







最近两个多月在实习,做的是GPS定位相关的一些工作,同时也简单做了一下组合导航。卡尔曼滤波是组合不同传感器比较核心的算法,应用也比较广泛,也有很多文章对其进行了详细的介绍,这里记录一下自己的一些理解。
优秀的博客推荐
这里必须要分享一篇博客,在我了解卡尔曼滤波的开始,看过很多上来就给你列出一堆公式或者说一堆让你看不懂的教材或者文章,让人从入门到放弃。但是这篇博客写的非常浅显易懂,可以说让我耳目一新,不得不佩服作者的写作风格,原文链接:How a Kalman filter works, in pictures
里面的语言也很通俗,遇到看不懂的用翻译软件翻译一下也完全够了。
直观理解
简单以上面博客的内容举个例子。假设小机器人在一维方向需要估计自己走了多远。现在有两类数据:
- 在起点有一个仪器,可以测量现在的位置距离起点有多远
- 同时可以小机器人可以给出自己的速度信息
由此,首先小机器人已知
- 传感器测量的离起点的距离(称之为观测值,比如雷达直接测量机器人离障碍物距离7m)
- 上个时刻机器人离起点距离
- 自己当前时刻的速度
而根据 上个时刻机器人离起点距离 和 自己当前时刻的速度 可以估算出当前机器人离起点的距离(称之为估计值)。例如:上一秒离起点2m,速度是4m/s,那么现在这秒估计就离起点距离是6m。但是这个时刻传感器测量的离起点的距离是7m。
那么问题来了,机器人离起点的距离现在既有个观测值7m,又有个估计值6m。到底相信哪个?单纯相信观测值万一那传感器坏了呢?单纯相信估计值那么万一上个时刻的距离估计值或者速度不准呢?所以,我们要根据观测值和估计值的准确度来得到最终机器人离起点的距离估计值。准确度高的就最终结果比重高,准确度低就占比低。
如果雷达测量的那个7m准确度是90%,根据速度估计出的那个6m准确度是80%,那么最终的距离估计结果就是 **0.8/(0.8+0.9)6+0.9/(0.8+0.9)7=6.52米。
