







深度学习框架种类繁多,想实现任意框架之间的模型转换是一件困难的事情。但现在有一个中间格式ONNX,任何框架模型都支持转为ONNX,然后也支持从ONNX转为自身框架,那么每一种框架都只需维护如何ONNX进行转换即可,大大降低了维护成本,也给使用的开发者带来遍历。
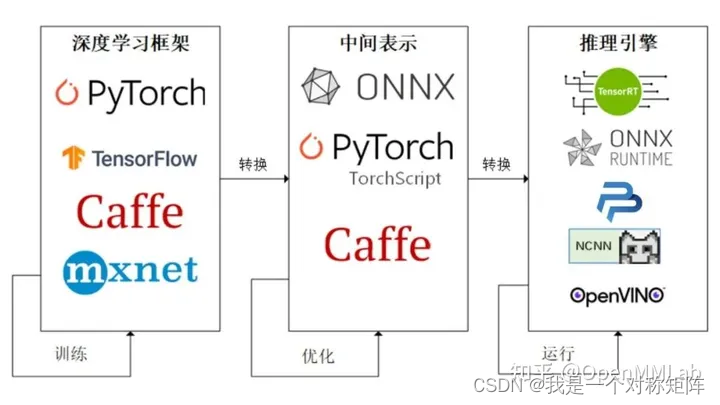
如图所示,中间件不止一种,但是ONNX是使用最广泛的一种。需要注意的是,中间件只是一个描述格式,比如resnet18.onnx这个从pytorch导出的onnx中间件中描述了每一个算子的属性,算子中的权重数值,算子之间的运算图。我们需要一个引擎或框架转为自身特定的格式后,再使用推理功能进行推理。(类似一张jpeg图片在电脑中只是一串数值,必须借用图片解析工具如照片浏览器等软件解析jpeg的数值后才能显示。所以需要区分数据和数据能实现的功能是两回事)
下面我们尝试从pytorch导出resnet18为onnx中间件,然后使用onnxruntime(和onnx不一样,这是一个推理引擎,只不过是专门针对onnx格式的,所以支持直接加载onnx模型推理。如果使用tensorrt推理引擎,则需要将onnx转为tensrort支持的格式后再加载推理)进行推理,并检查使用pytorch推理的结果和onnxruntime推理的结果之间的差异有多大。
1、pytorch导出onnx模型
1.1 使用yolo自带脚本导出onnx
以ultralytics/yolov5为例,根目录下有export.py脚本,我们可以使用下面的命令导出onnx模型:
python export.py --imgsz 1024 --weights runs/train/project1/weights/best.pt --include onnx
上述参数指定了输入图像尺寸,权重位置以及导出类型。其中权重位置就是使用yolov5训练的模型权重。
执行后会在权重文件同级目录下产生onnx权重。
1.2 自己写导出的代码
当然,对于自定义的模型也可以自己手动导出。
自己导出onnx,首先需要安装onnx库:
pip install onnx
pytorch提供了对onnx的支持,现在让我们尝试将pytorch的resnet18导出为onnx模型。
import torch
import torchvision
# 创建一个符合输入shape的假数据
dummy_input = torch.rand(1, 3, 224, 224, dtype=torch.float32, device="cuda:0")
resnet18 = torchvision.models.resnet18(weights=torchvision.models.ResNet18_Weights.IMAGENET1K_V1).cuda()
input_names = ["input:0"] # 给输入节点取个名字,会伴随后续流程,方面我们定位输入节点
output_names = ["output:0"] # 同上
export_path = "resnet18.onnx" # 保存路径
# 导出
with torch.no_grad():
torch.onnx.export(model=resnet18,
args=dummy_input,
f=export_path,
opset_version=11,
verbose=True,
input_names=input_names,
output_names=output_names)
在使用export函数时,我们手动定义了一个假数据,其shape和resnet18要求的输入一致。pytorch转onnx的原理不是通过分析语法进行转换的,而是让pytorch运行一次,然后通过追踪数据流,得到该组输入对应的计算图。 所以就是要给定一个输入,执行一遍模型,把对应的计算图记录下来,保存为onnx格式。export函数就是用的该种追踪方式导出的。(一个问题是如果模型中存在控制流,本次输入走分支1,那就只会记录只有分支1的模型,所以含有控制流的模型不能简单使用这种方法),所以这也就是为什么需要给定一组输入,同时为什么要with torch.no_grad了,因为我们只是追踪计算图而不需要梯度。
