







 本文详细描述了一个项目,通过边缘提取、轮廓检测、透视变换和图像二值化,最终使用pytesseract进行文本识别,从发票图片中提取有效文字。
本文详细描述了一个项目,通过边缘提取、轮廓检测、透视变换和图像二值化,最终使用pytesseract进行文本识别,从发票图片中提取有效文字。
一、项目目的
尝试提取类似下图中发票中的有效文字

二、项目实现
1.边缘提取
首先,我们需要定义一个resize函数,用来等比缩放传入图片,防止图片长宽过大,导致边缘提取算法失效。下述函数是以宽度为优先进行等比缩放。
def resize(img,width=None,height=None,inter=cv2.INTER_AREA):#width,height为调整后的大小
size = None #是一个数组,存储缩放后的高宽数值
(h,w) = img.shape[:2]#取img.shape的前两个数值,高度宽度
if width == None and height==None:
return img#不做处理
if width == None:
r = height/float(h)
size = (int(w*r),height)#根据高度计算需要该的宽度
else:
r = width/float(w)
size = (width,int(h*r))
resize = cv2.resize(img, size, interpolation=inter)
return resize然后我们将图片转化为灰度图,进行图片的降噪压缩,同时保存副本,压缩比例,然后利用canny函数进行边缘检测
img = cv2.imread(r'C:\Users\yuehen\Desktop\text.jpg')
rate = img.shape[0]/500.0 #记录缩放倍率
origin = img.copy
img = resize(img,width=500)
grayimg = cv2.cvtColor(img , cv2.COLOR_BGR2GRAY)
grayimg = cv2.GaussianBlur(grayimg,(3,3),0)
border = cv2.Canny(grayimg,50,200)#双阈值检定,min50 max200可以根据实际情况调整
2.获取外轮廓
此时我们以及获得了大致的轮廓图,现在我们需要提取最外层的一个轮廓。现在图中有着很多个独立的轮廓,我们利用findContours将这些轮廓全部存入一个数组,然后对其进行排序,并保留前10个轮廓,排序依据选为周长。
b_array = cv2.findContours(border.copy(),cv2.RETR_LIST,cv2.CHAIN_APPROX_NONE)[1]
b_array = sorted(b_array, key=cv2.arcLength, reverse=True)[:10]#按周长进行降序排序,保留前10个轮廓实际应用上,可能会存在多段长段的迂回曲线,导致可能会遗失最外层轮廓,也可使用面积进行排序,或者适当放宽数组长度来降低遗失率。
b_array = sorted(b_array, key=cv2.contourArea, reverse=True)[:10]最后,我们对存留的是个轮廓进行遍历。但是这些轮廓不会有标准的形状,可能是歪曲的曲线,又或是密集的点形成的轮廓,这就需要利用approxPolyDP函数,将轮廓近似成常规图像,如三角形,矩形。然后根据需求去筛选需要的最外围轮廓。
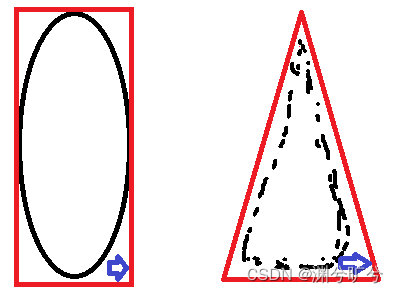
for i in b_array:
perimeter = cv2.arcLength(i, True)
#取轮廓周长
approx = cv2.approxPolyDP(i, 0.02 * perimeter, True)
#0.02 * peri的值表示了从原始轮廓到近似轮廓允许的最大距离,值越小越接近原始轮廓,但过于小可能就无法形成标准的形状,或是产生大量的端点数形成n边型
#True返回一个封闭的轮廓
if len(approx) == 4:
screenborder = approx
break
#当端点数为4个时基本符合矩形要求,将轮廓取出试运行,报错
b_array = sorted(b_array, key = cv2.contourArea, reverse = True)[:5]#降序排序
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
cv2.error: OpenCV(4.8.0) D:\a\opencv-python\opencv-python\opencv\modules\imgproc\src\shapedescr.cpp:315: error: (-215:Assertion failed) npoints >= 0 && (depth == CV_32F || depth == CV_32S) in function 'cv::contourArea'
