







目录
1. 上传解压hadoop包(一台就行,后续在一台主机上面完成所有的配置文件修改分发到别的主机上面)。 tar -zxvf hadoop-2.7.1.tar.gz

2. 配置环境变量 vim /etc/profile
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.362.b08-1.el7_9.x86_64
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export HADOOP_HOME=/root/hadoop-2.7.1
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH

3. 修改配置文件 (在、hadoop-2.7.1/etc/hadoop) core-site.xml mapred-site.xml hdfs-site.xml yarn-site.xml
core-site.xml配置
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<!-- 指定HDFS老大(namenode)的通信地址 bluesky01指的是IP 访问hdf会解析此关键字-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://bluesky01</value>
</property>
<!-- 指定hadoop运行时产生文件的存储路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>file:///root/hadoop-2.7.1/tmp</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
</configuration>
mapred-site.xml配置
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<!-- 指定mapreduce运算时资源调度为 yarn 模式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 配置mapreduce历史服务器地址 端口号 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>bluesky01:10020</value>
</property>
<!-- 配置mapreduce历史服务器WEB访问地址 配合yarn-site.xml yarn.log.server.url使用 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>bluesky01:19888</value>
</property>
</configuration>
hdfs-site.xml配置
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<!-- 指定HDFS的nameservice为mycluster,需要跟core-site.xml中保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>bluesky</value>
</property>
<!-- 指定hdfs的两个NameNode都是什么名字 -->
<property>
<name>dfs.ha.namenodes.bluesky</name>
<value>nn1,nn2</value>
</property>
<!-- NameNode1的rpc通讯地址-->
<property>
<name>dfs.namenode.rpc-address.bluesky.nn1</name>
<value>bluesky01:8020</value>
</property>
<!-- NameNode2的rpc通讯地址-->
<property>
<name>dfs.namenode.rpc-address.bluesky.nn2</name>
<value>bluesky02:8020</value>
</property>
<!-- NameNode1的web界面地址-->
<property>
<name>dfs.namenode.http-address.bluesky.nn1</name>
<value>bluesky01:50070</value>
</property>
<!-- NameNode2的web界面地址-->
<property>
<name>dfs.namenode.http-address.bluesky.nn2</name>
<value>bluesky02:50070</value>
</property>
<!--namenode存放元数据信息的Linux本地地址,这个目录不需要我们自己创建-->
<!--如果给一个有数据的HDFS添加HA,此处无需更改,保持原有地址即可-->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///root/hadoop-2.7.1/hadoopdata/dfs</value>
</property>
<!--datanode存放用户提交的大文件的本地Linux地址,这个目录不需要我们自己创建-->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///root/hadoop-2.7.1/hadoopdata/dfs/data</value>
</property>
<!--###########################################################-->
<!-- QJM存放共享数据的方式-->
<!-- 指定NameNode的元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://bluesky01:8485;bluesky02:8485;bluesky03:8485/bluesky</value>
</property>
<!-- 单个QJM进程(角色)存放本地edits文件的Linux地址-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/root/hadoop-2.7.1/hadoopdata/journal</value>
</property>
<!--开启hdfs的namenode死亡后自动切换-->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!--指定zookeeper集群地址,辅助两个namenode进行失败切换 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>bluesky01:2181,bluesky02:2181,bluesky03:2181</value>
</property>
<!-- 配置nameNode失败自动切换的实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.qm1707</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 防止多个namenode同时active(脑裂)的方式-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 配置隔离机制方法 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<!-- 使用sshfence隔离机制时需要ssh免密登录 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- 配置sshfence隔离机制超时时间 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
yarn-site.xml配置
<?xml version="1.0"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- 开启高可用 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定ResourceManager的标识:blueskyyarn -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>blueskyyarn</value>
</property>
<!-- 指定RM的名字 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 指定rm1服务器 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>bluesky01</value>
</property>
<!-- 指定rm2服务器 -->
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>bluesky02</value>
</property>
<!-- 指定rm 被管理的zk地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>bluesky01:2181,bluesky02:2181,bluesky03:2181</value>
</property>
<!-- 运行mapreduce任务需要使用的服务 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 开启yarn集群的日志聚合功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志保存时间 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>86400</value>
</property>
<!-- yarn日志据聚合web配置 -->
<property>
<name>yarn.log.server.url</name>
<value>http://bluesky01:19888/jobhistory/logs</value>
</property>
<!-- 启动rm自动恢复功能 -->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!-- 制定rm 状态信息存储在zookeeper集群上 -->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>bluesky01:8030</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>bluesky02:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>bluesky01:8031</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>bluesky02:8031</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>bluesky01:8032</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>bluesky02:8032</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>bluesky01:8033</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>bluesky02:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>bluesky01:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>bluesky02:8088</value>
</property>
</configuration>
4. 修改hadoop-env.sh
hadoop-env.sh 脚本修改主要是把java_home写成绝对路径(感觉不写也行因为环境变量配置了 不过没实验!)
