






Temporal action localization in untrimmed videos via multi-stage cnns论文解读
参考链接
Temporal action localization in untrimmed videos via multi-stage cnns是Zheng Shou发表在在CVPR2016上的论文,主要解决视频识别中的两个问题:
Action Recognition: 目的为判断一个已经分割好的短视频片段的类别。特点是简化了问题,一般使用的数据库都先将动作分割好了,一个视频片断中包含一段明确的动作,时间较短(几秒钟)且有唯一确定的label。所以也可以看作是输入为视频,输出为动作标签的多分类问题。常用数据库包括UCF101,HMDB51等。
Temporal Action Location:不仅要知道一个动作在视频中是否发生,还需要知道动作发生在视频的哪段时间(包括开始和结束时间)。特点是需要处理较长的,未分割的视频。且视频通常有较多干扰,目标动作一般只占视频的一小部分。常用数据库包括THUMOS2014/2015, ActivityNet等。
这篇文章主要解决Temporal Action Localization的问题。SCNN指segment based CNN,即基于视频片段的CNN网络
-
网络模型
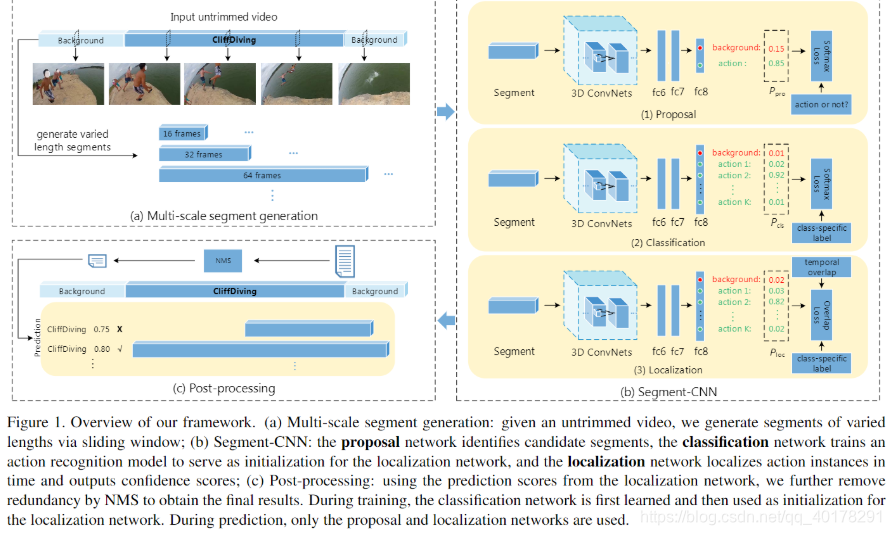
-
多尺度视频片段生成

-
Proposal Network
在生成训练数据时,同时还记录和segment和ground truth instance之间的最大重叠度(IoU)。对于proposal网络来说,将最大IoU大于0.7的标记为true,最大IoU小于0.3的标记为背景。以及类别(即如果存在多个重叠的ground truth,取重叠度最大的那个)。将得到的所有片段输入到C3D网络中,经过fc8后分为两类,即判断是否为背景,训练时将IoU大于0.7的作为正样本(动作),小于0.3的作为负样本(背景),对负样本进行采样使得正负样本比例均衡。采用softmax loss进行训练。proposal network的主要作用是去除一些背景片段。
- Classification Network
经过Proposal Network后,背景被去除,对剩下的数据进行KKK个类别的动作分类。和Proposal Network类似,经过fc8后输出K+1K+1K+1类,其中一类是背景,这个网络被用来初始化localization network, 仅在训练阶段使用,在测试阶段不使用。训练时同样将IoU大于0.7的作为正样本(K类动作),小于0.3的作为背景类,对背景类动作进行采样使得背景类动作的数量和K类动作数量的平均值相近。训练时同样采用softmax loss。
- Localization Network

- 预测阶段
预测时,滑动不同长度的时间窗,生成一组视频片段,输入到Proposal Network中,得到proposal的置信度得分Pprop,保留Pprop>0.7 的片段,将保留的片段通过Localization Network,得到动作类别及置信度Ploc,基于Ploc进行NMS去冗余检测。














 32万+
32万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









