







常规卷积
- SAME和VALID的用法
- SAME会通过补零不丢失原信息
- VALID不会在原有图片上添加新元素

conv1d
kernel_size=n,实际上的卷积核大小是n*num_col
比如对于语音输入channelTd_col=1620080,一维卷积out_channelTd_col=256K80
反卷积con2D_transpose
实际上是卷积的逆过程,默认padding=valid
keras文档给出的公式
new_rows = ((W - 1) * S + F - 2 * padding[0] + output_padding[0])
new_cols = ((W - 1) * S + F - 2 * padding[1] + output_padding[1])
因为2*padding和output_padding一样,所以相互抵消
new_rows = ((W - 1) * S + F
e.g. 7—15–31
空洞卷积
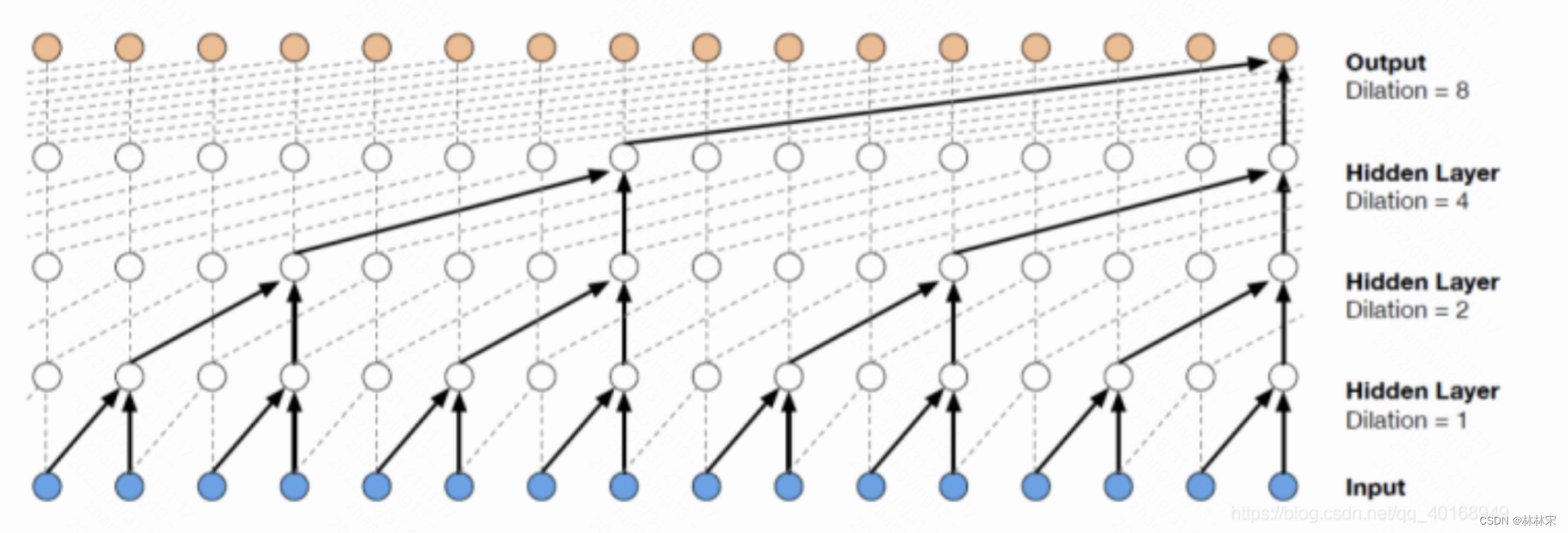
空洞卷积(Dilated convolutions)在卷积的时候,会在卷积核元素之间塞入空格,如上图所示。
这里引入了一个新的超参数 d,(d - 1) 的值则为塞入的空格数,假定原来的卷积核大小为 k,那么塞入了 (d - 1) 个空格后的卷积核大小 n 为:
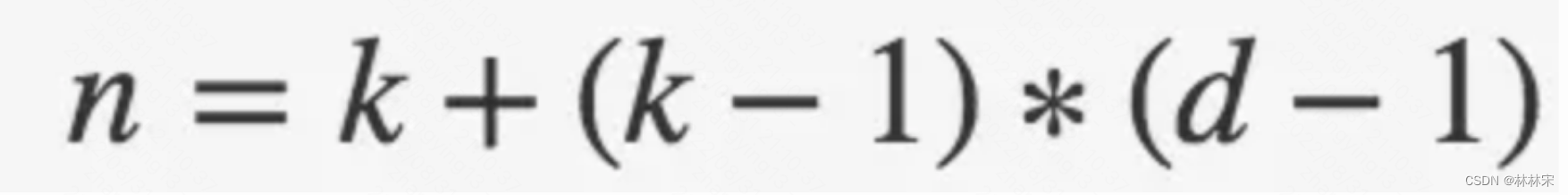
因此输出feature map尺寸是
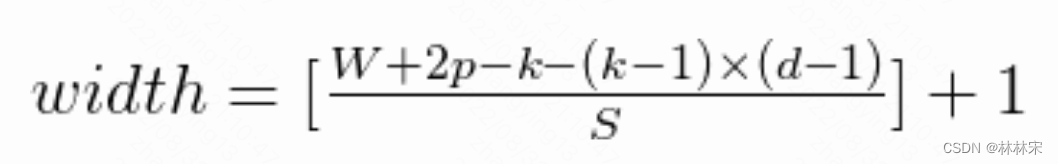
其中【】为取下限符号
d是dialted rate,正常的卷积d=1,起源于语意分割,也在wavnet中有应用,sequence-tp-sequence learning