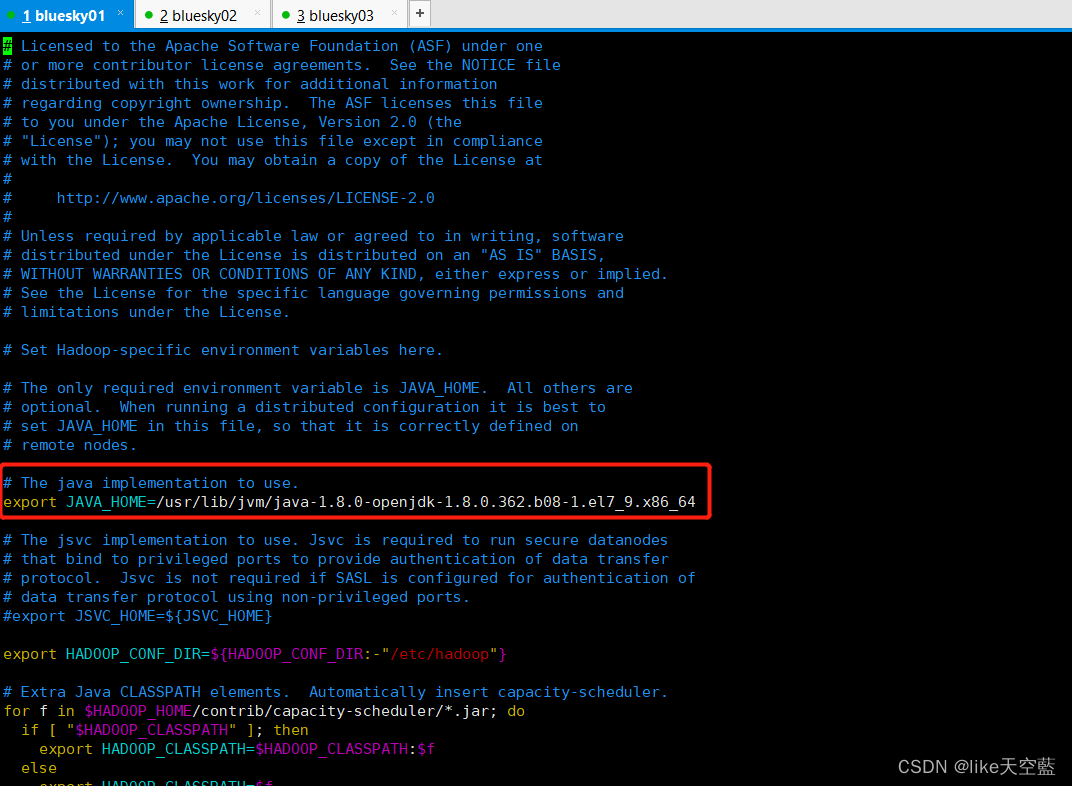
slave文件 配置 此文件主要配置的从节点(例如:如果从节点有八个,那就把这八个主机名称或者ip写这里。 )

5. ok! 上面所有步骤完成后,将hadoop文件夹分发到各个主机。
6. 现在去启动集群! let's go!