查阅相关资料得知,在opencv3.4中find函数会输出image,countours,hierarchy三个数值,在更新4.0后,删除了image输出,此时我们需要去哦捕捉到边界端点应该去第一个输出值后缀改为[0],所以前面的关于轮廓近似处理的代码需要更改为:
b_array = cv2.findContours(border.copy(),cv2.RETR_LIST,cv2.CHAIN_APPROX_NONE)[0]
b_array = sorted(b_array, key=cv2.arcLength, reverse=True)[:10]#按周长进行降序排序,保留前10个轮廓成功运行,通过代码预览效果图,可以看到基本准确的标注了需要解析文字的区域。
cv2.drawContours(img, [screenborder], -1, (0, 0, 255), 3)
#-1表示回执所有轮廓,(0,0,255)是颜色代码,此处表示使用红色线条标注轮廓,3表示轮廓线条为3像素
cv2.imshow("Outline", img)
cv2.waitKey(0)
cv2.destroyAllWindows()
3.透视变换
很多时候我们的图片并不是正常的拍摄视角,不免会产生视角的歪曲或者倾斜,这边就需要利用透视变换,将图片变换为我们需要的角度。
要将一张倾斜角度的图片转换成正角度的图片,在这个项目中,我们要提取发票的相关信息,那么正角度应该是一个类矩形,我们可以通过透视变换来完成转换,简单提一下相关原理这需要一定的线性代数知识:首先,我们将2维图置于到三维一个平面,透视变换主要就是求解转换矩阵A,A是一个3*3的矩阵,为了便于计算取y=1的平面,我们让2维图记为图2,3维图记为图3,3维图就是原先的那张纸在空间中的形态,此时我们可以将图2看做图3在y=1平面的投影,所以我们图3上对应图2的点x,y值不变,顾我们能得出:[x,y,1]*T=A[x,y,z]*T这么一个方程组,那么我们就可以得到3个有关xyz的方程,其中,8个未知数,a33默认为1,一个点可以给我们提供2个方程,所以需要4个线性无关的点来计算转换转换矩阵,具体的请参考相关文档。
故定义一个处理函数transform代码如下:首先我们要获得轮廓的4个坐标点,并确定好左上、左下、右上、右下,随后基于各自最长的边作为长宽的取值,进行校正,利用opnecv的getPerspectiveTransform计算变换矩阵,并将矩阵输出
def transform(image, screenborder):
#获得4个坐标点
expoint = np.zeros((4, 2), dtype="float32")
# 用0填充一个容量为4,维度为2的数组,数组内值类型为float32
# 按顺序找到对应坐标0123分别是 左上,右上,右下,左下
# 计算左上,右下
s = screenborder.sum(axis=1)
#axis=1 行求和 =0列求和,然后返回一个包含和的数组输入(110,28)输出(138)
#行求和,最小就是左上,最大就是右下
expoint[0] = screenborder[np.argmin(s)]
expoint[2] = screenborder[np.argmax(s)]
# 计算相邻元素差值,行减输入(110,10)输出(-100),最小是右上,最大是左下
diff = np.diff(screenborder, axis=1)
expoint[1] = screenborder[np.argmin(diff)]
expoint[3] = screenborder[np.argmax(diff)]
(tl, tr, br, bl) = expoint
#获取四个端点,tl左上,tr右上,br,bl右下
# 计算输入的w和h值,以长边为校正基准
widthA = np.sqrt(((br[0] - bl[0]) ** 2) + ((br[1] - bl[1]) ** 2))
widthB = np.sqrt(((tr[0] - tl[0]) ** 2) + ((tr[1] - tl[1]) ** 2))
maxWidth = max(int(widthA), int(widthB))
heightA = np.sqrt(((tr[0] - br[0]) ** 2) + ((tr[1] - br[1]) ** 2))
heightB = np.sqrt(((tl[0] - bl[0]) ** 2) + ((tl[1] - bl[1]) ** 2))
maxHeight = max(int(heightA), int(heightB))
# 变换后对应坐标位置
dst = np.array([
[0, 0],
[maxWidth - 1, 0],
[maxWidth - 1, maxHeight - 1],
[0, maxHeight - 1]], dtype = "float32")