初次之外还定义了input_names和output_names,两个都是列表,因为某些模型不止一个输入输出。这里给每一个输入输出定义一个名字,后续我们可以根据名字直接定位到输入输出节点,获取数据。特别的如果想获取中间节点数据,也可以通过其名字定位节点获取数据。
opset_version是定义算子集。ONNX给每一个算子都有一个名字,比如ONNX定义了卷积名字为Conv,其他框架看到Conv开头的数据定义,明白这是一个卷积层, 会使用自身的卷积算子去映射,实现转换。但是深度学习各种算法更新很快,所以ONNX与时俱进会不断新增新的算子,你可以通过Operator Schemas查看到是否有自己想要得算子,以及它出现在那个版本。
1.3 导出具有动态BatchSize的onnx模型
在某些场景中,推理需要多Batch推理,所以需要设置动态BAtch,本文导出onnx时将BatchSize轴设置为动态,即可以接受不同BS的输入。导出代码如下:
from torchvision.models import resnet18
import torch
model=resnet18()
model.eval()
device = 'cuda'
output_onnx = 'resnet18.onnx'
# ------------------------ export -----------------------------
print("==> Exporting model to ONNX format at '{}'".format(output_onnx))
input_names = ['input']
output_names = ['output']
input_tensor = torch.randn(1, 3, 224, 224, device=device)
torch.onnx.export(model.cuda(), input_tensor, output_onnx, export_params=True, verbose=False,
input_names=input_names, output_names=output_names, opset_version=10,
do_constant_folding=True,
dynamic_axes={
'input': {
0: 'batch_size'}, 'output': {
0: 'batch_size'}})
在dynamic_axes参数中设置’inpu’节点的0轴为动态轴,相应的输出的0轴也是动态轴。
转换成功后显示如下:
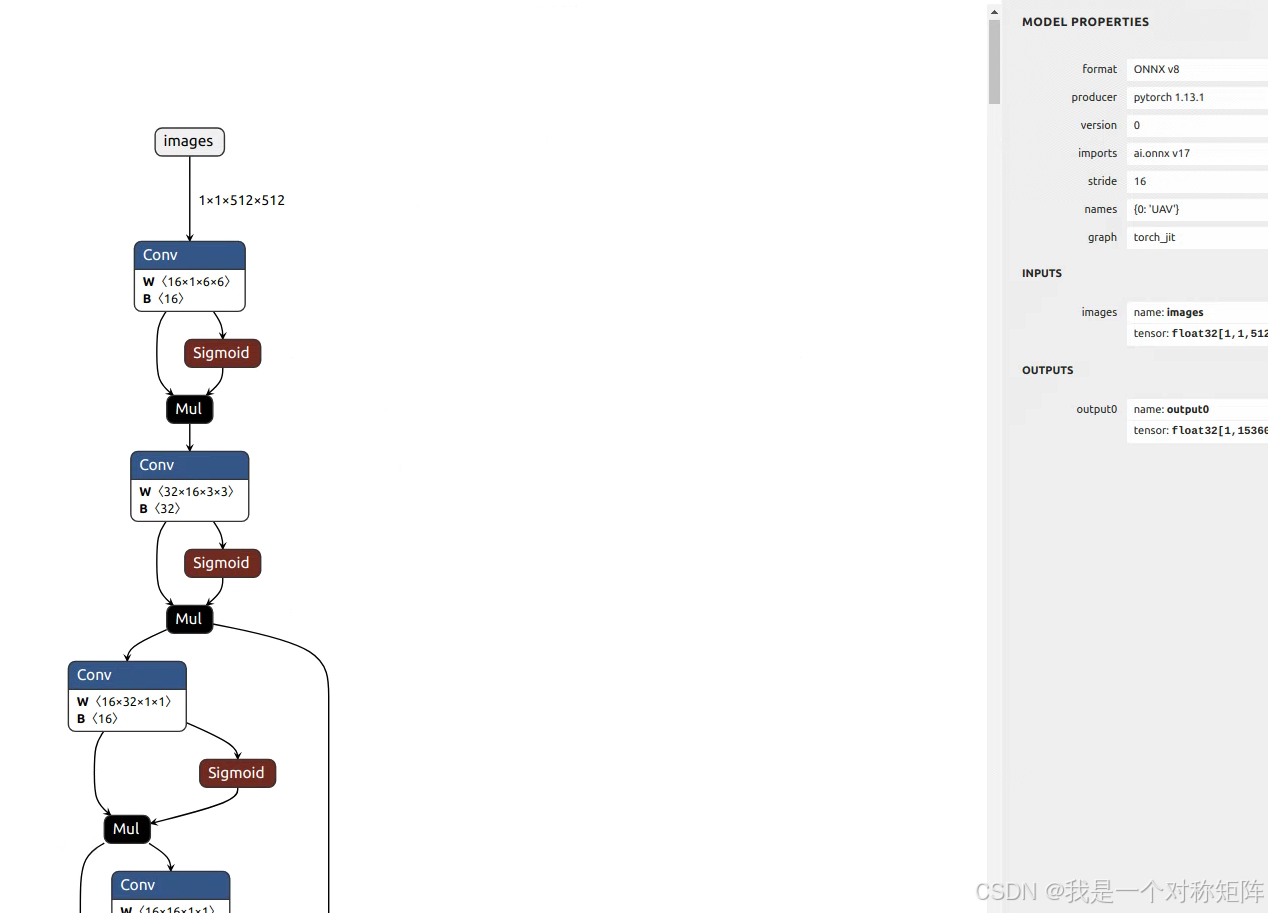
1.4 查看onnx模型结构
你可以使用netron项目打开一个onnx模型,就会得到这个模型的结构可视化。在右侧还可以看到每个节点的相关信息。
1.5 如果想使用onnx模型推理,可以尝试onnxruntime
当我们将pt模型转为onnx模型后,使用onnxruntime引擎进行推理。
首先需要安装推理引擎
Pip install onnxruntime # 支持onnx中间件的推理引擎
完整的推理代码如下:
import cv2
import torchvision
import numpy as np
import onnxruntime
# 获取ImageNet1K的标签
labels = torchvision.models.ResNet18_Weights.IMAGENET1K_V1.value.meta["categories"]
# 使用InferenceSession创建一个引擎以供后续推理,CPUExecutionProvider指定使用CPU
session = onnxruntime.InferenceSession("resnet18.onnx", providers=['CPUExecutionProvider'])
def preprocess(cvimg):
# 将图像大小调整为 (224, 224)
image_resized = cv2.resize(cvimg, (224, 224))
# 将图像转换为 NumPy 数组,并将像素值缩放到 [0, 1]
image_normalized = image_resized / 255.0
