









论文翻译
SCOOP: Self-Supervised Correspondence and Optimization-Based Scene Flow
摘要:
场景流估计是计算机视觉中的一个长期存在的问题,其目标是从连续的观测中发现场景的三维运动。最近,出现了从三维点云计算场景流的努力。一种常见的方法是训练一个回归模型,该模型消耗源点和目标点云并输出每个点的平移向量。另一种方法是同时学习点云之间的点匹配,并对初始对应流进行回归精化。在这两种情况下,学习任务都是非常具有挑战性的,因为流回归是在自由的3D空间中完成的,一个典型的解决方案是诉诸一个大型的注释合成数据集。
我们引入了SCOOP,这是一种新的场景流估计方法,可以在少量数据上学习,而不需要地面真值流监督。与之前的工作不同,我们训练了一个专注于学习点特征表示的纯对应模型,并将流初始化为源点与其软对应的目标点之间的差异。然后,在运行阶段,我们直接优化一个带有自监督目标的流精化组件,从而得到点云之间连贯而精确的流场。在广泛的数据集上的实验表明,与现有的领先技术相比,我们的方法在使用一小部分训练数据时取得了性能上的提升。我们的代码是公开的1 .

图1。在KITTI基准测试集上的流精度与列车集规模的关系。SCOOP在少一到两个数量级的数据上训练,同时在性能上大大超过了竞争方法[ 4、17、18、20、25、29、36、37]。评价设置的完整细节见表1。
1、引言
场景流估计[ 33 ]是计算机视觉中的一个基本问题,涉及自动驾驶、场景解析、姿态估计、目标跟踪等多种应用场景。给定一个三维场景的连续两个观测值,目的是计算观测值之间场景的动态。文献[ 21、23、34、38、39]对基于2D图像的场景流预测进行了深入研究。然而,鉴于最近3D传感器的激增,如LiDAR,对直接在三维数据[ 11、17、20、25、41]上操作的场景流方法的兴趣激增。
Liu等[ 20 ]是最早开展此项研究的学者之一。他们提出了FlowNet3D,这是一个全监督的神经网络,它学习回归三维点云之间的流动,并且比基于图像的技术[ 1 , 23 , 35]有显著的性能改进。由于他们的方法需要地面真值流注记,而真实世界数据很少,他们转而在大型合成数据集上训练,这损害了对真实LiDAR数据的泛化能力。
后续工作设计了自监督学习方案[ 17、25],通过对未标注的LiDAR点云对进行训练,缩小了领域差距。然而,与Liu等[ 20 ]类似,他们使用了一种回归方法,模型应该学会计算自由三维空间中的流动。由于点云的不规则性,这项任务极具挑战性,需要大量的训练数据才能使网络收敛。在另一项工作[ 8、13、29]中,研究人员利用点云对应关系进行场景流预测。在这种方法中,流被计算为第一个点云(源)中的一个点到第二个点云(目标)中的软对应点的平移。软对应点是学习到的潜在空间中基于点相似度的目标点的加权和。因此,与3D环境空间中具有挑战性的回归问题不同,流估计任务归结为点特征学习,并归结为现有目标点的凸组合[ 31 ]空间。然而,为了放松这个约束,训练另一个网络组件来回归流修正。点表示和流细化的联合学习加重了训练过程的负担,并保留了对具有流监督的大数据集的依赖。
另一种新兴的方法是仅优化的流计算[ 19、36]。在这种情况下,不涉及训练数据,在运行时对每个场景单独进行流程优化。尽管这种专门的优化实现了高精度,但它需要较长的处理时间。
我们提出了SCOOP,一种可以从少量训练数据中学习的混合流估计方法。SCOOP由两部分组成:点云对应的自监督神经网络和直接流精化优化模块。在训练阶段,网络学习提取点特征进行软点匹配,初始化点云之间的流。与以前的工作不同,我们的网络专注于学习点嵌入,这使得它可以在非常小的数据集上进行训练,如图1所示。此外,我们在计算的对应关系中考虑网络的置信度,以更好地指导学习过程。
然后,我们定义了一个优化问题,在运行时直接优化残差流细化向量,而不是训练另一个回归流更新的网络。该优化目标在保持平移后的源点靠近目标点云的同时,鼓励形成相干流场。与基于学习的方法相比,我们的设计选择提高了准确性,并减少了仅优化方法[ 19、36]的处理时间。对于对应学习和精化优化,我们使用自监督的距离目标和平滑先验来代替真实流标签。图2展示了我们的方法与领先的先前方法的区别。
综上所述,我们提出了一种基于自监督对应学习和直接运行时残差流优化的点云混合流预测方法。使用场景流文献中的成熟数据集,我们表明我们的方法在使用一小部分训练数据和不使用任何真实流监督的情况下,比现有的最先进的方法有明显的性能提升。
