







本文为了解决CNN难以提取有效特征、网络模型参数复杂等问题,提出了一种多尺度融合注意力机制网络MIANet。首先引入Inception结构来图区多尺度特征信息,使用ECA注意力模块加强特征表征能力,使用深度可分离卷积减少网络参数。最终在FER2013和CK+上分别取得72.28%和95.76%的准确率。
1、引言
先分别介绍了ECA注意力模块,深度可分离卷积和Inception结构。这些都是老生常谈的东西,就不详细展开。
2、网络结构
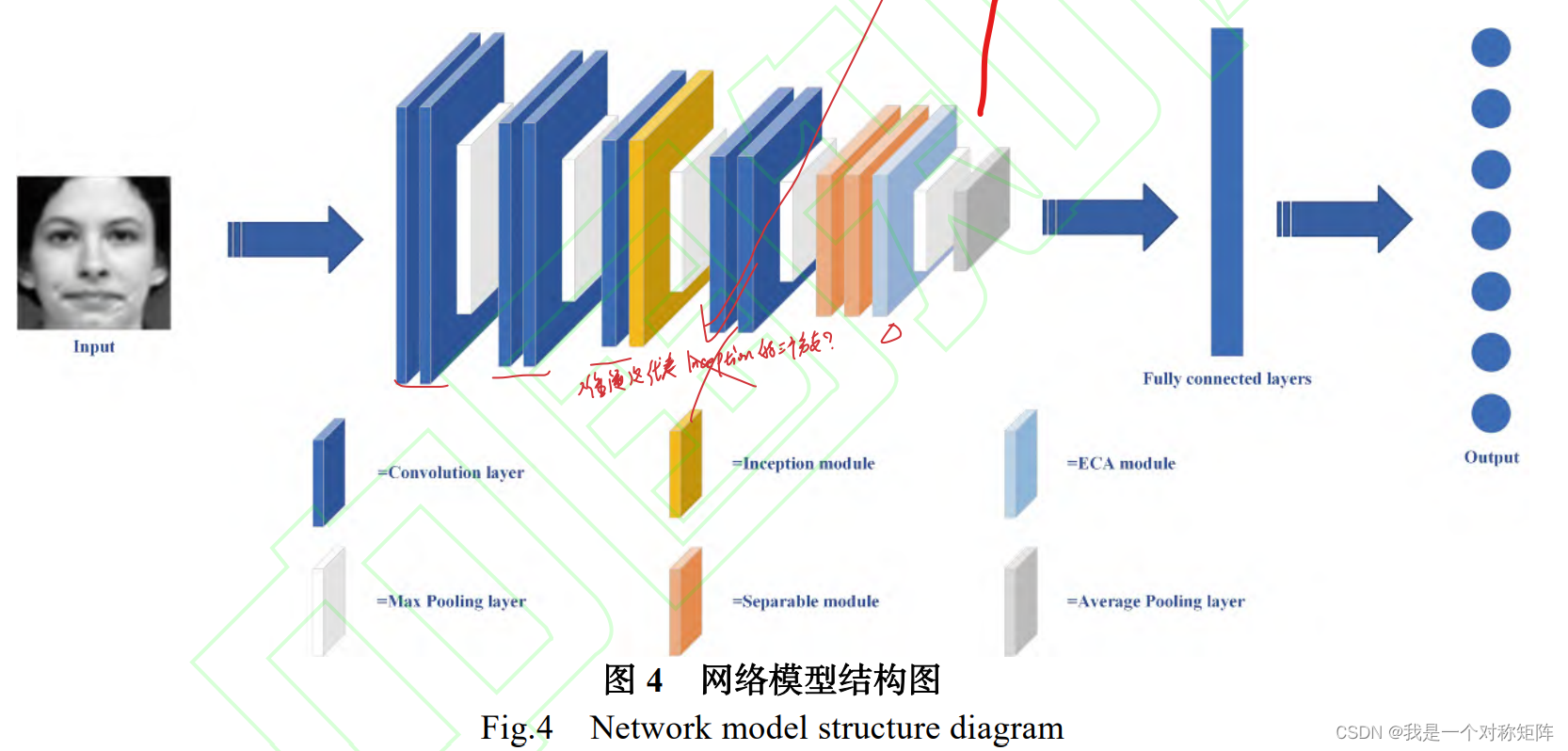
结构也比较简单,但是上面提到的三个模块的位置,我认为是这样的:
- 1、Inception模块位于中间。因为在网络浅层特征还太具体(需要再表征一下),而网络深层又太抽象(已经得到很好的表征,再加Inception的多尺度实际上没有多大意义了,信息的表示已经饱和了)。
- 2、ECA模块。这是通道注意力模块,而网络后期通道很多,能够充分得到应用。(自己在其他实验也发现ECA在尾部的效果更好)
- 3、深度可分离卷积在偏后期。对于普通卷积来讲,因为后期通道多,所以卷积核的深度也高,参数量也大。比如同样ksize=3的卷积,前期输入输出通道=16需要卷积核参数量=331616,而后期输入输出通道=512需要卷积核参数量=33512512,所以对于同大小卷积,通道数越多参数量越大。所以后期的卷积操作参数量很大,对其参数量进行优化会更有效果。