环境启动顺序(严格按照步骤执行)
(1).先启动zk集群(保证zk集群处于服务状态)
(2).再启动journalnode(QJM中的组件)(在各个zk节点上启动)
# hadoop-daemon.sh start journalnode
(3).格式化HDFS(在master上执行命令: 格式化HA必须先启动zk服务、journalnode)
# hadoop namenode -format
(4).在第二个NameNode机器上同步第一个NameNode集群上的dfs目录 ,可以通过scp拷贝,也可以使用 命令:
4.1)先启动第一个NameNode机器上的NameNode:
# hadoop-daemon.sh start namenode
4.2)在第二个NameNode机器上执行:
# hdfs namenode -bootstrapStandby
(5).格式化ZK(在Master上执行即可)
# hdfs zkfc -formatZK
(6).启动hdfs集群和yarn集群
# start-all.sh stop-all.sh 启动停止
(7). 启动yarm日志聚合功能 (yarn-site.xml 和 mapred-site.xml配置)
# mr-jobhistory-daemon.sh start historyserver
启动的时候都会有日志输出如果出现错误, 不要蒙蔽,不要慌张,仔细观察输出日志,都在日志中
集群的主要进程:
NameNode hdfs主节点
DataNode hdfs从节点
ResourceManager yran主节点
NodeManager yarn从节点
JournalNode 管理两个namenode之间的数据同步
QuorumPeerMain 管理zookeeper的进程
DFSZKFailoverController 管理主备节点自动切换的进程
JobHistoryServer yarn日志聚合服务进程
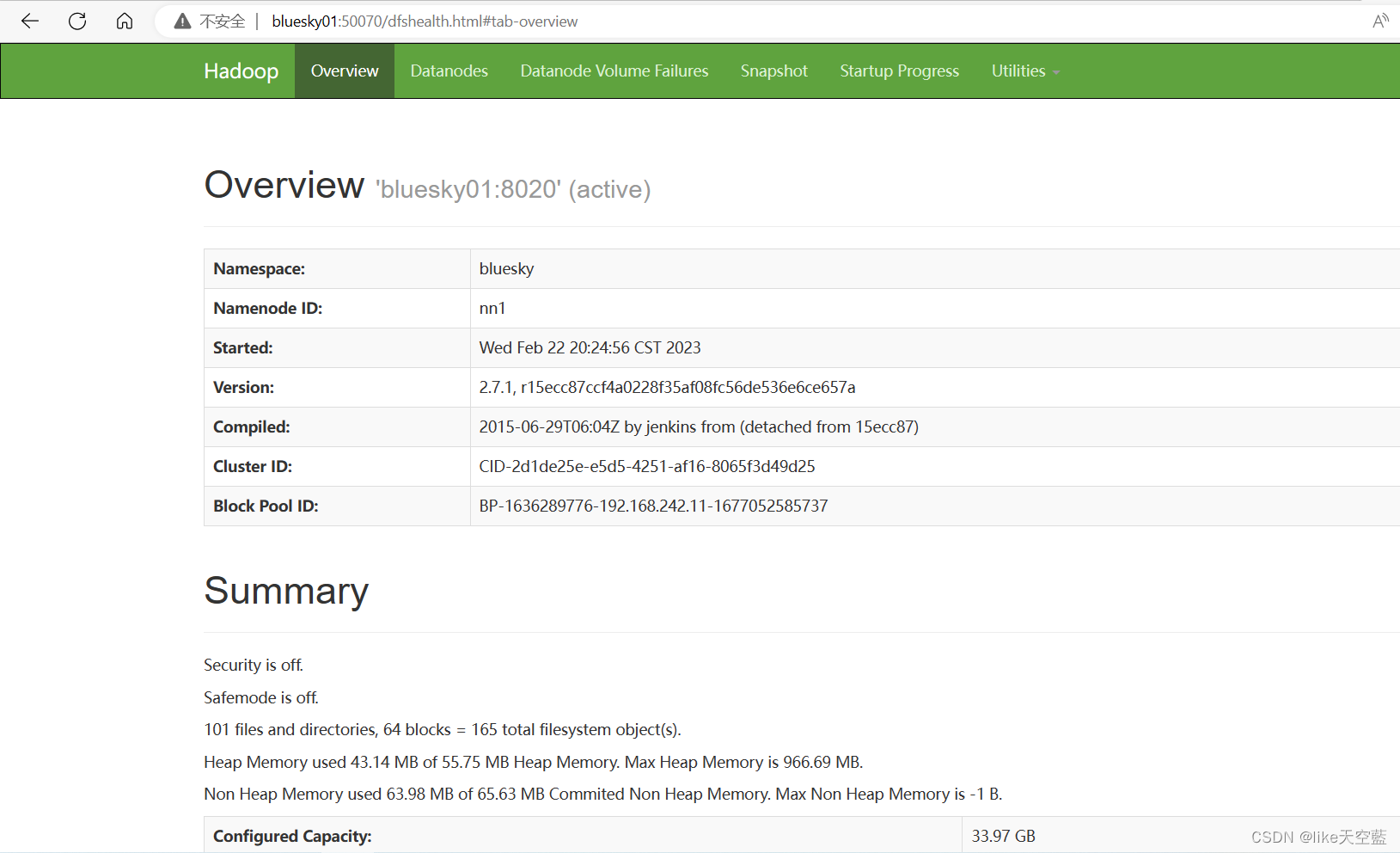
hdfs 默认访问端口50070
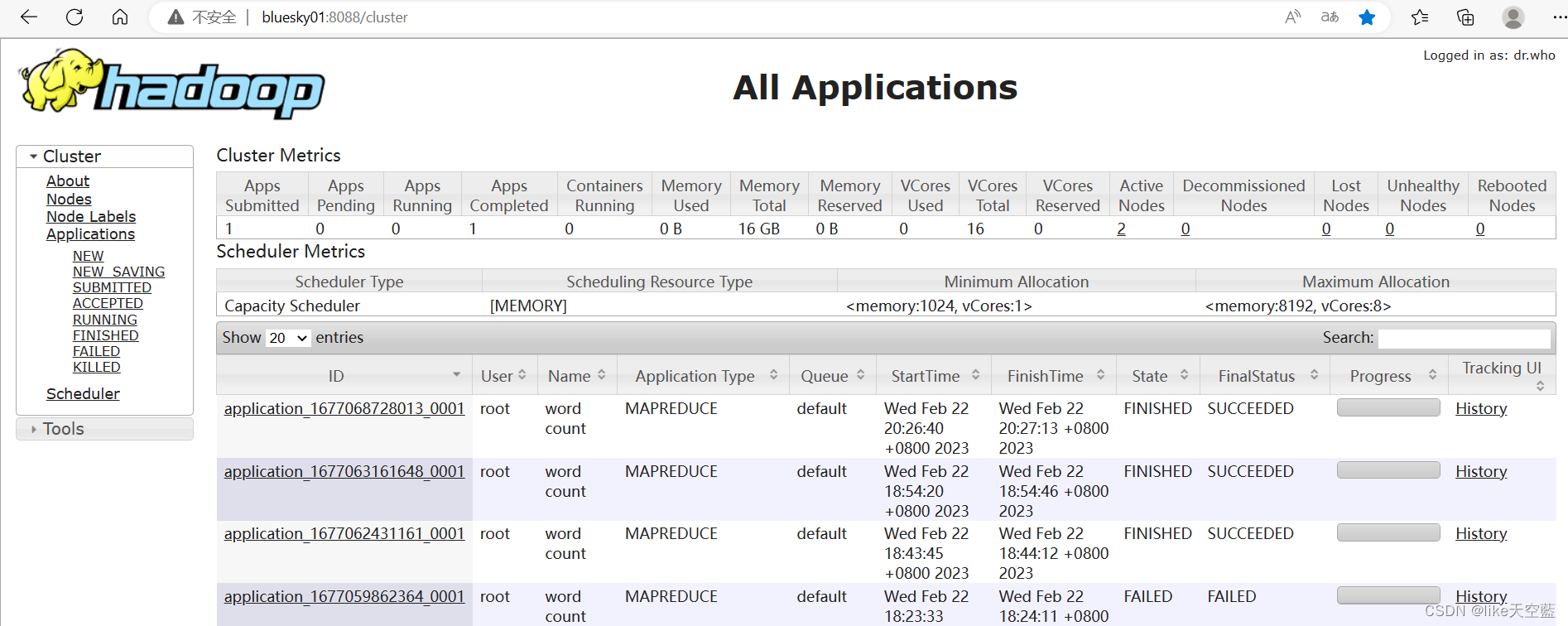
yran 默认访问端口8088
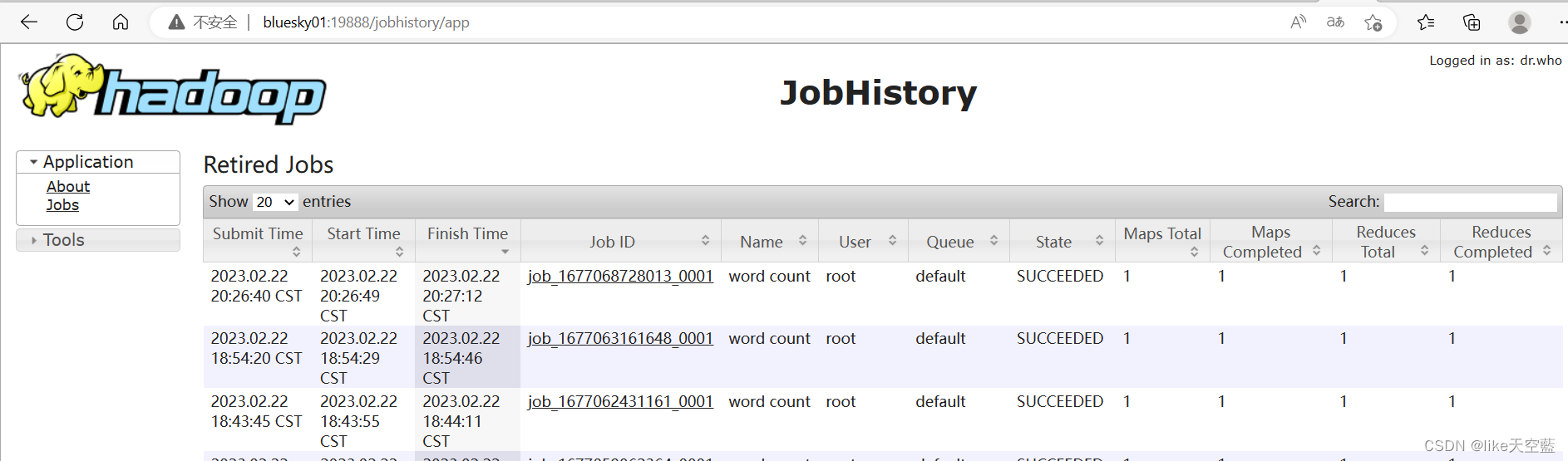
