







目录
一、源码包下载
源码包有官网提供的和我自己修改过代码提供的,建议学者直接下载我提供的源码包使用,可以少走很多弯路。
官网源码包下载链接:SAN官网
我提供的源码包获取方法文章末扫码到公众号中回复关键字:超分辨率重建SAN。获取下载链接。
论文地址:论文
我提供的源码包下载并解压后的样子如下:
二、数据集准备
在我提供的源码包中有部分训练集和测试集,位于根目录下的data_data文件夹中。DIV2K训练集官网提供的有900张图像,我提供的源码包中有100张,学者可以自己去官网下载完整版DIV2K数据集,我这里提供主要是想告诉学者训练集目录结构关系,如下:

三、预训练权重文件
预训练权重文件子在源码包中已经提供,存放位置如下,分别有超分2倍,3倍,4倍的预训练权重模型。
四、训练环境
测代码框架必须在低版本的Pytorch中才能运行,安装低版本的Pytorch如果遇到问题,参考我另外一篇博文:_update_worker_pids问题
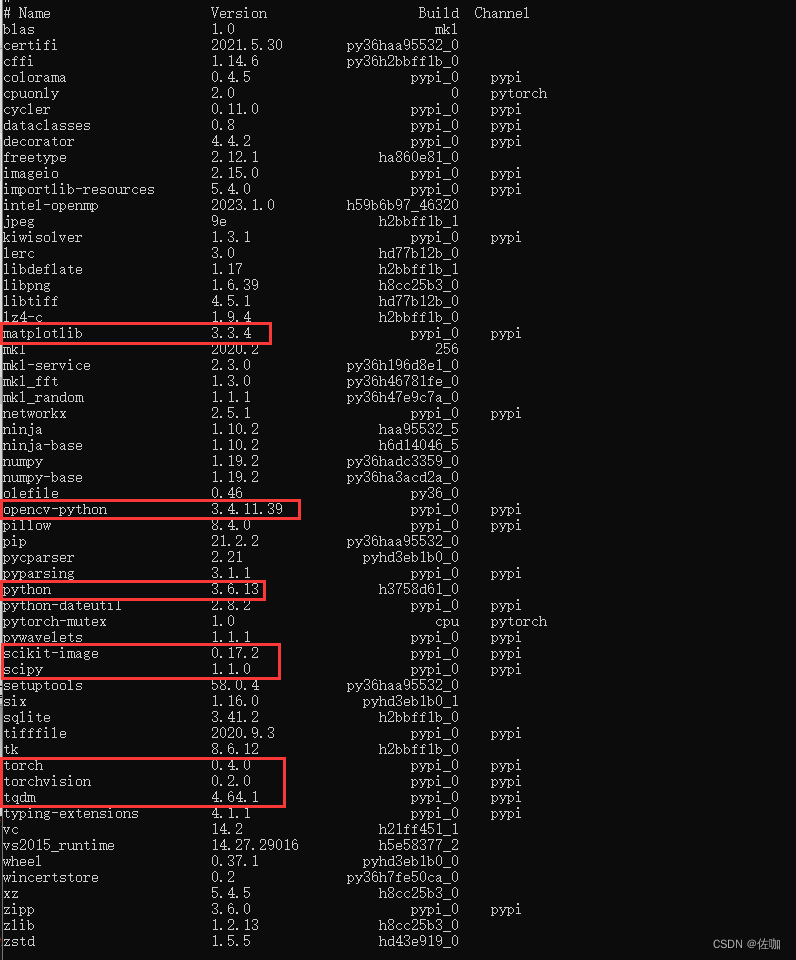
我自己在Windows环境上训练并测试的,运行环境如下:
五、训练
5.1 超参数修改
该代码框架所有的路径都必须用绝对路径才能正确读取数据,不信的倔驴试试!