事实上,0.9/(0.8+0.9) 就是所谓的卡尔曼增益,它就是表示这个传感器数据相对于根据速度计算出的估计值的靠谱程度。(每个传感器在使用前都可以对它的噪声的方差进行测量,比如IMU有对应的Allen方差)
卡尔曼滤波核心算法
重复的我也不多说了,根据上面的博客我们可以得到卡尔曼滤波的五个核心公式:
(以下公式截图均来自于i2Nav实验室的组合导航课程讲义)
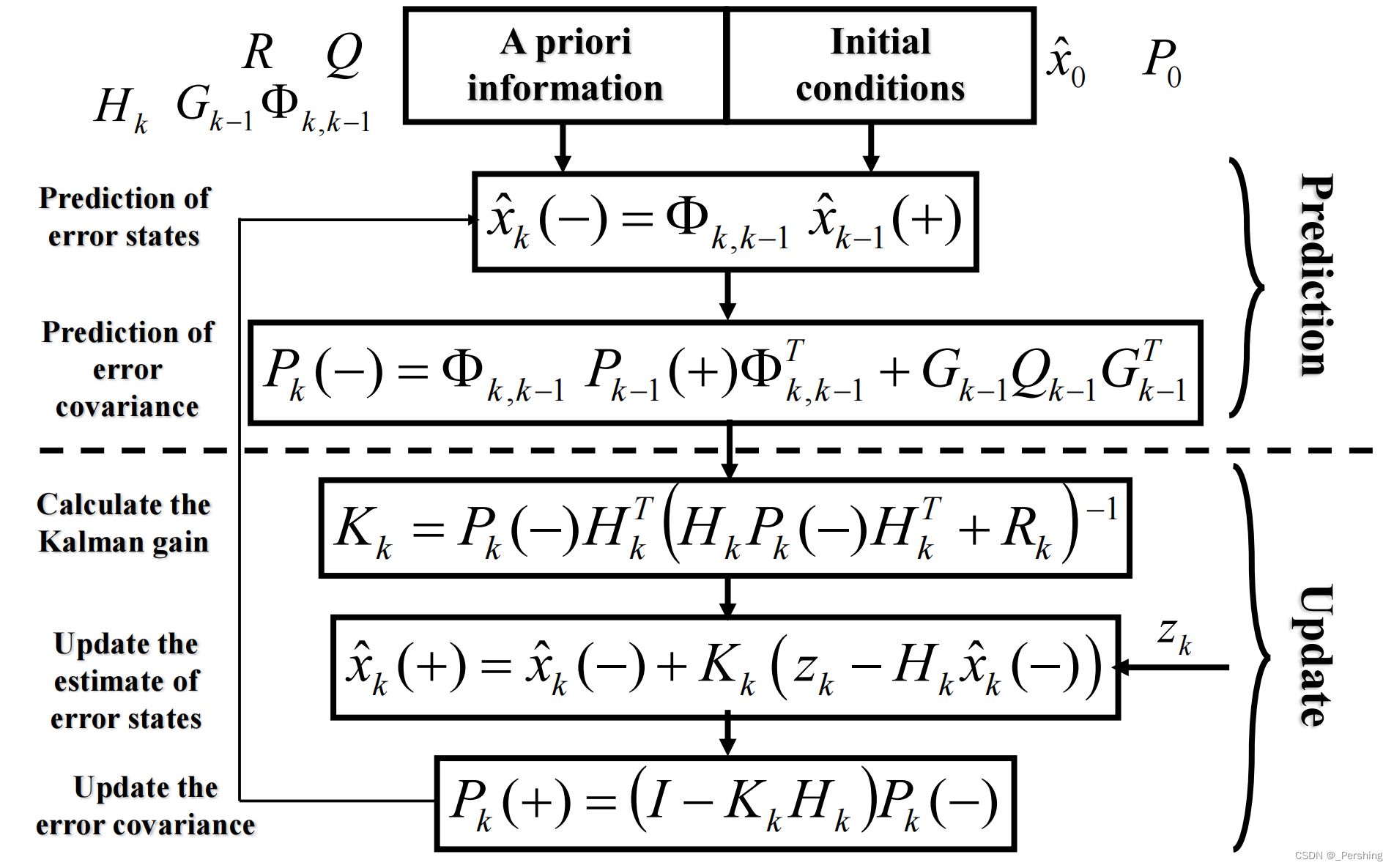
- 思路就像把上述的简单的值变成了一个矩阵, x ^ \hat x x^是状态向量 , ϕ \phi ϕ是状态转移矩阵,例如是运动方程的参数,因此第一个公式利用上一个时刻的状态向量 x ^ k − 1 ( + ) \hat x_{k-1}(+) x^k−1(+)乘上 k − 1 k-1 k−1 到 k k k 状态的状态转移矩阵就可以得到这个时刻的状态向量预测值 x ^ k ( − ) \hat x_k(-) x^k(−),为什么是预测值呢?因为是用状态转移矩阵直接乘出来了,没有加任何的观测约束。所以下一步就是要进行观测值对状态的更新修正。注意到更新之前还需要把状态向量对应的协方差矩阵也更新了,协方差在更新的时候需要主要误差的引入。这样第一步的预测过程就完成了。
- 在利用观测值更新的时候首先要计算卡尔曼增益 K k K_k Kk,卡尔曼增益即权重,决定了下一步哪个传感器的权重大哪个小,推到过程需要用正太分布的特性去计算,具体计算过程可以参考这篇博客:卡尔曼增益推导
- 卡尔曼增益计算完后对状态向量进行更新,注意到后面的括号中是
z
k
−
H
k
x
^
k
(
−
)
z_k-H_k\hat x_k(-)
zk−Hkx^k(−),其中
z
k
z_k
zk是观测值,
H
k
H_k
Hk是观测矩阵,
x
^
k
(
−
)
\hat x_k(-)