3、实验
3.1 在数据集上的表现
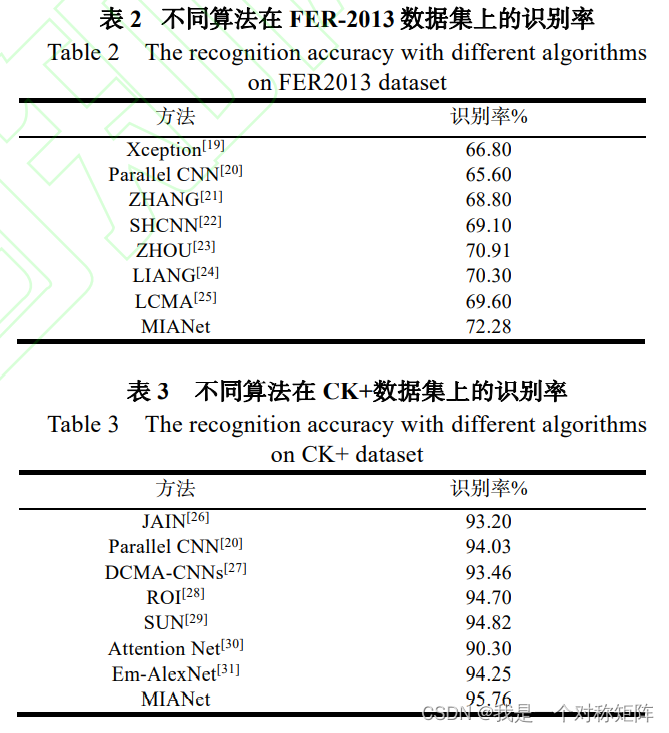
从上图可以看出,MIANet在Fer2013上的效果比CK+上的效果更出众,主要原因是CK+是非常理想的数据集,任意一个普通的网络都能得到较好的效果。但是FER2013是一个困难的大型数据集,MIANet中的Inception多尺度特征提取,在这样的复杂场景下就能获得很好的效果。同时ECA的加入能够在复杂场景下推动网络学习重点特征,保证了特征提取的效果。
3.2 不同注意力模块的效果

(猜测CBAM的空间注意力作用不是很大,因为CK+数据集背景很干净,且就是人脸区域,所以想要更好的空间注意力,应当考虑在人脸中更加关注重点区域的更细致的空间注意力)
3.3 消融实验
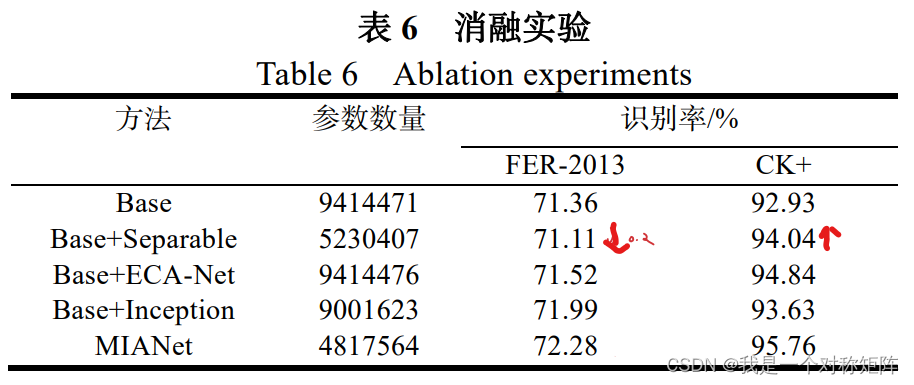
异常现象:
- 1、深度可分离卷积。因为FER2013是一个大型困难数据集,深度可分离卷积的加入相当于降低了网络容量,可能造成欠拟合现象。而CK+就几百张图片,所以其实有可能反而缓解过拟合(或者降低网络容量无影响)。
其余base+module都有提升。
4、总结
本文使用深度可分离卷积、ECA注意力模块和Inception结构来解决有效特征提取和参数量过大的问题。
值得学习的是三种模块在CNN中的插入位置的思考。
5、警告⚠
作者在论文中说的,选出981张图像,那么极有可能是采样同一个序列中最后三张图片

可以看出,最后三张都是很相似的,这3张相似图片就可以很可能分别(如果是随机划分)进入train和test子集,那么很显然,这三张图可以有轻微差别可以看作一张图的数据增强,但是一张图分别存在train和test中,造成数据泄露。
简而言之,三张相似的图即在训练集中训练,又在测试集中测试,这肯定是不对的,实际上我按照981张图片做了实验,最后的精度是100%,虽然当测试集很小时是可能出现100%的,但是在这里100%肯定有以上原因存在。

当然可能作者做了特殊处理,比如让相似的三张图片要么同时存在train中,或者同时存在test中,具体就不可得知了
















 6782
6782











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











