








Introduction


时间序列的分类、聚类 有许多应用,研究者们开发了许多算法。基于 DTW 的最近邻分类器 凭借其 非线性匹配能力 脱颖而出。然后简介了一下DTW及其应用领域。




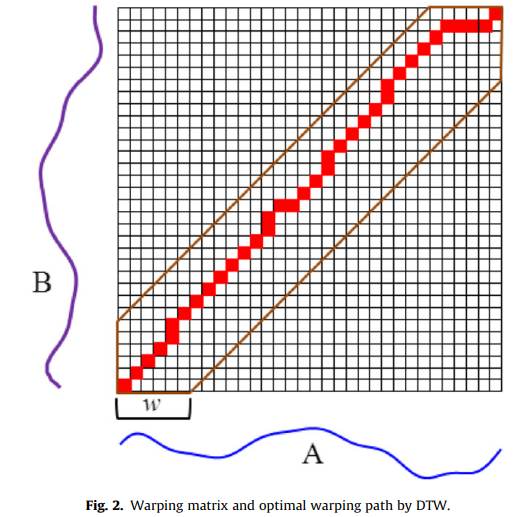
DTW 算法可参考:Dynamic Time Warping 动态时间规整 —— ww的CSDN博客

提出 DTW 的缺点:不考虑参考点和待测点之间的相位差异,对每个点赋予相同的权重。这可能会导致一些错误分类(misclassification)。尤其当两个序列的形状相似性是精确识别的主要因素时,两个序列之间的近邻点(neighboring points)会比其他点更重要。因此,实际应用中,应当考虑 点与点之间的相位差异。

因此,本文提出了一种新型的距离度量—— 加权动态时间规整(WDTW,weighted dynamic time warping)。WDTW会基于参考点与待测点之间的相位差异,为相近的点更高的权重。该方法可以防止一个序列中的一个点与另一个序列中更远的点相匹配,从而减少意外奇点(unexpected singularities)。意外奇点 表示 一个序列中的一个点 与 另一个序列中的很多点 相匹配。

此外,本研究还提出了一种 新的权重函数:MLWF(modified logistic weight function),该函数将权重看作 参考点与待测点之间的相位差异 的一个函数。

最后,本文还将上述思想拓展到了其他 DTW 的变体,比如 DDTW → WDDTW。 并将本文的结果与一个公开数据集(E. Keogh等,2006)对比。结果显示本文的思想可以提高时间序列分类和聚类问题的精度。
E. Keogh, X. Xi, L. Wei, C.A. Ratanamahatana, The UCR Time Series Data Mining Archive. Available at: /http://www.cs.ucr.edu/eamonn/time_series_dataS, 2006.
Related works

[21] T.M. Rath, R. Manmatha, Word image matching using dynamic time warping, in: Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2003.