x^k(−)是状态向量预测值,那观测矩阵乘以状态向量预测值应该得到什么呢?没错,就是预测的观测值,因此这一步实际是用真实的观测值减去预测的观测值,求出之间的差值再乘以卡尔曼增益。
- 假设 K k K_k Kk很大, K k H k x ^ k ( − ) K_kH_k\hat x_k(-) KkHkx^k(−)与 x ^ k ( − ) \hat x_k(-) x^k(−)基本消去, x ^ k ( + ) ≈ Z k \hat x_k(+) \approx Z_k x^k(+)≈Zk
- 假设 K k K_k Kk很小,后面与等于0, x ^ k ( + ) ≈ x ^ k ( − ) \hat x_k(+) \approx \hat x_k(-) x^k(+)≈x^k(−)
- 因此可以看出卡尔曼增益就是起到该相信那部分数据的作用
- 最后再根据卡尔曼增益更新误差协方差矩阵 P k P_k Pk,显然 ( I − K k H k ) < I (I-K_kH_k)<I (I−KkHk)<I,所以 P k ( + ) < P k ( − ) P_k(+)<P_k(-) Pk(+)<Pk(−),这表明经过一次滤波,融合观测值信息会降低误差,而降低多少,就得看观测值起到的作用有多大了。
- 这样一直的循环修正,一个迭代的过程。
一些想法
之前有人问我为什么单点定位SPP中不使用卡尔曼滤波递推,因为实际SPP在解算的时候是采用单历元时间内多颗卫星的伪距观测构建观测方程采用最小二乘求解,并且很多误差不需要考虑的。那简要分析一下原因:
根据上面的原理,卡尔曼滤波中主要是根据量测更新和一步预测两步递推实现,其中预测很理所当然的想法就是你需要根据这个历元的数据来推测下一个历元的数据,因此需要连续的历元具有可推性,也即需要有相关的量在历元间有强约束,这样才能在使用卡尔曼滤波中的预测来提供权重,否则就是单纯的量测跟新过程,完全采用观测值的数据与不使用滤波没有任何的区别。
