







与传统的注意力机制相比,多尺度注意力机制引入了多个尺度的注意力权重,让模型能够更好地理解和处理复杂数据。
这种机制通过在不同尺度上捕捉输入数据的特征,让模型同时关注局部细节和全局结构,以提高对细节和上下文信息的理解,达到提升模型的表达能力、泛化性、鲁棒性和定位精度,优化资源使用效率的效果。
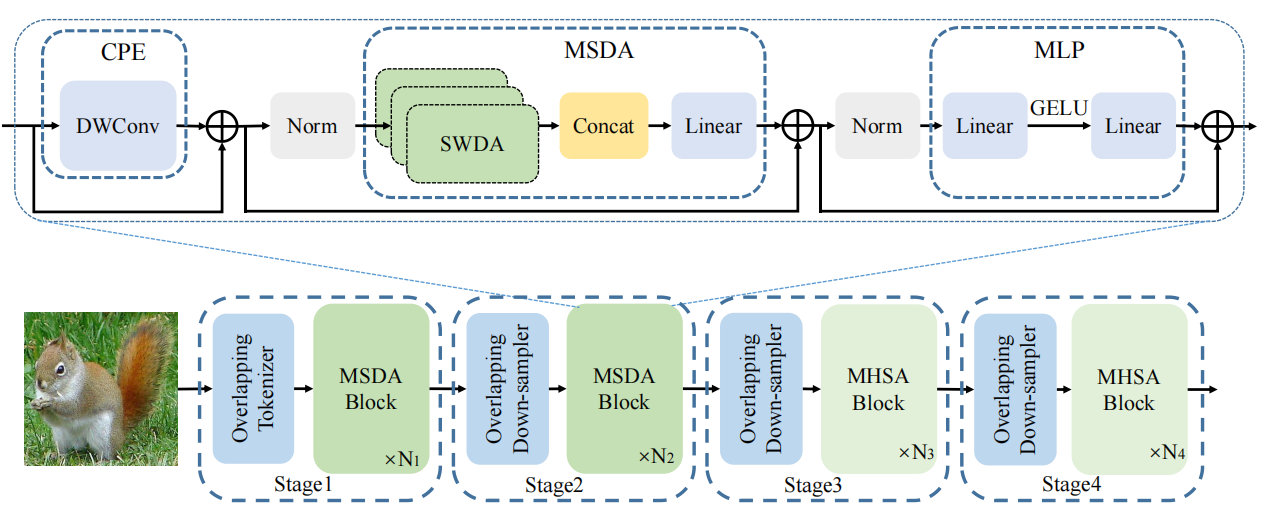
比如发表于TMM2023的MSDA模块,同时考虑了浅层自注意机制的局部性和稀疏性,可以有效地聚合语义多尺度信息,仅用70%更少的FLOPs就媲美现有SOTA。
为方便各位理解和运用,今天分享17种多尺度注意力创新方案,原文和开源代码都有。论文可参考创新点做了简单提炼,具体工作细节可阅读原文。
论文原文以及开源代码需要的同学看文末
EfficientViT: Multi-Scale Linear Attention for High-Resolution Dense Prediction
方法:论文研究了高分辨率密集预测的高效架构设计。我们引入了一个轻量级的多尺度注意力模块,通过轻量级和硬件高效的操作实现了全局感受野和多尺度学习,从而在各种硬件设备上显著加速而不损失性能。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 466
466

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