#以左上端点为原点只使用矩形部分其他区域去除
# 计算变换矩阵,expoint是源图4个端点,dts是目标对象4个端点位置
M = cv2.getPerspectiveTransform(expoint, dst)
transformation = cv2.warpPerspective(image, M, (maxWidth, maxHeight))
# 返回转换后结果
return transformation调用transform函数,直接输出在之前为resize的图片上,所以我们4个端点数值需要乘以压缩比例
transformation = transform(origin, screenborder.reshape(4, 2) * rate)这样我们就可以将一张图片转换为我们需要的视角以及只提取轮廓中的内容。
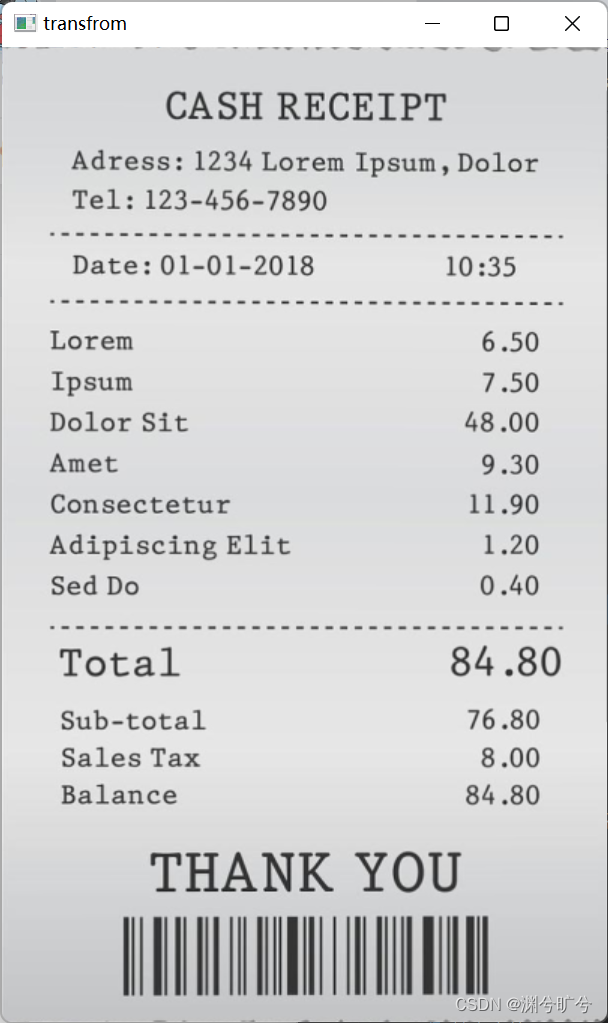
然后我们再做一个简单的二值化处理,将像素大于150的都置为255,这样可以把一些舍去一些不重要的信息
#二值化处理将像素值大于100的都按255输出
tran_gray= cv2.cvtColor(transformation, cv2.COLOR_BGR2GRAY)
binary = cv2.threshold(tran_gray, 150, 255, cv2.THRESH_BINARY)[1]
cv2.imwrite('scan.jpg', binary )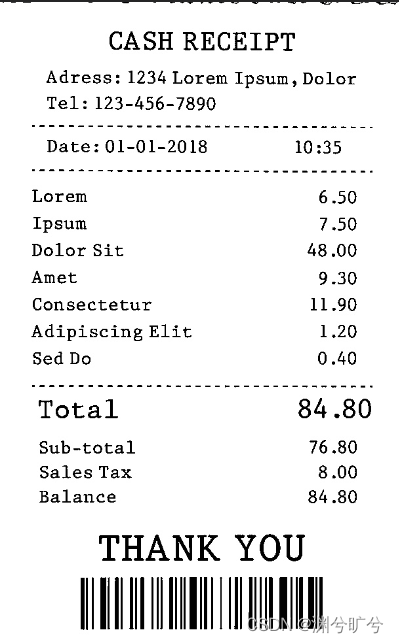
4.读取数据
最后利用pytesseract库实现数据提取
im=Image.open("scan.jpg")
text = pytesseract.image_to_string(im)
print(text) 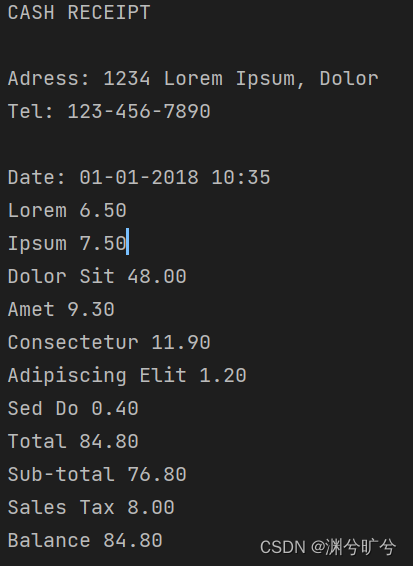
全部代码奉上,注意pytesseract库如果是windows使用,容易报错:拒绝访问,这边提供一种可能的解决方法:1.E:\python\Lib\site-packages\pytesseract文件夹(python环境安装路线)下找到pytesseract.py文件,将#tesseract_cmd = 'tesseract'改为tesseract_cmd = r'E:\Tesseract-OCR\tesseract.exe'(路径是你安装tesseract的路径指向exe文件)
import cv2
import numpy as np
import pytesseract
import os
from PIL import Image
def transform(image, screenborder):
#获得4个坐标点
expoint = np.zeros((4, 2), dtype="float32")
# 用0填充一个容量为4,维度为2的数组,数组内值类型为float32
# 按顺序找到对应坐标0123分别是 左上,右上,右下,左下
# 计算左上,右下
s = screenborder.sum(axis=1)
#axis=1 行求和 =0列求和,然后返回一个包含和的数组输入(110,28)输出(138)
#行求和,最小就是左上,最大就是右下
expoint[0] = screenborder[np.argmin(s)]
expoint[2] = screenborder[np.argmax(s)]
# 计算相邻元素差值,行减输入(110,10)输出(-100),最小是右上,最大是左下
diff = np.diff(screenborder, axis=1)
expoint[1] = screenborder[np.argmin(diff)]
expoint[3] = screenborder[np.argmax(diff)]
(tl, tr, br, bl) = expoint
#获取四个端点,tl左上,tr右上,br,bl右下
# 计算输入的w和h值,以长边为校正基准
widthA = np.sqrt(((br[0] - bl[0]) ** 2) + ((br[1] - bl[1]) ** 2))
widthB = np.sqrt(((tr[0] - tl[0]) ** 2) + ((tr[1] - tl[1]) ** 2))
maxWidth = max(int(widthA), int(widthB))
heightA = np.sqrt(((tr[0] - br[0]) ** 2) + ((tr[1] - br[1]) ** 2))
heightB = np.sqrt(((tl[0] - bl[0]) ** 2) + ((tl[1] - bl[1]) ** 2))
maxHeight = max(int(heightA), int(heightB))
# 变换后对应坐标位置
dst = np.array([
[0, 0],
[maxWidth - 1, 0],
[maxWidth - 1, maxHeight - 1],