yran聚合日志 默认访问端口19888
验证集群的可用性 : hadoop fs -ls /
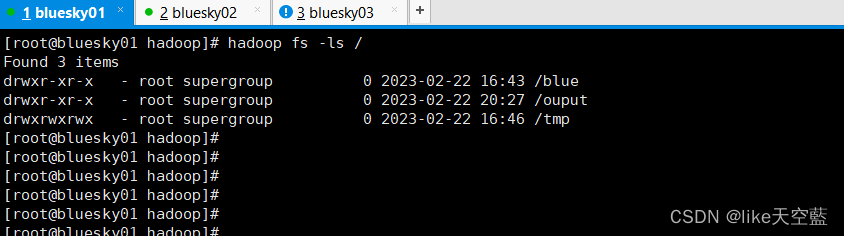
用mr跑一个wordcount函数:
1) vim word.txt (本地新建文件)
2) hadoop fs -put ./word.txt /blue (上传hdfs)
3) hadoop jar /root/hadoop-2.7.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar wordcount /word.txt /output
job运行成功后, 输出的结果会在hdfs系统的/output文件夹下面。
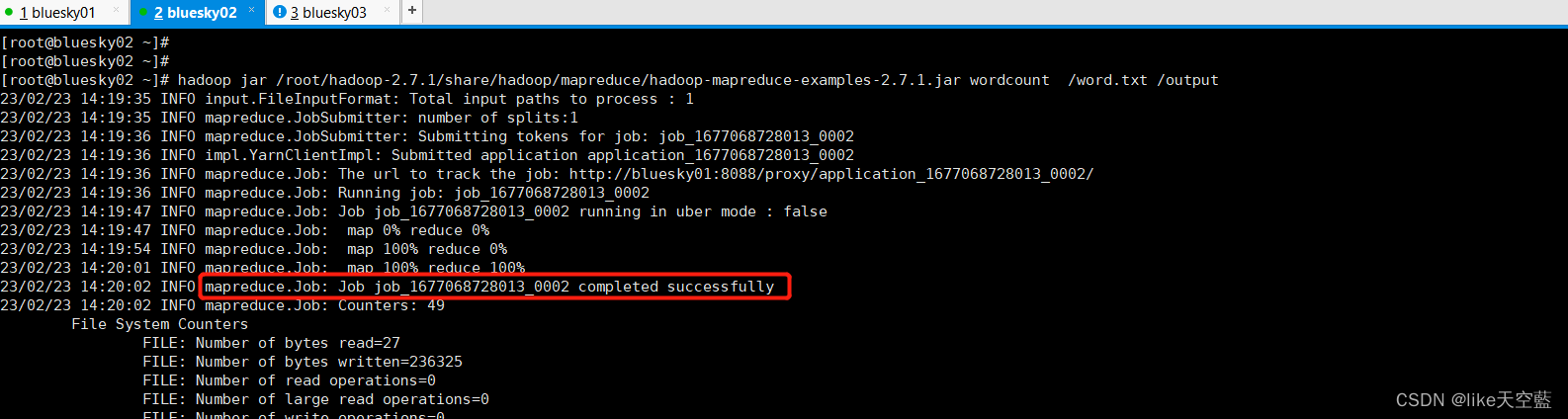
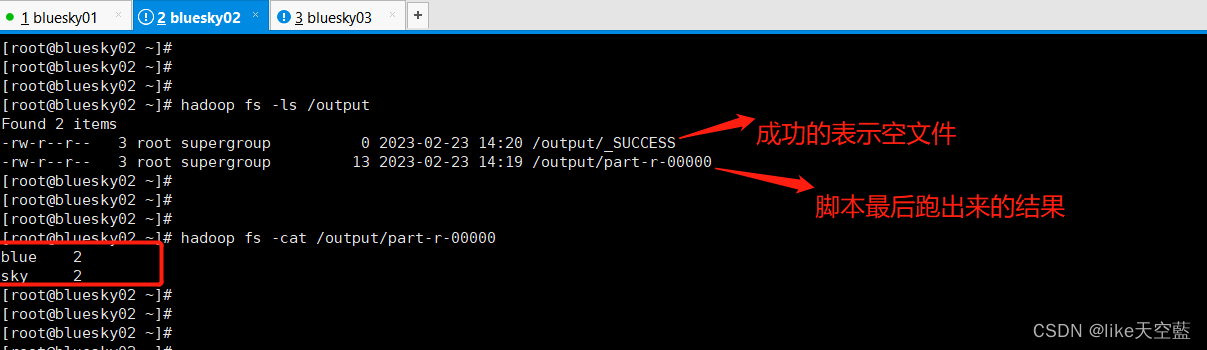
总结下:
修改java hadoop变量
修改四个主要配置文件 (core文件 mapred文件 yran文件 hdfs文件)
一个hadoop环境脚本, 一个slave文件 (hadoop-env.sh slave)
按启动脚本初始化启动。
如果需要重新配置HDFS的HA,需要删除四个地方:(待测试)
一:zk里的hadoop-ha节点需要被删除
进入zk客户端,执行命令:rmr /hadoop-ha
二:namenode的存储edits 文件的目录删除
即配置文件中的此配置项的值:dfs.namenode.name.dir /root/hadoop-2.7.1/hadoopdata/dfs
三:datanode的存储block文件的目录删除
即配置文件中的此配置项的值:dfs.datanode.data.dir /root/hadoop-2.7.1/hadoopdata/dfs/data
四:journode的存储edits文件的目录删除
即配置文件中的此配置项的值:/home/hadoop/hadoop-2.6.0/hadoopdata/journal
相信自己可以的,看着很难而已,都是纸老虎。















 1939
1939











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