在图像分割领域,FCN先像传统的CNN那样对图像做卷积再pooling,之前的pooling操作使得每个pixel预测都能看到较大感受野信息。因此图像分割FCN中有两个关键,一个是pooling减小图像尺寸增大感受野,另一个是upsampling扩大图像尺寸。在先减小再增大尺寸的过程中,肯定有一些信息损失掉了,那么能不能设计一种新的操作,不通过pooling也能有较大的感受野看到更多的信息呢?答案就是dilated conv。
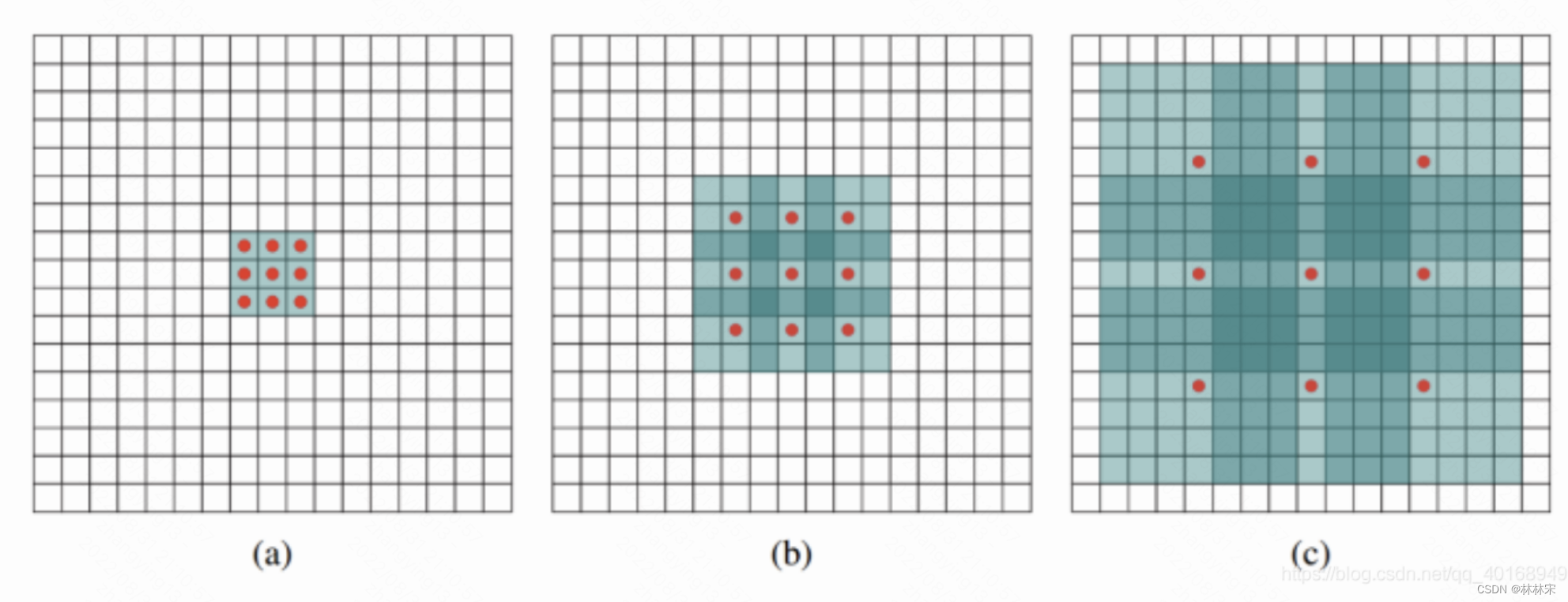
(a)图对应3x3的1-dilated conv,和普通的卷积操作一样
(b)图对应3x3的2-dilated conv,实际的卷积kernel size还是3x3,感受野已经增大到7x7的图像patch。也可以理解为kernel的size为7x7,但是只有图中的9个点的权重不为0,其余都为0。
©图是4-dilated conv操作,同理跟在两个1-dilated和2-dilated conv的后面,能达到15x15的感受野。
对比传统的conv操作,3层3x3的卷积加起来,stride为1的话,只能达到(kernel-1)*layer+1=7的感受野,也就是和层数layer成线性关系,而dilated conv的感受野是指数级的增长。
dilated的好处是不做pooling损失信息的情况下,加大了感受野,让每个卷积输出都包含较大范围的信息。在图像需要全局信息或者语音文本需要较长的sequence信息依赖的问题中,都能很好的应用dilated conv,比如图像分割[3]、语音合成WaveNet[2]、机器翻译ByteNet[1]中。