[0, maxHeight - 1]], dtype = "float32")
# 计算变换矩阵
M = cv2.getPerspectiveTransform(expoint, dst)
transformation = cv2.warpPerspective(image, M, (maxWidth, maxHeight))
# 返回变换后结果
return transformation
def ishow(name,img):
cv2.imshow(name,img)#image是窗口名字
cv2.waitKey(0) #等待时间,毫秒级,0表示按任意键终止
cv2.destroyWindow(name)#关闭名字是image的窗口
def resize(img,width=None,height=None,inter=cv2.INTER_AREA):#width,height为调整后的大小
size = None #是一个数组,存储缩放后的高宽数值
(h,w) = img.shape[:2]#取img.shape的前两个数值,高度宽度
if width == None and height==None:
return img#不做处理
if width == None:
r = height/float(h)
size = (int(w*r),height)#根据高度计算需要该的宽度
else:
r = width/float(w)
size = (width,int(h*r))
resize = cv2.resize(img, size, interpolation=inter)
return resize
#对图片进行压缩,降噪以及边缘提取
img = cv2.imread(r'C:\Users\yuehen\Desktop\text.jpg')
rate = img.shape[0]/500.0 #记录缩放倍率
origin = img.copy()
img = resize(img,width=500)
grayimg = cv2.cvtColor(img , cv2.COLOR_BGR2GRAY)
grayimg = cv2.GaussianBlur(grayimg,(3,3),0)
border = cv2.Canny(grayimg,50,200)#双阈值检定,min50 max200可以根据实际情况调整
#ishow("Image", grayimg)
#ishow("Edged", border)
b_array = cv2.findContours(border.copy(),cv2.RETR_TREE,cv2.CHAIN_APPROX_SIMPLE)[0]
#retr_list检查所有轮廓,并保存到链表中,simple模式,只保留端点
b_array = sorted(b_array, key = cv2.contourArea, reverse = True)[:5]#降序排序
for i in b_array:
perimeter = cv2.arcLength(i, True)
#取轮廓周长
approx = cv2.approxPolyDP(i, 0.02 * perimeter, True)
#0.02 * peri的值表示了从原始轮廓到近似轮廓允许的最大距离,值越小越接近原始轮廓,但过于小可能就无法形成标准的形状,或是产生大量的端点数形成n边型
#True返回一个封闭的轮廓
if len(approx) == 4:
screenborder = approx
break
#当端点数为4个时基本符合矩形要求,将轮廓取出
cv2.drawContours(img, [screenborder], -1, (0, 0, 255), 3)
#-1表示回执所有轮廓,(0,0,255)是颜色代码,此处表示使用红色线条标注轮廓,3表示轮廓线条为3像素
#cv2.imshow("Outline", img)
#cv2.waitKey(0)
#cv2.destroyAllWindows()
transformation = transform(origin, screenborder.reshape(4, 2) * rate)
#二值化处理将像素值大于100的都按255输出
tran_gray = cv2.cvtColor(transformation, cv2.COLOR_BGR2GRAY)
binary = cv2.threshold(tran_gray, 150, 255, cv2.THRESH_BINARY)[1]
cv2.imwrite('scan.jpg', binary)
#输出
im=Image.open("scan.jpg")
text = pytesseract.image_to_string(im)
print(text)


















 985
985

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