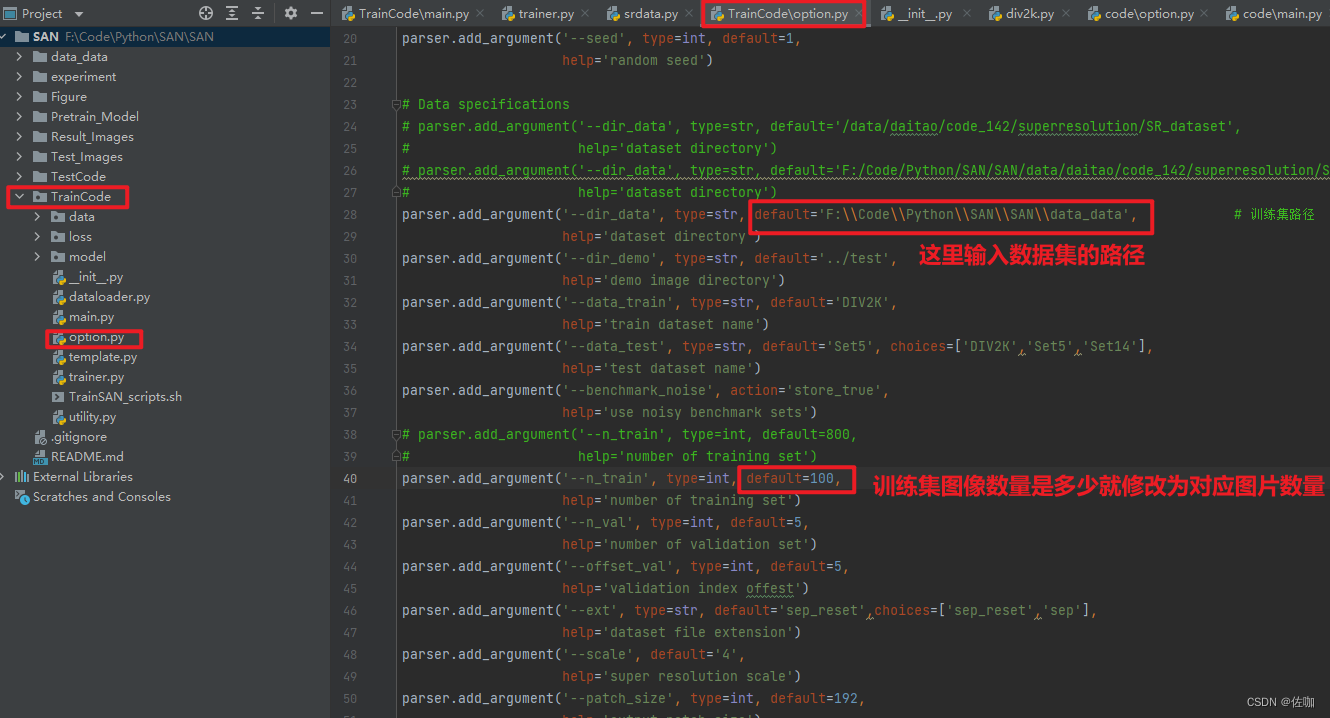
关于训练的所有超参数修改都在TrainCode文件夹下的option.py文件中,学者自行根据自己情况修改其它超参数。
5.2 训练模型
5.2.1 命令方式训练
先在终端通过下面命令进入到训练脚本路径下:
cd TrainCode
在输入下面命令进行训练:
python main.py --model san --save save_name --scale 2 --n_resgroups 20 --n_resblocks 10 --n_feats 64 --reset --chop --save_results --patch_size 20 --cpu --batch_size 8
5.2.2 Configuration配置参数方式训练