但是d=2的空洞卷积也有缺点 ,具体可以继续看链接中知乎的帖子。
deconv和dilated conv的区别
deconv的其中一个用途是做upsampling,即增大图像尺寸。而dilated conv并不是做upsampling,而是增大感受野。
可以形象的做个解释:
对于标准的k*k卷积操作,stride为s,分三种情况:
(1) s>1,即卷积的同时做了downsampling,卷积后图像尺寸减小;
(2) s=1,普通的步长为1的卷积,比如在tensorflow中设置padding=SAME的话,卷积的图像输入和输出有相同的尺寸大小;
(3) 0<s<1,fractionally strided convolution,相当于对图像做upsampling。比如s=0.5时,意味着在图像每个像素之间padding一个空白的像素后,stride改为1做卷积,得到的feature map尺寸增大一倍。
而dilated conv不是在像素之间padding空白的像素,而是在已有的像素上,skip掉一些像素,或者输入不变,对conv的kernel参数中插一些0的weight,达到一次卷积看到的空间范围变大的目的。
当然将普通的卷积stride步长设为大于1,也会达到增加感受野的效果,但是stride大于1就会导致downsampling,图像尺寸变小。大家可以从以上理解到deconv,dilated conv,
## 因果卷积casual conv
- 在处理序列问题时,因为要考虑时间,即时刻t只能考虑t时刻及之前的输入,因此引入因果卷积。WaveNet使用的即是这种卷积。
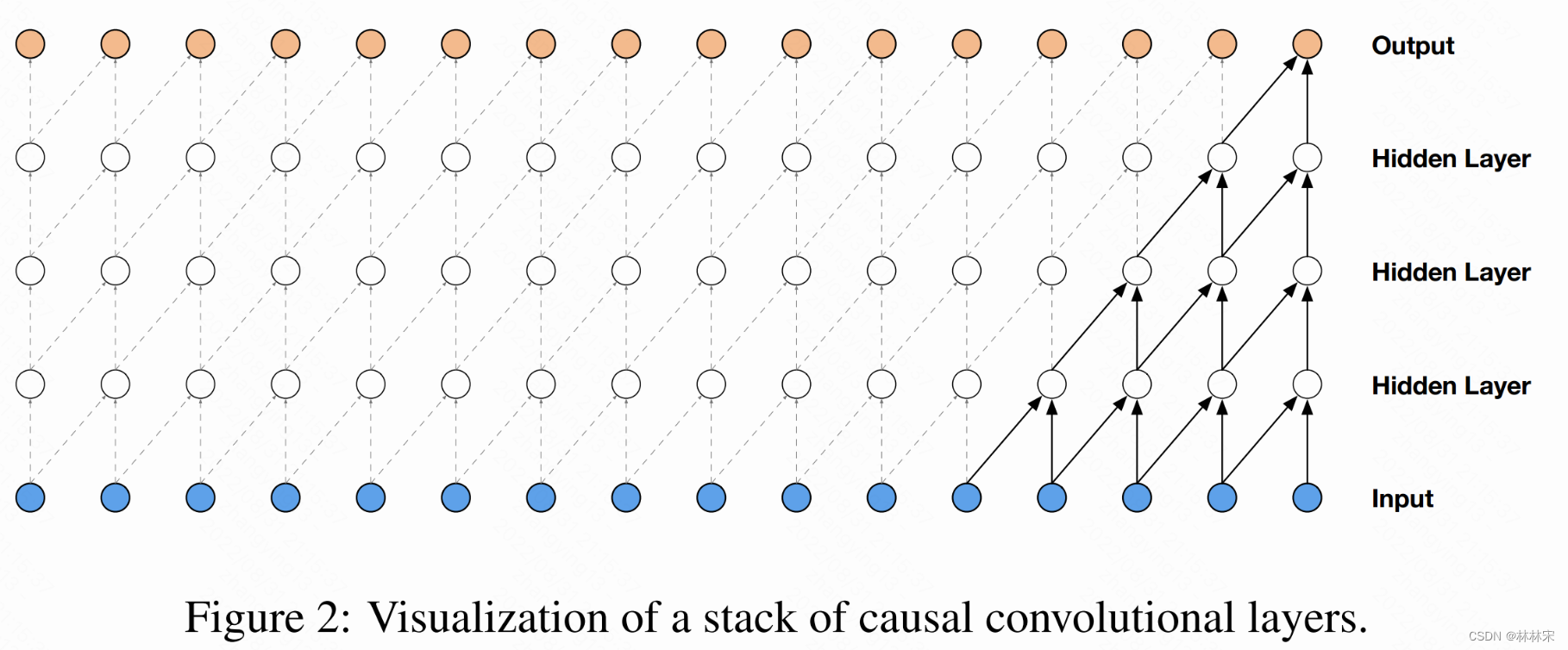
缺点:想要感受野(receptive field)增大,要么增大卷积核,要么加深网络。卷积核增大会带来参数量,加深网络则会带来梯度消失,Internal Covariate Shift,训练不稳定难收敛等问题。于是就有了因果拓展卷积,是因果卷积和空洞卷积和合体。
separable conv
- 可分离卷积:将传统卷积分解为Depthwise Convolution与Pointwise Convolution两部分,有效的减小了参数数量。
- 可分离卷积的详细
class depthwise_conv2d(nn.Module):
def __init__(self, n_in, n_out):
super(depthwise_separable_conv, self).__init__()
self.depth_wise = nn.Conv2d(n_in, n_in, kernel_size=3, padding=1, groups=n_in)
self.point_wise = nn.Conv2d(n_in, n_out, kernel_size=1)
def forward(self, x):
out = self.depth_wise(x)
out = self.point_wise(out)
return out
Lightweight conv
- 对transformer slf-attn的替换,参数量更少
git关于lightconv的官方实现 - 分成cuda-lconv的实现,和普通版本的,但是cuda-lconv无法安装成功,普通版本的加速不大。














 6979
6979











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









