









论文:BiSeNet V2: Bilateral Network with Guided Aggregation for Real-time Semantic Segmentation
论文repo:https://github.com/CoinCheung/BiSeNet
一、摘要
类似BiSeNetV1的结构,BiSeNetV2有2个分支,分别为Detail Branch 和 Semantic Branch,Detail分支层数少但是通道数多,生成高分辨率的带有细节的特征图;Semantic 分支层数多,但是通道小,用来捕获高级的语义上下文信息。最后使用Guided Aggregation Layer来融合2个分支的输出。此外还引入了多个辅助损失函数来提高模型的性能。
该模型输入为2048x1024时,Cityscapes测试集上miou为72.6%,在NVIDIA GeForce GTX 1080 Ti上的FPS达到156。
二、网络结构
下图为BiSeNetV2的网络结构,主要包含Backbone、Context Embedding Block, Aggregation Layer:
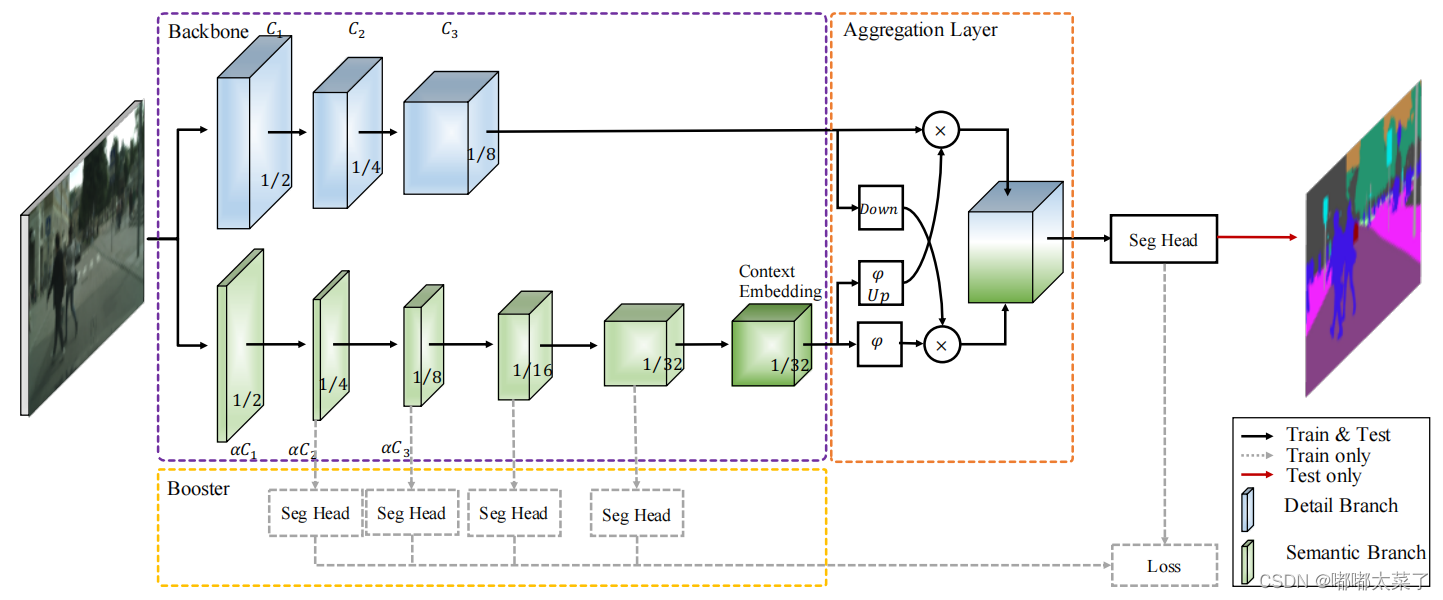
Detail Branch: Detail分支的任务是保存低级特征的空间细节信息,所以该分支的设计理念就是通道多,层数少,下采样比率低。为了防止模型速度降低,没有采用residual connection。
Semantic Branch:Semantic分支的目标是捕获高级的语义信息,所示他的设计理念是通道少,层数多,下采样比率大(增加感受野)。该分支可替换为其他的backbone。
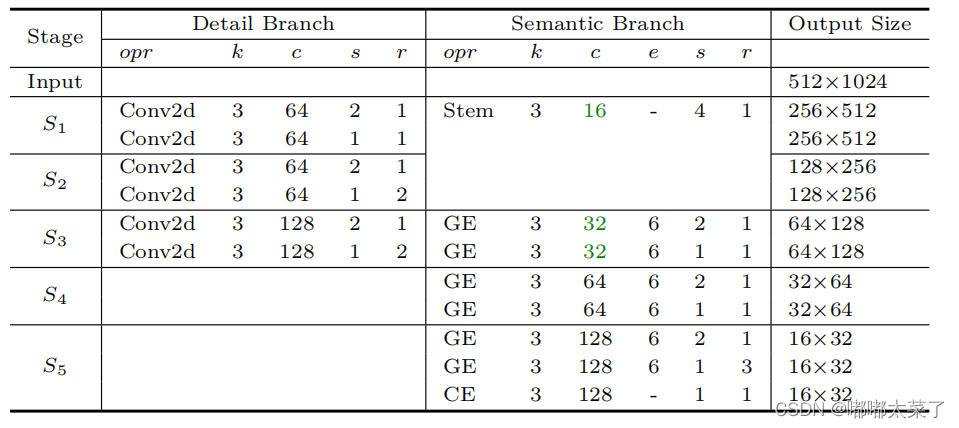
模型的具体设计如下图(Conv2d后都接BatchNormalization和relu层),k表示卷积核的大小,c表示该层输出的通道数,s表示步长,r表示改层重复次数,e表示卷积的膨胀系数,Stem是Stem Block,GE是Gather and Expansion Layer,CE是Context Embedding Layer。
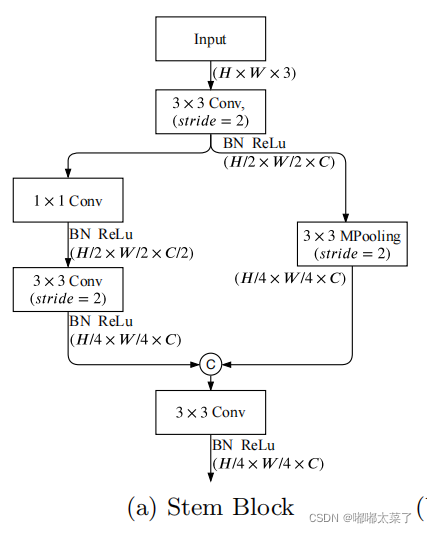
Stem Block
Stem模块如下图所示,输入经过一个步长为2的卷积下采样1/2,后,经过卷积分支和池化分支,并把2分支的输出concat,得到1/4的特征图。
Stem Block代码如下:
class StemBlock(nn.Module):
def __init__(self):
super(StemBlock, self).__init__()
self.conv = ConvBNReLU(3, 16, 3, stride=2)
self.left = nn.Sequential(
ConvBNReLU(16, 8, 1, stride=1, padding=0),
ConvBNReLU(8, 16, 3, stride=2),
)
self.right = nn.MaxPool2d(
kernel_size=3, stride=2, padding=1, ceil_mode=False)
self.fuse = ConvBNReLU(32, 16, 3, stride=1)
def forward(self, x):
feat = self.conv(x)
feat_left = self.left(feat)
feat_right = self.right(feat)
feat = torch.cat([feat_left, feat_right], dim=1)
feat = self.fuse(feat)
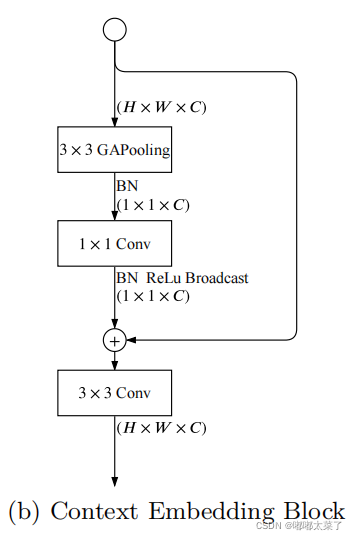
return featContext Embedding Block
该模块使用全局池化和残差连接,在特征图中加入全局上下文信息。
Context Embedding Block代码如下:
class CEBlock(nn.Module):
def __init__(self):
super(CEBlock, self).__init__()