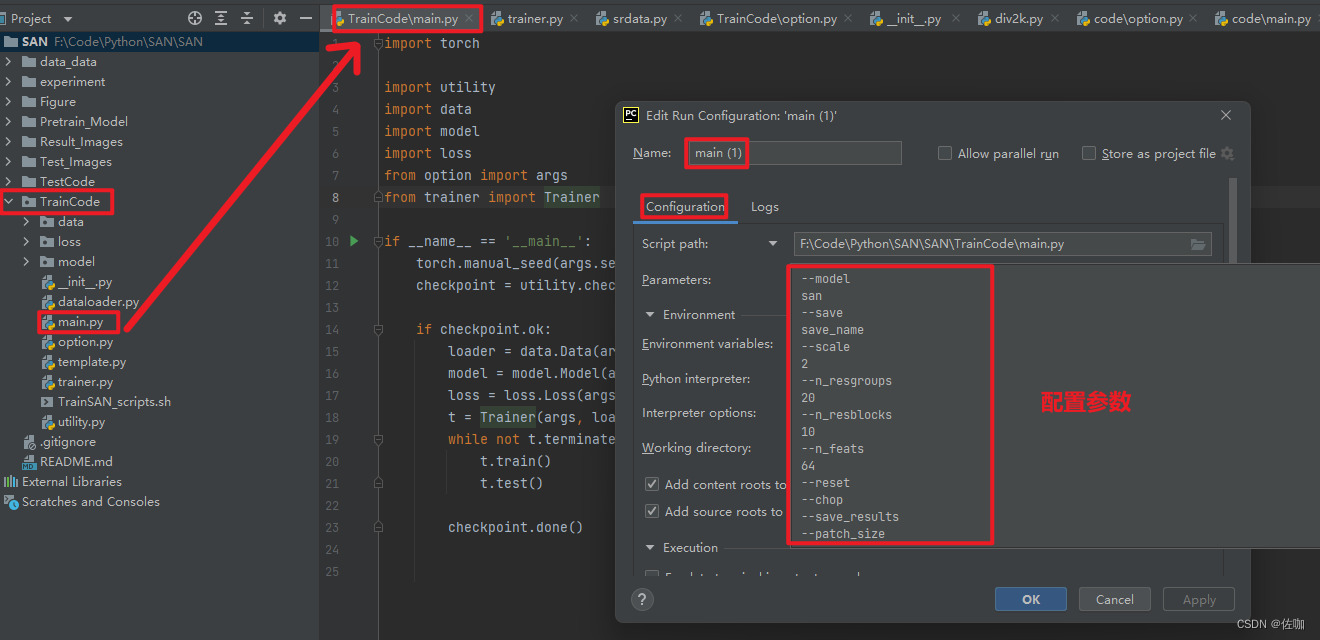
上面两种填写配置参数的方式都可以训练,学者根据个人喜好选择。
配置参数填写好后就可以直接训练了,我自己是在CPU上训练的,因为Pytorch版本太低,牵连到CUDA和CuDNN版本不兼容的问题,要重新配置环境等问题,我懒得折腾了,就直接用CPU训练测试了,学者根据自己情况使用GPU或者CPU,如果要用GPU,把我提供的源码包main.py脚本中的代码注释了,如下:

5.3 模型保存
运行上面命令后,等待一段时间就开始训练了,如下:
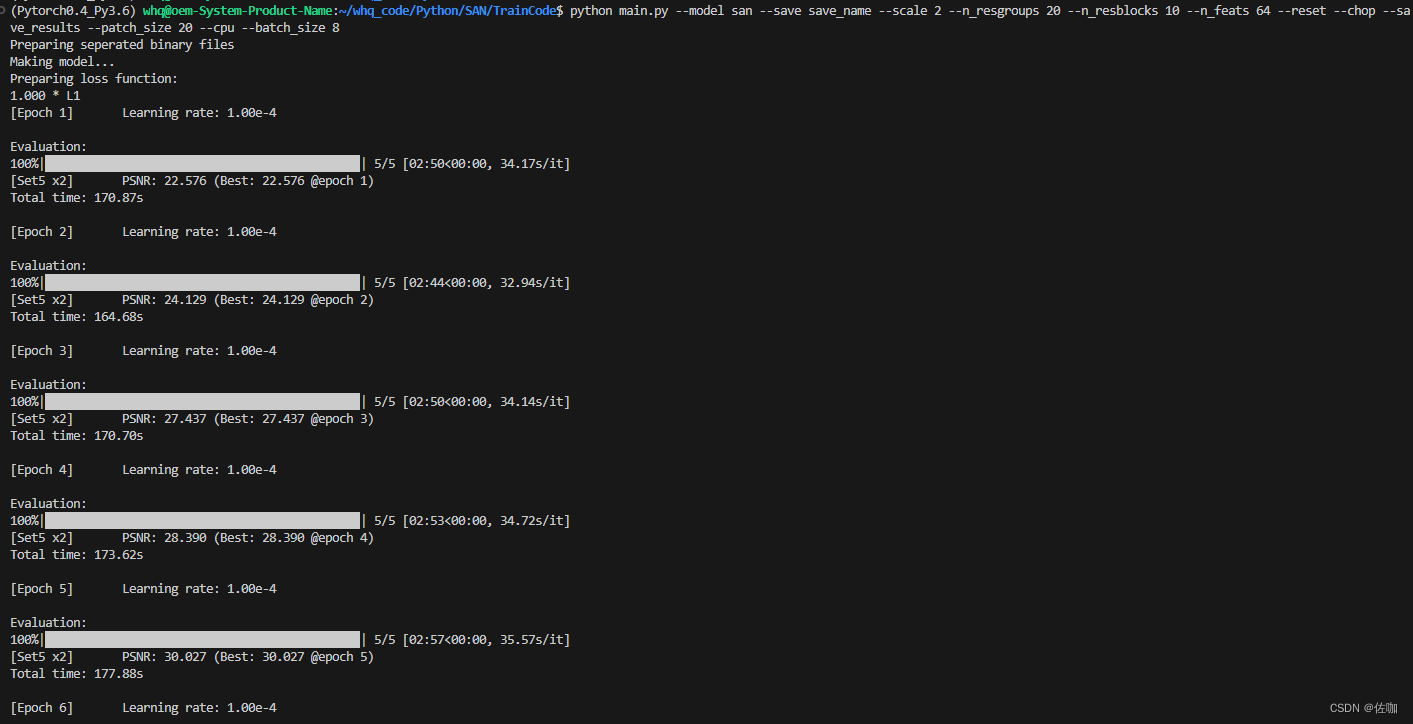
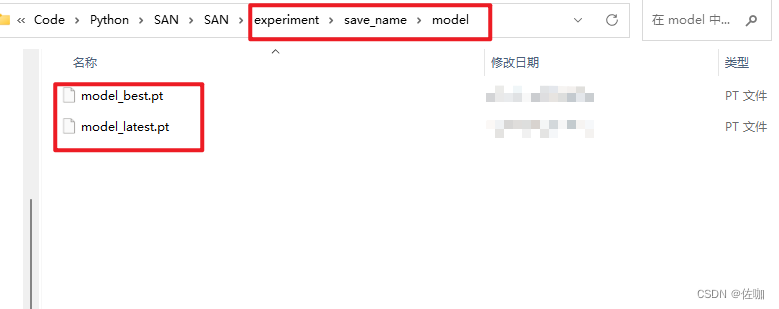
训练过程的模型权重会自动保存到根目录下的experiment文件夹中,如下:
六、推理测试
6.1 超参数修改
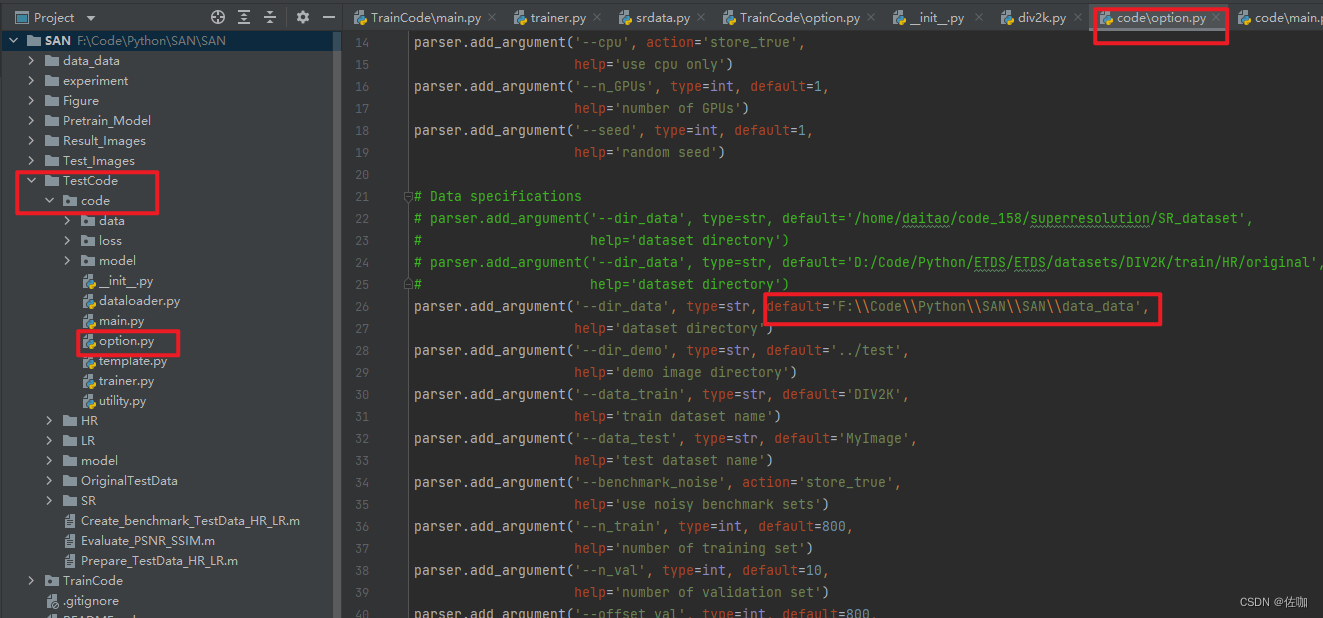
测试脚本有一个专门对应的配置文件,名字也是option.py,参数很多,自行根据情况修改,如下:
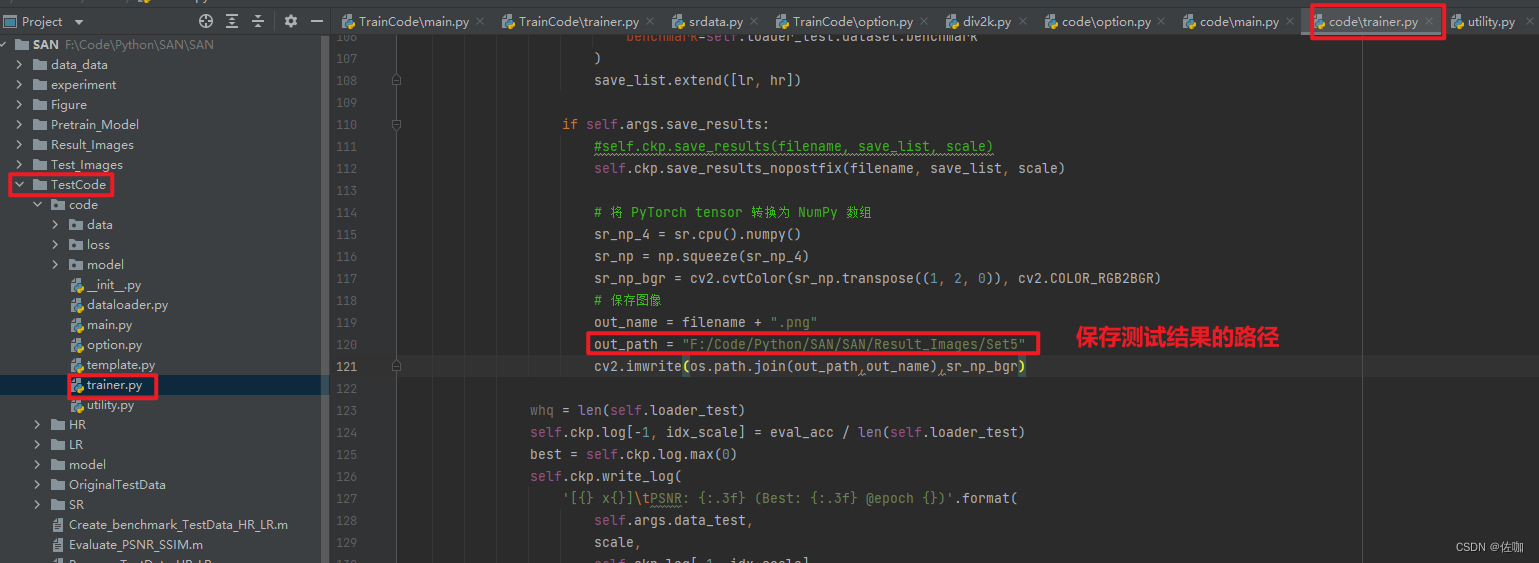
下面是修改测试结果的保存路径,这部分代码是我自己添加的,官网源码包中没有保存测试结果的脚本,如下:
6.2 测试
6.2.1 命令方式测试
在终端输入以下命令进入到测试脚本的路径下:
cd TestCode/code
再输入以下命令后回车测试:
python main.py --model san --data_test MyImage --save save_name --scale 4 --n_resgroups 20 --n_resblocks 10 --n_feats 64 --reset --chop --save_results --test_only --testpath F:/Code/Python/SAN/SAN/Test_Images/INF --testset Set5 --pre_train F:/Code/Python/SAN/SAN/experiment/save_name/model/model_best.pt --cpu
上面命令中可以修改超分倍数:–scale参数;测试集路径:–testpath;训练好的模型权重路径:–pre_train;其它参数自行修改
6.2.2 Configuration配置参数方式测试
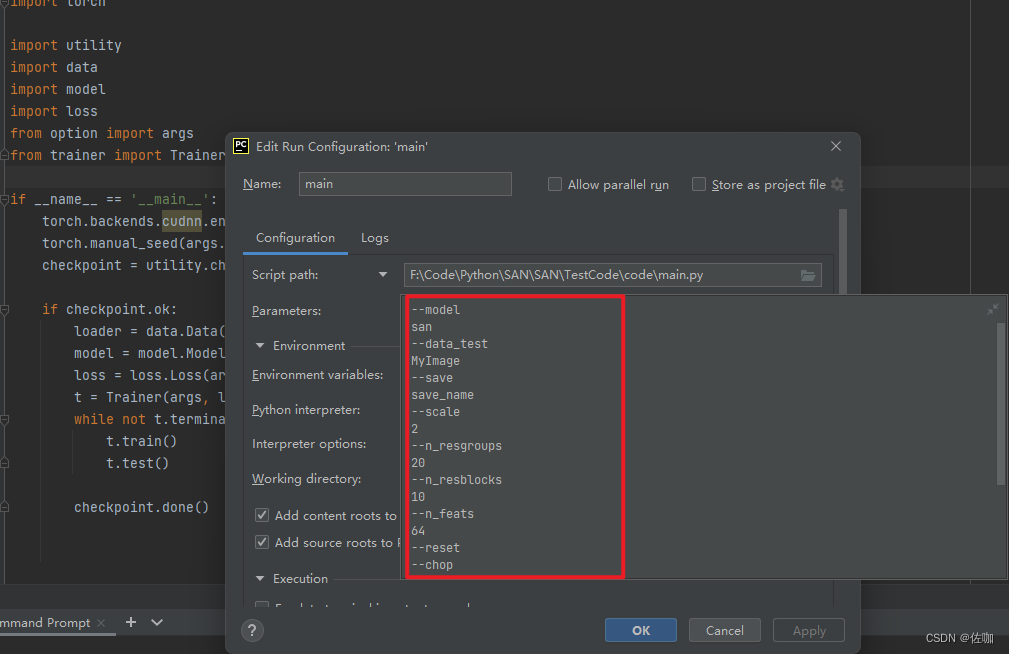

6.3 测试结果
运行过程如下:

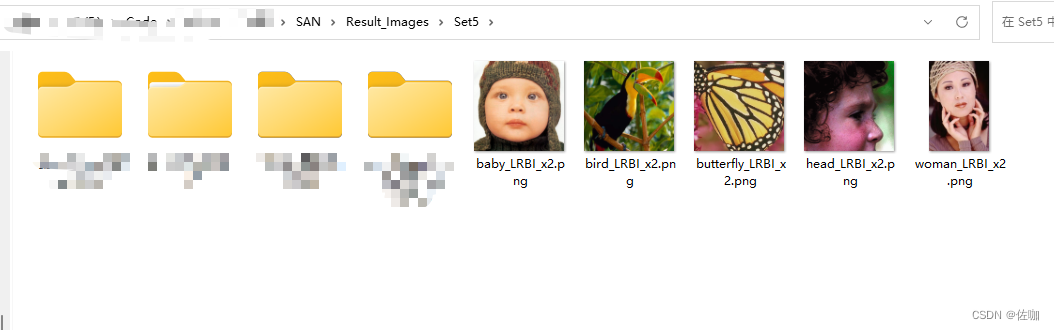
测试保存的结果图像在根目录Result_Images文件夹中,如下:
6.4 推理速度
我只在CPU上测试了推理速度,图像大小:12090,超分4倍,推理速度:12s/fps。图像大小512512,超分2倍,推理速度:39s/fps。
七、效果展示
下面左图为resize直接上采样4倍图,右侧为SAN模型超分4倍结果。





八、总结
以上就是超分辨率重建——SAN网络训练自己数据集及推理测试的详细图文教程,欢迎留言讨论。
总结不易,多多支持,谢谢!
















 1773
1773











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