2、相关工作
流回归:点云场景流估计的常用方法是训练流回归模型[ 4、11、20、37、41]。即一个神经网络,计算环境三维空间中点云之间的流向量。Liu等[ 20 ]提出FlowNet3D,将点云编码到一个潜在空间,用流嵌入层混合点特征,通过解码混合点特征回归场景流。FlowNet3D以强监督的方式进行训练,使用与真实流注释相关的l2损失。
Liu等[ 20 ]启发了后续的一系列工作[ 4、17、25、36、37]。Wang等[ 37 ]在FlowNet3D的架构中加入了空间和时间注意力层。在BiPointFlowNet [ 4 ]中,作者从每个点云双向传播特征,增强了点特征表示。Mittal等[ 25 ]利用前向和逆向场景流之间的自监督最近邻损失和周期一致性,舍弃了流监督,Li等[ 17、18]从数据本身提取流标签进行训练。与后面的方法类似,我们在训练方案中也避免了真实流监督。然而,与流回归相比,我们的技术基于场景中的软点匹配,从而简化了流估计问题。
点云对应关系:针对点云[ 7、9、14、42]描述的非刚性形状之间的稠密映射,提出了几种方法。最近,Lang等人[ 14 ]建议使用潜在空间相似性和点坐标本身来构建另一个点云,而不是像以前的[ 9、42]那样回归对应点云。受Lang工作的启发,我们在模型中不使用流回归,将学习过程集中在点特征表示上。然而,虽然Lang等人操作的是具有一一对应关系的完整形状,但我们的方法适用于具有部分物体的场景,其中可能不存在完美匹配。
研究人员对场景流问题也采取了对应的方法。FLOT [ 29 ]计算了一个最优的传输计划,作为点云之间的初始流,并通过一系列学习的卷积进一步回归流细化。我们的工作建立在FLOT的基础上,但在三个主要方面与之不同。首先,我们从训练方案中排除流回归,而是应用直接运行时优化来优化初始的基于对应关系的流。其次,我们利用模型对计算点匹配的置信度来改进点特征学习。第三,我们不使用任何真实流标注,既不用于对应训练,也不用于精化优化,而FLOT依赖于强监督场景流数据。
基于优化的场景流程:Pontes等[ 28 ]提出了一种不涉及学习的场景流估计技术。相反,在运行时对流进行了完全优化,使扭曲的源靠近目标点云,同时要求流尽可能"刚性"。Pontes等人通过最小化定义在源点上的图Laplacian来编码这个先验。在后续工作中[ 19 ],将显式图形替换为神经先验,隐式正则化优化流场。与这些论文不同的是,我们使用学习的对应模型初始化流,并在运行时只优化残差流细化。
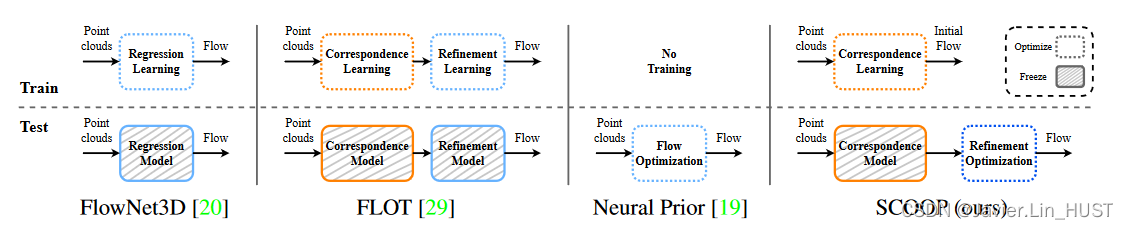
图2。场景流方法的比较。给定一对点云,FlowNet3D [ 20 ]学习回归自由三维空间中的流,并将训练好的模型冻结进行测试。FLOT [ 29 ]同时训练两个网络组件:一个计算点对应关系,另一个对结果对应流进行回归修正。Neural Prior [ 19 ]在没有学习的情况下,从头优化点云之间的流。与之前的工作不同,我们采取混合方法。我们训练一个没有流回归的纯对应模型,该模型为流初始化服务。然后,我们只在测试时直接优化流求精。
3、方法
点云是一组无序的三维点X∈Rn × 3,其中n为点的个数。给定场景的一对点云,记为X,Y∈Rn × 3,分别称为源点和目标点,我们的目标是估计一个描述从X到Y的逐点运动的流场F *∈Rn × 3。
我们通过两个点云之间的自监督软对应学习和直接的流细化优化来解决这个问题。方法概述如图3所示。首先,使用深度神经网络提取点特征。然后,我们在学习到的特征空间中计算点与点之间的匹配代价。基于这个代价,我们求解一个最优运输问题,为每个源点计算一个软匹配的目标点,其中两者的差值被视为基于对应的流。最后,我们通过要求相邻源点之间的一致性来细化流场,并获得我们估计的场景流。在对应学习和流精化中,均不使用真实流标签。以下各小节详细阐述了我们方法的要素。
3.1 匹配代价
将点xi∈X匹配到点yj∈Y的代价是根据深度神经网络学习到的点表示来确定的。该网络消耗原始点云X,Y并计算点特征Φ X,ΦY∈Rn × d,其中d为点特征维数。网络架构基于Point Net + + [ 30 ]。详见补充材料。
受前人工作[ 14、17、29]的启发,我们首先在学习到的特征空间中计算余弦相似度:

其中Φ i X,Φj Y∈Rd分别是Φ X和Φ Y的第i行和第j行.那么,成本设定为

对于欧氏距离小于10米的点,否则都取无穷大来避免点与点之间的流动相隔太远。
3.2 软对应
寻找源和目标点云之间的对应关系可以建模为一个最优传输问题,其中每个源点被分配一个质量为1 n的质量被传输到目标点[ 17、29]。遵循FLOT [ 29 ],我们采用松弛运输问题:

其中Cij≥0是由式( 2 )得到的匹配代价,Tij≥0是点与点之间传输的质量。参数λ≥0控制了问题的松弛性. 1n∈Rn是所有元素都等于1的向量。KL为库尔贝克-莱布勒散度,用于软保持点云之间的传输质量。
方程3中求和运算的第二项是一个熵正则项,它使得Sinkhorn算法[ 5、6]能够高效地求解该问题。我们使用该算法从C中估计最优传输矩阵T *来表示点云之间的软对应关系。运输问题的完整推导和Sinkhorn算法的细节在补充材料中给出。
3.3 基于对应的流
我们利用最优传输方案T *计算源点和目标点的对应权重,用于场景流的初始估计。与FLOT [ 29 ]将所有目标点作为每个源点的候选点不同,我们只考虑从源点传输量最大的目标点。这种设计选择将我们的流量估计方法集中在最相关的候选目标上,并改善了方法的结果。
对于点xi∈X,匹配权重的计算如下:

其中NY ( xi )是包含顶质量输运T * ij的{ yj }点的ks指标的邻域.软对应点( yxi to xi )为:

而点xi的初始估计流为:

注意到如果我们定义 T ij = wij,j∈NY ( xi ),否则为0,我们得到初始流场为:

式中:Y∈Rn × 3包含点{ ( yxi ) }。

图3。所提方法。SCOOP包括两个组成部分:学习到的点云对应模型和流精化模块。该模型学习深度点嵌入Φ X,Φ Y,在潜在特征空间中基于匹配代价C建立软点匹配。从训练阶段开始的初始流F是软对应点云Δ Y与源点云X的差值,在测试时,我们冻结训练好的模型,并优化一个残差流精化R *,以产生点云之间平滑一致的场景流F *。
3.4 训练目标
为了学习适用于没有真值监督的场景流的点表示,我们应用了流动损失项。首先,对于一个易于处理的流估计,我们希望每个软对应点( yxi有一个附近的目标点yj。它可以通过最近邻距离项来实现,正如Mittal等[ 25 ]所做的:

然而,源点的对应质量会有所不同。例如,平坦区域上的点会比具有几何唯一性特征的点有更少的独特对应关系。因此,我们用每个点的匹配置信度来增加方程8中的距离项。
置信度的度量是基于我们定义的对应相似度:

sxi的取值在[ -1 , 1]范围内。为了得到一个介于0和1之间的置信值,我们对负值进行了修剪,将xi的匹配置信度设为pxi = max( sxi , 0)。然后,我们使用pxi来定义我们的置信度感知距离损失:

损失项Ldist可以通过最小化pxi或( yxi与其最近邻yj∈Y之间的距离来最小化。为了避免对所有xi∈X都有pxi = 0的退化解,我们加入了一个置信度损失项:
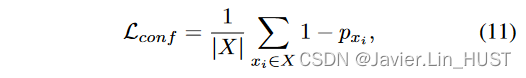
从而惩罚退化解。
此外,为了保持源点云的几何结构,我们希望流场是光滑的。即相邻的源点应该具有相似的流量预测。因此,我们对学习过程进行正则化处理,使其具有流畅性损失[ 13 ]:

其中NX ( xi )是xi在X \ xi中的欧氏邻域,大小为kf .总体训练目标是:

其中α conf和α flow是超参数,平衡了不同损失项的贡献。

图4。流量细化目标示意图。初始流{ fi }源于源点{ xi } (红色)到其软对应的{ ( yxi } (品红)的平移。通过一个保持平移点与目标点{ yj } (绿色)接近的距离损失和一个鼓励相邻点具有相似流向量(虚紫色)的平滑损失来优化流。优化过程产生的流场{ f * i } (蓝色)保留了源点云的结构,并使其接近目标点云的隐式曲面。
3.5 流细化优化
基于对应的流程(见公式7 )的优点是软匹配点位于目标场景中物体表面附近。然而,它限制了目标点云中点的流向凸包[ 31 ]。我们通过一个流精化优化步骤使流在运行时偏离这个约束。
我们不像Puy等[ 29 ]那样训练额外的神经网络部分来回归流校正,而是直接使用公式10和12中定义的自监督距离和平滑损失来优化一个流精化组件R *∈Rn × 3。这些损失的说明如图4所示。
针对流细化的优化问题采取的形式:

其中ri∈R为点xi的流精化,精化后的场景流为F * = F + R *。我们的流精化模块进一步保留了源点云的结构,其中目标点{ yj }被用作锚点来引导精化流并保持与底层目标表面的接近。
4、实验
在本节中,我们使用广泛分布的数据集评估SCOOP的性能,并将其与当前最先进的( SOTA )场景流估计工作进行比较。此外,我们展示了流精化模块的影响,分析了性能和运行时间,并通过消融研究验证了我们的设计选择。
4.1 实验设置
数据集:我们采用了场景流文献中常见的两个数据集,FlyingThings3D [ 22 ]和KITTI [ 23、24]。最初,这些基准不包括点云数据。Liu等[ 20 ]将其处理为点云格式,分别记为FT3Do和KITTIo。
FT3Do是一个大规模的合成数据集,包含来自ShapeNet集合的18,000 / 2,000个随机移动对象的训练/验证场景示例[ 3 ]。每个实例包含一对点云和真实流向量。由于物体的运动是随机的,它们可能从场景的视图中出现或消失并产生遮挡。该数据集还包括了针对由于遮挡导致流无效的点的掩膜。
KITTIo数据集包含150个真实的LiDAR场景。每个场景包括源点和目标点云,并对源点进行流注释。地面点被移除,源点被认为具有有效流[ 20 ]。Mittal等[ 25 ]进一步将KITTIo拆分为100个和50个示例的集合,分别标记为KITTIv和KITTIt,用于微调实验。Li等人[ 17 ]也在真实数据上构建了一个用于自监督学习的大规模无标签LiDAR数据集。他们从KITTI场景[ 23、24]中获取原始LiDAR扫描,与KITTIo数据不相交,创建了一个6,068个实例的训练集,记为KITTIr。
我们注意到还有Gu等[ 11 ]制作的FlyingThings3D和KITTI数据集的另一个点云版本,其中舍弃了所有的遮挡点。在这里,我们关注Liu等[ 20 ]准备的更真实的数据。尽管如此,为了进行综合评价,我们在补充部分报告了Gu等人的版本结果。
评价指标:我们采用前人工作[ 20、25、29]:End-Point Error EP E [ m ] [ m ]、严格精度AS [ % ]、松弛精度AR [ % ]和异常值剔除[ % ]。这些度量是基于点位误差ei和相对误差erel i:
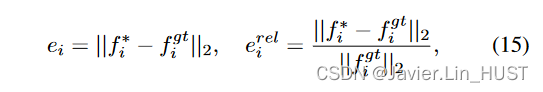
其中,f * i和fgti分别为点xi的预测流量和真实流量. EP E为平均点位误差,以米为单位;AS为ei < 0.05 [ m ]或erel i < 5 %的点的父代;AR为ei < 0.1 [ m ]或erel i < 10 %的点的父代;和Out .为ei > 0.3 [ m ]或erel i > 10 %的点的父代。
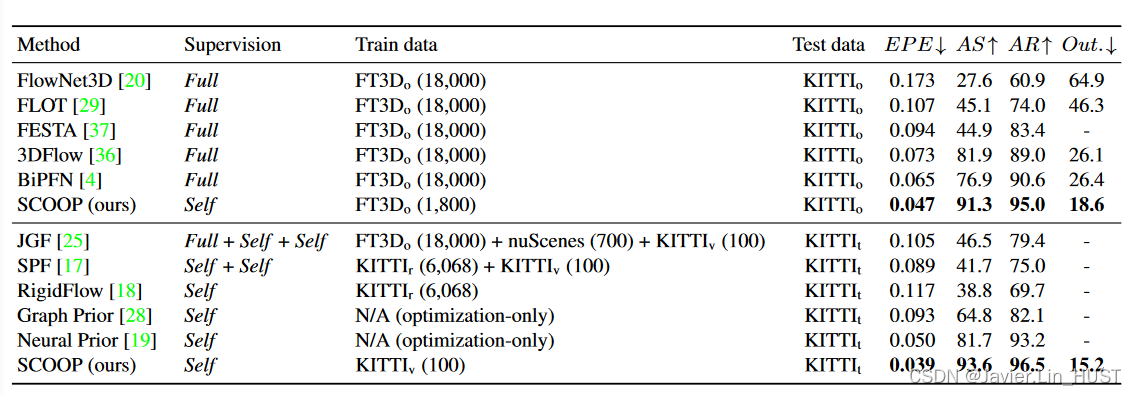
表1。定量比较。我们比较了不同监督设置、训练数据和测试数据的场景流评价指标。括号中标明了训练样本的数量。EPE、AS、AR和Out .分别表示端点误差、严格精度、松弛精度和异常值。它们的定义见4.1小节。当其他基线使用强监督训练时,我们的方法在不使用真实流标签的情况下获得了更好的性能。此外,SCOOP能只在KITTIv上进行训练,训练实例少至100个。相比之下,基于替代学习的方法使用额外的训练数据,如nuScenes,或者使用一个大数据集,如KITTIr。请参见4.2小节中关于监督和数据集的更多细节。
实施细节。SCOOP在PyTorch [ 27 ]中实现,其中公开可用的PointNet + + [ 30 ]实现适用于我们的点特征嵌入。模型在n = 2048个点上进行训练,从场景实例的源点和目标点云中随机采样,仅将点的三维坐标作为模型的输入。方程3中的参数和λ被定义为可学习变量,并作为学习过程的一部分进行优化。点特征维数d = 128。对于邻域大小我们取ks = 64,kf = 32;损失超参数分别设置为α conf = 0.1,αflow = 10。补充部分提供了更多的实施细节。
基线方法。我们的方法与最近的方法FlowNet3D [ 20 ]、FLOT [ 29 ]、FESTA [ 37 ]、3DFlow [ 36 ]和BiPFN [ 4 ]进行了对比。这些方法需要地面真相流监测。此外,我们还将我们的结果与最近Mittal等[ 25 ]和Li等[ 17、18]的自监督流模型,以及基于优化的技术Graph Prior [ 28 ]和Neural Prior [ 19 ]进行了比较。