self.bn = nn.BatchNorm2d(128)
self.conv_gap = ConvBNReLU(128, 128, 1, stride=1, padding=0)
#TODO: in paper here is naive conv2d, no bn-relu
self.conv_last = ConvBNReLU(128, 128, 3, stride=1)
def forward(self, x):
feat = torch.mean(x, dim=(2, 3), keepdim=True)
feat = self.bn(feat)
feat = self.conv_gap(feat)
feat = feat + x
feat = self.conv_last(feat)
return featGather and Expansion Layer:
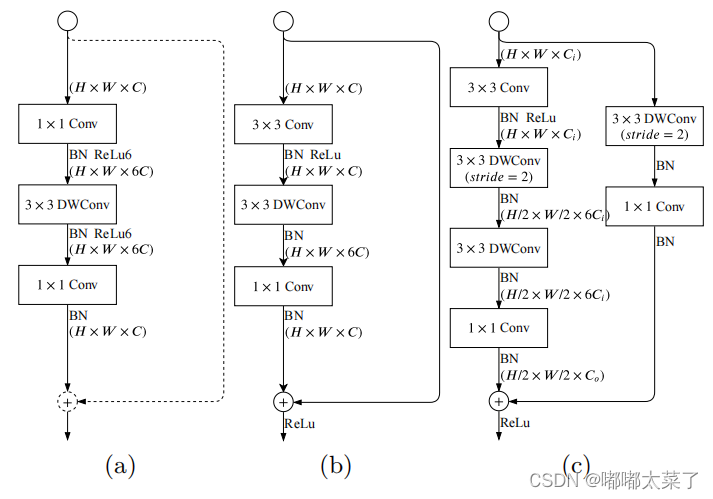
下图a是MobileNetV2的逆瓶颈结构,b和c是Gather and expansion layer, b和c的区别在于输出特征图大小不同,当需要降低输入特征图的分辨率时,使用c结构,如果分辨率不变,使用b结构。
gather and expansion layer代码,上图b的代码:
class GELayerS1(nn.Module):
def __init__(self, in_chan, out_chan, exp_ratio=6):
super(GELayerS1, self).__init__()
mid_chan = in_chan * exp_ratio
self.conv1 = ConvBNReLU(in_chan, in_chan, 3, stride=1)
self.dwconv = nn.Sequential(
nn.Conv2d(
in_chan, mid_chan, kernel_size=3, stride=1,
padding=1, groups=in_chan, bias=False),
nn.BatchNorm2d(mid_chan),
nn.ReLU(inplace=True), # not shown in paper
)
self.conv2 = nn.Sequential(
nn.Conv2d(
mid_chan, out_chan, kernel_size=1, stride=1,
padding=0, bias=False),
nn.BatchNorm2d(out_chan),
)
self.conv2[1].last_bn = True
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
feat = self.conv1(x)
feat = self.dwconv(feat)
feat = self.conv2(feat)
feat = feat + x
feat = self.relu(feat)
return feat图c的代码:
class GELayerS2(nn.Module):
def __init__(self, in_chan, out_chan, exp_ratio=6):
super(GELayerS2, self).__init__()
mid_chan = in_chan * exp_ratio
self.conv1 = ConvBNReLU(in_chan, in_chan, 3, stride=1)
self.dwconv1 = nn.Sequential(
nn.Conv2d(
in_chan, mid_chan, kernel_size=3, stride=2,
padding=1, groups=in_chan, bias=False),
nn.BatchNorm2d(mid_chan),
)
self.dwconv2 = nn.Sequential(
nn.Conv2d(
mid_chan, mid_chan, kernel_size=3, stride=1,
padding=1, groups=mid_chan, bias=False),
