇中心点所代表的类簇中,所有点分配完毕之后,根据一个类簇内的所有点重新计算该类簇的中心点(取平均值),然后再迭代的进行分配点和更新类簇中心点的步骤,直至类簇中心点的变化很小,或者达到指定的迭代次数。
我们假设有数据样本X,里面有n个对象,每个对象都具有m个维度的属性。为了计算每个样本到类簇的距离,我们要找出类簇中心,首先初始化k个聚类中心{C1,C2,C3,……,Ck},
(1<k<=n),下面是类簇中心的计算公式:
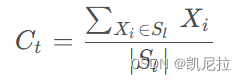
其中 Ct 表示第t个聚类的中心,1<=t<=k,|Sl|表示第l个类簇中对象的个数,Xi表示第i个类簇中第i个对象,1<=i<=|Si|
接下来计算每个对象到每个聚类中心的距离公式如下:
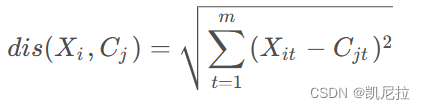
其中,Xi表示第i个对象,1<=i<=n,Cj表示第j个聚类中心的1<=j<=k,Xit表示第i个对象的第t个属性,1<=t<=m,Cjt表示第j个聚类中心的第t个属性。
总结:在K个初始类簇中心点的情况下,把每个点分到离其最近的类簇中心点所代表的类簇中,所有点分配完毕之后,根据一个类簇内的所有点重新计算该类簇的中心点,然后再迭代的进行分配点和更新类簇中心点的步骤,直至类簇中心点的变化很小,或者达到指定的迭代次数。
2.K均值聚类是生成式还是判别式方法?
属于判别式方法
3.KNN VS. K-means
KNN
对未知类别属性的数据集中的每个点依次执行以下操作:
1.计算已知类别数据集中的点与当前点之间的距离;
2.按照距离递增次序排序;
3.选取与当前点距离最小的K个点;
4.确定前K个点所在类别出现的概率;
5.返回前K个点出现频率最高的类别作为当前点的预测分类。
K-means
1.创建K个点作为初始中心;
2.将数据集中的每一个点分配到一个类簇中,具体来讲,为每个点找距其最近的中心,并将其分配给该中心所对应的类簇;
3.上步完成之后,更新中心,每个类簇的中心更新为该类簇所有点的平均值;
4.当任意一个点的类簇分配结果发生改变时,对数据集中的每个数据点,对每个中心,计算中心与数据点之间的距离,将数据点分配到距离其最近的类簇,对每一个类簇,计算类簇中所有点的均值并将均值作为中心;
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 234
234











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