图5。针对KITTIo示例场景进行场景流结果的可视化对比。训练在FT3Do数据集上完成。源点和目标点云分别以红色和绿色显示。FLOT [ 29 ] (左)和本文方法(右)的扭曲源点云以蓝色显示。当FLOT结果偏离目标表面时,SCOOP保留了源点云的结构并计算其精确流。
4.2 场景流结果
交叉数据集评价。我们通过在FT3Do上训练和在KITTIo上测试SCOOP的性能来证明SCOOP的泛化能力。表1总结了结果。备选方法[ 4,20,29,36,37]以强监督的方式在FT3Do上进行训练:它们的模型使用真实流信息进行学习,并且使用数据集中提供的掩码将有遮挡流的点排除在训练目标之外。
相反,我们的模型以完全自监督的方式进行训练。我们假设不知道流注释和遮挡掩码,并且在我们的损失中不使用它们。此外,我们只使用了FT3Do中随机选取的1800个实例,而竞争对手使用了全部的18000个场景实例。尽管如此,SCOOP在所有评价指标上都优于对比方法。例如,它比SOTA方法Bi PFN [ 4 ]提高了28 %的EPE度量,将误差从0.065降低到0.047。
Flow Net3D [ 20 ]、FESTA [ 37 ]、3DFlow [ 36 ]和Bi PFN [ 4 ]是基于回归的网络,预测三维环境空间中的流量。模型适应合成训练集的特点,对真实测试数据的泛化性有限。FLOT [ 29 ]利用基于学习的点特征的点云对应关系,缓解了流预测问题。然而,它也共同学习回归一个流校正组件,这增加了点表示学习过程的负担。
另一方面,SCOOP只关注适用于场景流估计的学习点嵌入,以我们的自监督损失为指导。它计算判别性特征,这些特征在FT3Do和KITTIo数据集上很好地传递,并能够计算点云之间的对应流。与FLOT不同,我们将流精化过程委托给测试阶段,直接以自监督的方式进行优化,并超越了它们的流估计性能。
图5给出了FLOT与本文方法结果的可视化对比。FLOT得到的扭曲源点云存在噪声,场景中物体的结构被破坏。相反,SCOOP产生了跨相邻点的相干流场,保持了它们的局部几何形状,准确地预测了场景流。附加的可视化在补充中呈现。
在小数据集上进行训练。由于我们的模型不包含流回归组件,只需要学习点特征,因此可以在非常有限的数据量上进行训练。为了展示这种能力,我们在KITTIv的100个点云对上从头开始训练,并使用KITTIt进行测试。本实验结果见表1
与我们的工作不同,Mittal等[ 25 ]和Li等[ 17、18]的竞争方法基于流回归,需要大量的训练数据。Mittal等人在FT3Do上使用强监督预训练,在KITTIv上微调之前使用额外的室外流量数据集nuScenes [ 2 ]。Li等人[ 17、18]在大型KITTIr集上训练他们的模型。我们的SCOOP优于其他方法,而只在KITTIv上训练,几乎比KITTIr小两个数量级。
纯优化方法[ 19、28]在每个场景中分别寻找解,这可能导致次优的局部极小值。相比之下,我们利用从数据中学习到的对应统计信息,并通过我们的残差运行时优化将初始流适应于手边的场景。初始对应流作为优化阶段的良好起点,与仅优化的备选方案相比,产生更好的最终结果。