而SPP的观测方程中,由于只采用伪距观测,并且很多误差都是不考虑的,这就导致了每个历元的观测中,观测方程的相关性非常差,没有有效的变量能在历元间构成约束效果,因此使用卡尔曼滤波的效果非常有限,相比微弱的提升,伪距测量自带的误差本身就很大了,没有必要对其进行更精细的改正。
举个例子
卡尔曼滤波中的矩阵,以IMU+GNSS松组合为例,其中IMU是系统的运动估计,GNSS得到的位置坐标作为观测值输入。
常见系统状态含有位置、速度、姿态、传感器误差等是21x1大小的矩阵,常见GNSS测量值包含经度、纬度、高程是3x1大小的矩阵。即状态空间 x ^ \hat x x^是21维,观测空间 z z z 是3维。
-
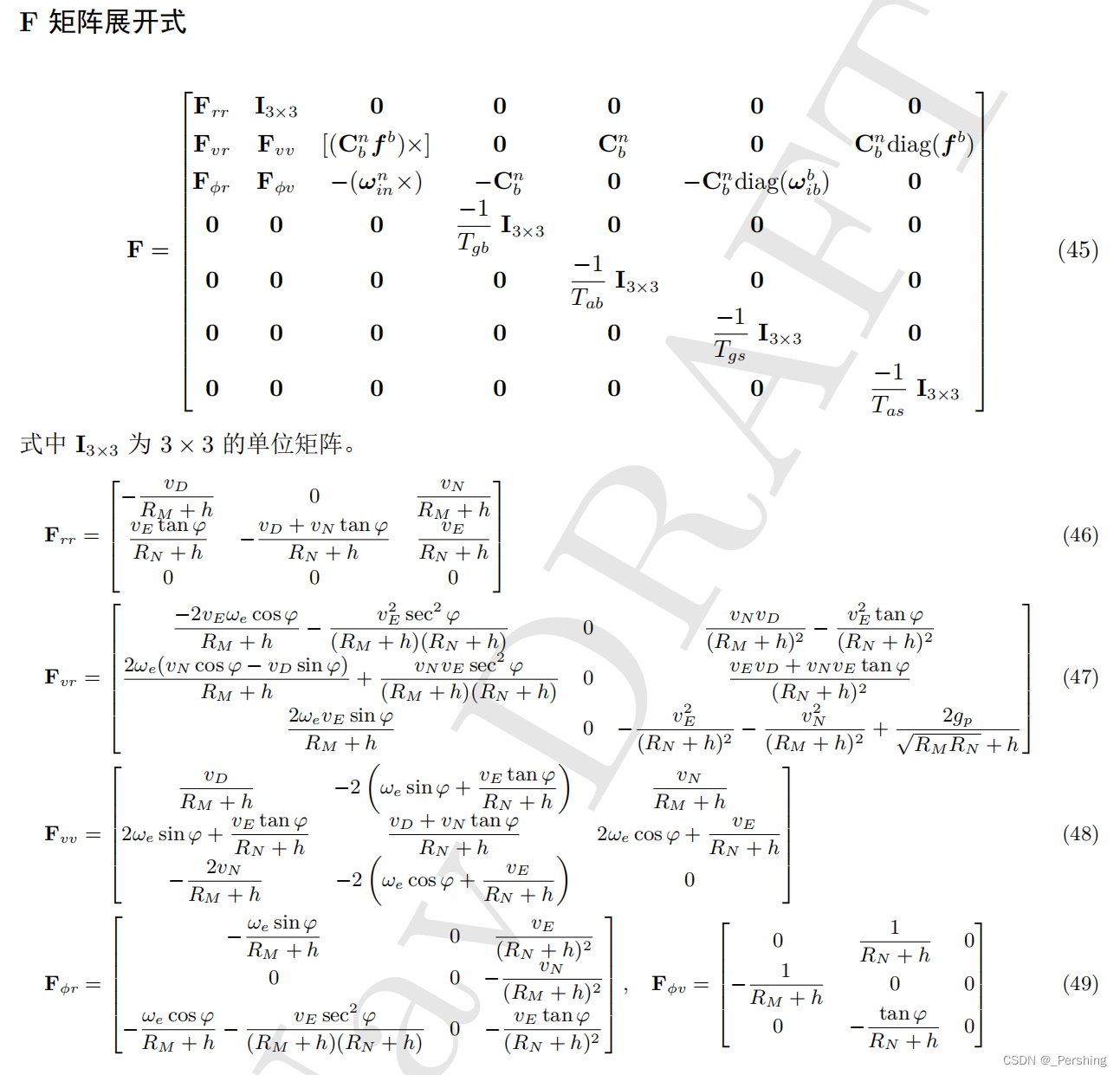
F F F ——状态转移矩阵:根据上一刻状态,进行系统状态预测;大方阵 21x21维
-
H H H——观察矩阵:根据系统状态,胖矩阵,3x21维
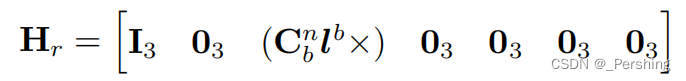
-
K K K——卡尔曼增益,这是一个瘦矩阵,21x3维,直观意义是代表了对观测结果(GNSS)的接受程度,同时,还兼具把观测空间 z z z 转换到 x ^ \hat x x^ 空间的功能。
-
P P P——状态估计矩阵,这是一个大方阵,21x21维
-
Q Q Q——运动噪声矩阵(IMU的噪声),这是一个中型方阵,取决与IMU的噪声模型,比如考虑零偏,随机游走,读数非线性, 3x3(三维)x2(陀螺仪/加计)=18, 则Q阵是18x18维,中方阵
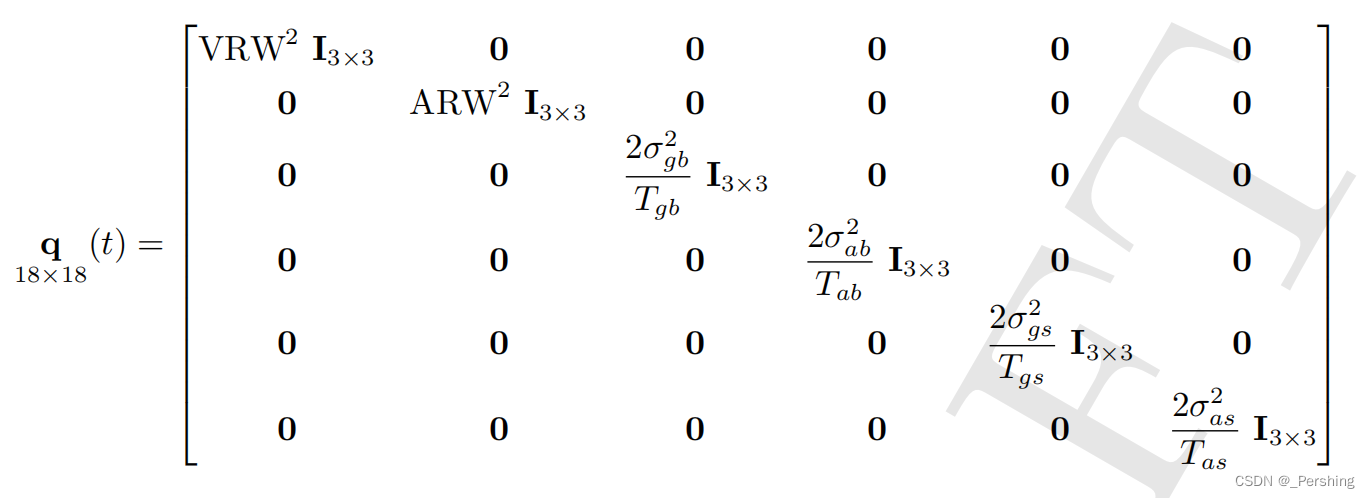
-
R R R——观察噪声矩阵(GNSS的噪声),只考虑经纬高,则是3x3,小方阵
-
G G G——G矩阵,
















 2438
2438











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