nn.BatchNorm2d(mid_chan),
nn.ReLU(inplace=True), # not shown in paper
)
self.conv2 = nn.Sequential(
nn.Conv2d(
mid_chan, out_chan, kernel_size=1, stride=1,
padding=0, bias=False),
nn.BatchNorm2d(out_chan),
)
self.conv2[1].last_bn = True
self.shortcut = nn.Sequential(
nn.Conv2d(
in_chan, in_chan, kernel_size=3, stride=2,
padding=1, groups=in_chan, bias=False),
nn.BatchNorm2d(in_chan),
nn.Conv2d(
in_chan, out_chan, kernel_size=1, stride=1,
padding=0, bias=False),
nn.BatchNorm2d(out_chan),
)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
feat = self.conv1(x)
feat = self.dwconv1(feat)
feat = self.dwconv2(feat)
feat = self.conv2(feat)
shortcut = self.shortcut(x)
feat = feat + shortcut
feat = self.relu(feat)
return featGuided Aggregation Layer:
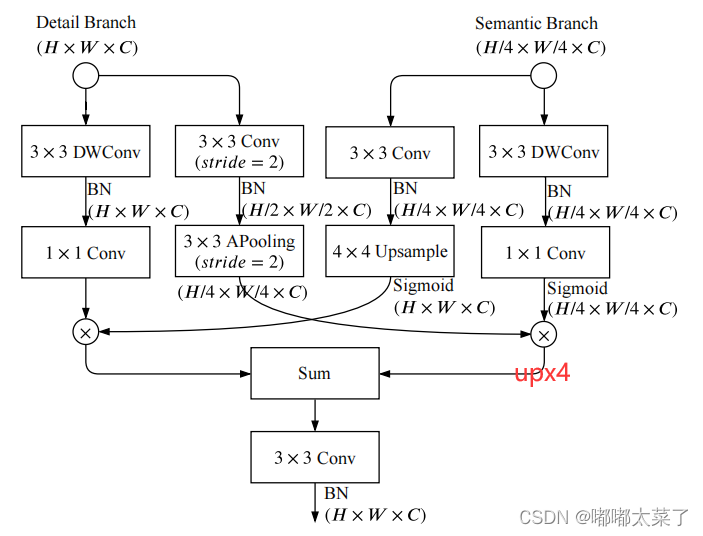
Detail分支和Semantic分支的特征图通过Guided Aggregation Layer进行融合,利用Semantic分支得到的上下文信息来指导Detail分支的特征图输出,并且左右2个分支特征图尺度不同,这样可以得到多尺度信息。需要注意的是图中右下角,1/4尺度的输出在求和前有个上采样4倍的操作使得左右分支输出分辨率相同。
该模块代码如下:
class BGALayer(nn.Module):
def __init__(self):
super(BGALayer, self).__init__()
self.left1 = nn.Sequential(
nn.Conv2d(
128, 128, kernel_size=3, stride=1,
padding=1, groups=128, bias=False),
nn.BatchNorm2d(128),
nn.Conv2d(
128, 128, kernel_size=1, stride=1,
padding=0, bias=False),
)
self.left2 = nn.Sequential(
nn.Conv2d(
128, 128, kernel_size=3, stride=2,
padding=1, bias=False),
nn.BatchNorm2d(128),
nn.AvgPool2d(kernel_size=3, stride=2, padding=1, ceil_mode=False)
)
self.right1 = nn.Sequential(
nn.Conv2d(
128, 128, kernel_size=3, stride=1,
padding=1, bias=False),
nn.BatchNorm2d(128),
)
self.right2 = nn.Sequential(
nn.Conv2d(
128, 128, kernel_size=3, stride=1,
padding=1, groups=128, bias=False),
nn.BatchNorm2d(128),
nn.Conv2d(
128, 128, kernel_size=1, stride=1,
padding=0, bias=False),
)
self.up1 = nn.Upsample(scale_factor=4)
self.up2 = nn.Upsample(scale_factor=4)