图6。流动细化效果。我们展示了KITTIt对数据的影响。源点云为红色,目标为绿色。我们的对应模型在KITTIv数据集上进行训练,其精化前的流量估计如马真塔(左)所示。优化后的细化流程用蓝色(中心)表示。我们还提供了紫色的地面-真相场景流,以供参考(右)。精化后的流更好地覆盖了目标点云(顶端中心椭圆)。它还破坏了给定目标点的凸包,并能够为目标缺失(底部中心椭圆)的源点计算正确的流。
流细化的影响。细化前后的流程结果如图6所示。将SCOOP的学习部分作为对应问题,使其能够在小数据集上进行有效训练。然而,来自训练阶段的流预测局限于现有目标点的线性组合,可能无法代表场景的准确流。此外,源点的错误匹配可能会发生并导致流错误。在这种情况下,我们的求精模块就发挥作用了。
在给定训练好的对应模型输出流的情况下,精化模块根据两个目标优化校正向量:一个扭曲的源点应该接近一个目标点;相邻的源点应该具有相似的流量。这些目标有助于修正流场中的不一致性,提高流动精度。如图6所示,我们的精化步骤改进了初始流估计,得到了与真实场景流类似的精确流场。

图7。KITTIt数据集的流量估计误差与推断时间。SCOOP比纯网络模型具有更低的误差,比纯优化方法具有更短的推理时间。它还允许沿着误差和时间权衡的不同平衡,如蓝色曲线所示。
4.3 性能和时间分析
我们通过记录不同方法的EP E和推理时间来分析图7中的性能-时间权衡。测量是在Nvidia Titan Xp GPU上完成的,用于计算KITTIt数据集的流量。
纯网络方法[ 17、18、25]速度较快,但精度有限。单独优化每个场景的流量预测[ 19 ],EPE较低,但耗时较长。我们的混合方法弥补了这两种方法之间的折衷差距。SCOOP提供了一个比前馈模型误差减少50 %以上的工作点,并且比仅优化的神经网络先验工作快10倍。SCOOP还实现了时间和性能之间的不同平衡,如图7所示。通过减少运行时优化步骤的数量,用户可以缩短推理时间,获得更接近纯网络模型的工作点。

表2 .列车编组尺寸烧蚀。我们使用不同数量的实例在FT3Do数据集上训练SCOOP,并在KITTIo数据集上测量EP E。只有1,800个训练样本的子集足以使我们的技术实现其潜力。
4.4 消融研究
我们方法中的设计选择通过消融实验进行了验证,如表2和表3所示。表2表明10 %的FT3Do数据集足以使SCOOP收敛到其最优性能。在表3中,我们每次改变一个方法元素,其他方法元素保持不变。检查了以下消融设置:( a )使用所有目标点进行软对应,而不是使用具有最高传输量的目标点(公式5 );( b )在方程10中令pxi = 1,在方程13中令α conf = 0,忽略点匹配置信度;( c )从式( 13 )中剔除光滑流损失Lflow;( d )关闭流量细化模块。
消融研究验证了所提组件对方法性能的贡献。考虑目标点对应的子集使模型能够集中于最相关的候选流估计。匹配置信度强调了我们的置信度感知距离损失Ldist中更有信心的点的影响。平滑损失项对于正则化点表示学习以获得跨近邻点的相似特征具有重要意义。最后,我们的流动细化优化提高了流场的一致性,大幅降低了EPE。

表3 .部件消融设置。SCOOP在KITTIv上训练,在KITTIt上评估。结果表明,我们的完整方法获得了最好的性能。关于烧蚀实验的更多细节在4.4小节给出。
5、结论
本文提出了一种基于对应学习和流精化优化的自监督三维点云场景流估计方法SCOOP。以前的工作建议学习流回归模型,训练一个联合学习点云对应关系和流细化的神经网络,或者在运行时完全优化流,而不需要学习。
相比之下,我们将流预测过程拆分为两个更简单的问题。我们的对应模型只专注于学习点特征来初始化点云之间的软匹配流。然后,我们在运行时直接优化一个残差流精化。该方法使得SCOOP能够在不使用地面真值监督的情况下,在一小部分点云场景上进行训练,同时优于现有的强监督和自监督学习方法以及基于优化的替代技术。















 3024
3024











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