# 对图像进行归一化
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
image_normalized = (image_normalized - mean) / std
# 调整图像维度顺序,OpenCV 默认通道顺序为 BGR,而 PyTorch 默认为 RGB
return np.transpose(image_normalized, (2, 0, 1)).astype(np.float32)
img = cv2.imread(img_path)
inp = preprocess(img) # 预处理,得到shape=(3,224,224)的图片
inp = np.expand_dims(inp, axis=0) # 升维得到shape=(1,3,224,224),BS和导出ONNX定义的假数据的BS一致
# run函数用于推理,output_names指明了要获取哪个节点的数据,input_feed使用字典给所有的输入指定输入数据
output = session.run(output_names=["output:0"], input_feed={
"input:0": inp}) # output是列表,其中是节点"output:0"的数据,shape=(1,1000)
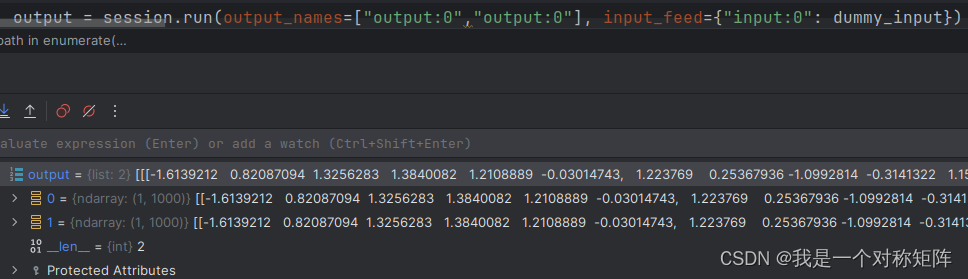
实际上output列表中的一个元素就是一个节点的输出,如下图如果定义两个输出节点,表示我要获取这两个节点的数据。那么output列表长度就是节点数量。
1.6 如何保证pt模型和onnx模型在识别效果上一致?
当我们将pt模型转为onnx模型后,使用onnxruntime引擎进行推理。考虑到1)模型数据转换时存在误差;2)不同框架(pt和onnxruntime)对同一个算子的实现也可能存在差异;3)图像预处理实现方法不同等原因,两种框架的推理结果是有一定差异的。但是只要这个差异在容忍的范围内,都是可以接受的。
下面我们使用numpy模拟一张图片,同时使用pytorch框架和onnxruntime框架对pt模型和onnx模型进行推理,理论上两个模型的输出应该是一样的。
为了简明,使用numpy产生随机数据,然后同时给pytorch(转tensor)和onnxruntime,保证了输入的一致性。我们期望两个框架的输出也应该尽可能的相似。
下面的代码将随机生成20个假数据,然后pt和onnxruntime分别进行运算,并将结果储存在pt_output_array和onnx_output_array,最后计算这两个结果集的差异。
import torch
import torchvision
import numpy as np
import onnxruntime
resnet18 = torchvision.models.resnet18(weights=torchvision.models.ResNet18_Weights.IMAGENET1K_V1)
labels = torchvision.models.ResNet18_Weights.IMAGENET1K_V1.value.meta["categories"]
resnet18.eval()
session = onnxruntime.InferenceSession("resnet18.onnx", providers=['CPUExecutionProvider'])
# 创建ndarray用于储存输入和输出数据
pt_inp_array = np.zeros([20, 1, 3, 224, 224], dtype=np.float32)
onnx_inp_array = np.zeros([20, 1, 3, 224, 224], dtype=np.float32)
pt_output_array = np.zeros([20, 1 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1037
1037

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