##TODO: does this really has no relu?
self.conv = nn.Sequential(
nn.Conv2d(
128, 128, kernel_size=3, stride=1,
padding=1, bias=False),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True), # not shown in paper
)
def forward(self, x_d, x_s):
dsize = x_d.size()[2:]
left1 = self.left1(x_d)
left2 = self.left2(x_d)
right1 = self.right1(x_s)
right2 = self.right2(x_s)
right1 = self.up1(right1)
left = left1 * torch.sigmoid(right1)
right = left2 * torch.sigmoid(right2)
right = self.up2(right)
out = self.conv(left + right)
return outSegmentation Head:
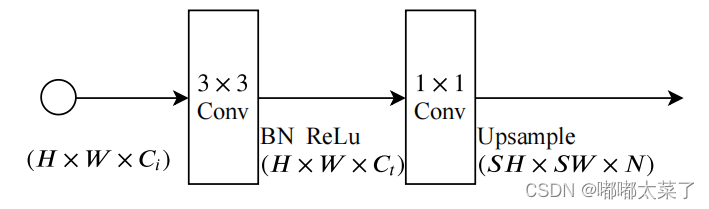
分割头的结构如下,其中S是上采样倍率。
代码如下:
class SegmentHead(nn.Module):
def __init__(self, in_chan, mid_chan, n_classes, up_factor=8, aux=True):
super(SegmentHead, self).__init__()
self.conv = ConvBNReLU(in_chan, mid_chan, 3, stride=1)
self.drop = nn.Dropout(0.1)
self.up_factor = up_factor
out_chan = n_classes
mid_chan2 = up_factor * up_factor if aux else mid_chan
up_factor = up_factor // 2 if aux else up_factor
self.conv_out = nn.Sequential(
nn.Sequential(
nn.Upsample(scale_factor=2),
ConvBNReLU(mid_chan, mid_chan2, 3, stride=1)
) if aux else nn.Identity(),
nn.Conv2d(mid_chan2, out_chan, 1, 1, 0, bias=True),
nn.Upsample(scale_factor=up_factor, mode='bilinear', align_corners=False)
)
def forward(self, x):
feat = self.conv(x)
feat = self.drop(feat)
feat = self.conv_out(feat)
return feat需要注意,上采样是通过PixelShuffle实现的,代码如下:
class UpSample(nn.Module):
def __init__(self, n_chan, factor=2):
super(UpSample, self).__init__()
out_chan = n_chan * factor * factor
self.proj = nn.Conv2d(n_chan, out_chan, 1, 1, 0)
self.up = nn.PixelShuffle(factor)
self.init_weight()
def forward(self, x):
feat = self.proj(x)
feat = self.up(feat)
return feat


















 5024
5024

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