[11] E. Keogh, M. Pazzani, Derivative dynamic time warping, in: Proceedings of the SIAM International Conference on Data Mining, Chicago, 2001.
[27] Y. Xie, B. Wiltgen, Adaptive feature based dynamic time warping, International Journal of Computer Science and Network Security 10 (2010) 264–273
Rationale for the performance advantages of WDTW
通过几个例子分析 WDTW 比 DTW 表现更好的原理。
例1:semiconductor wafer maps 上 次品图案(defect patterns)的自动分类
次品图案 及其 空间相关图
Fig. 3(a)–(d) 显示了 defect patterns 的常见类型。原始影像为二值图,1(黑)表示 次品(defective chip),0(白)表示 好品(good chip)。
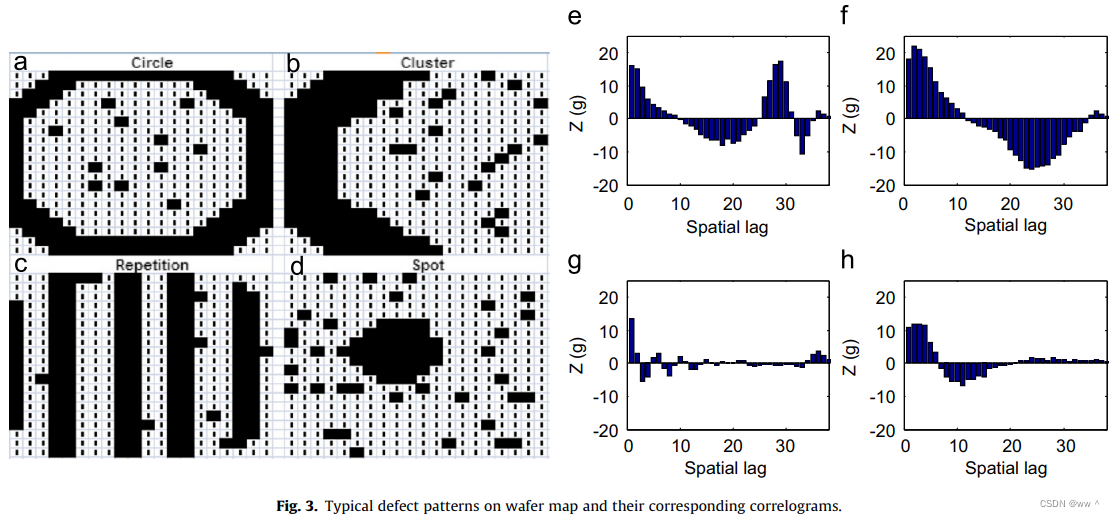
Y.S. Jeong 等人展示了 spatial correlograms(空间相关图,即 时间序列数据)作为分类特征的优越性。Fig. 3(e)–(h) 显示了 Fig. 3(a)–(d) 对应的空间相关图。空间相关图的 x 轴表示 空间间隔(spatial lag),y 轴为其 统计值。
给定 次品率p 和 空间间隔d,标准值 T(d) 为![]() 。
。![]() 表示一张图中 次品-次品 连接(join)的 lag 为 d 的数量,
表示一张图中 次品-次品 连接(join)的 lag 为 d 的数量,![]() 表示 好品-好品 连接的 lag 为 d 的数量。
表示 好品-好品 连接的 lag 为 d 的数量。
T(d) 值较大,距离 参考次品格点 的 lag 为 d 的近邻中会有更多的次品格点。T(d) 值较小,则与参考次品格点 lag 为 d 的近邻中会有更多的好品格点。
比如 Fig. 3(f) 中:lag 为 1 – 5 时,T(d) 值较大;说明距离参考次品格点的距离为 1 - 5 的格点中,次品较多。lag 为 20 – 30 时,T(d) 值是一个较大的负数;距离参考次品格点的距离为 20 - 30 的格点中,好品格点较多。
[9] Y.S. Jeong, S.J. Kim, M.K. Jeong, Automatic identification of defect patterns in semiconductor wafer maps using spatial correlogram and dynamic time warping, IEEE Transactions on Semiconductor Manufacturing 21 (2008) 625–637.
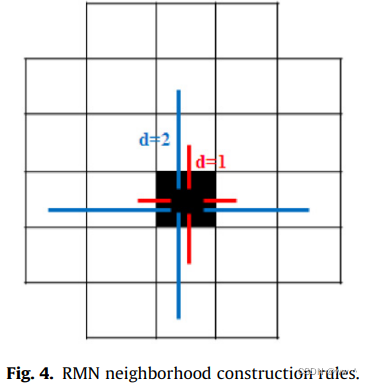
Fig.4. 显示了 lag 为 d 的近邻(连接)的定义。该定义基于Rook-move neighborhood (RMN) 构建规则。图中,黑色方形表示一个参考格点,红色线表示间隔为 1 的近邻格点,蓝色线表示间隔为 2 的近邻格点。
因此,比较两个空间相关图在 lag 相同时的 T(d) 值,对于次品图案分类很有意义。
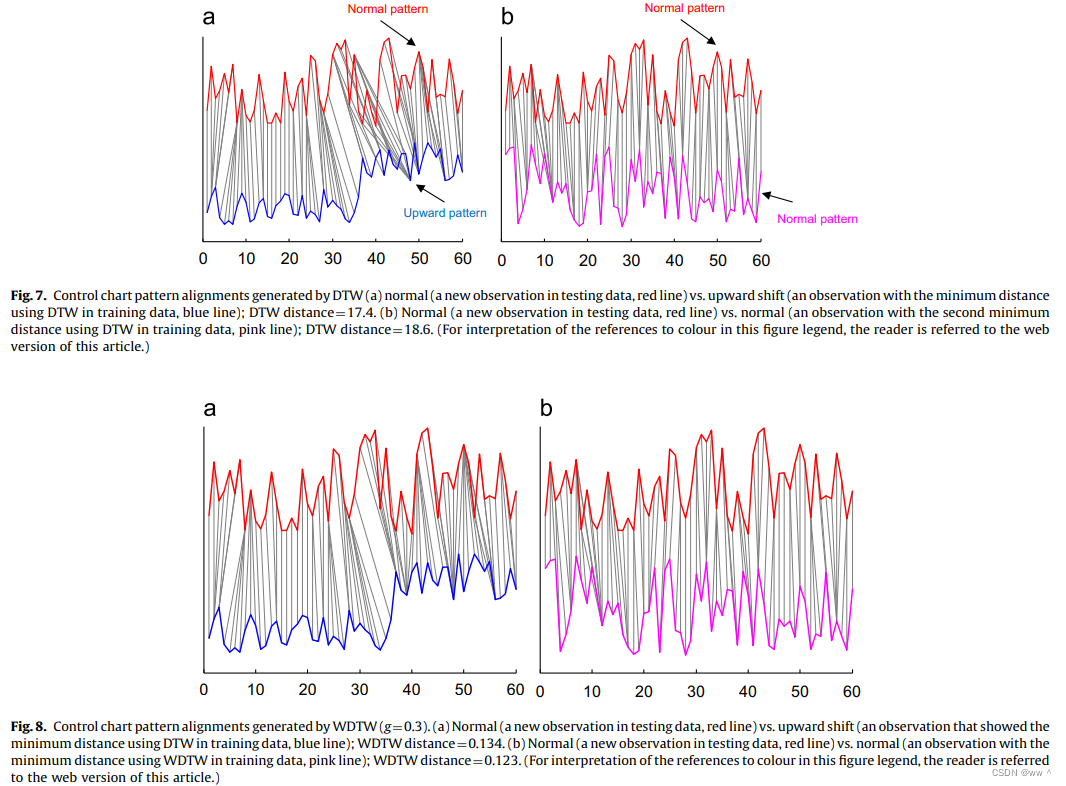
DTW 和 WDTW 次品图案分类的结果
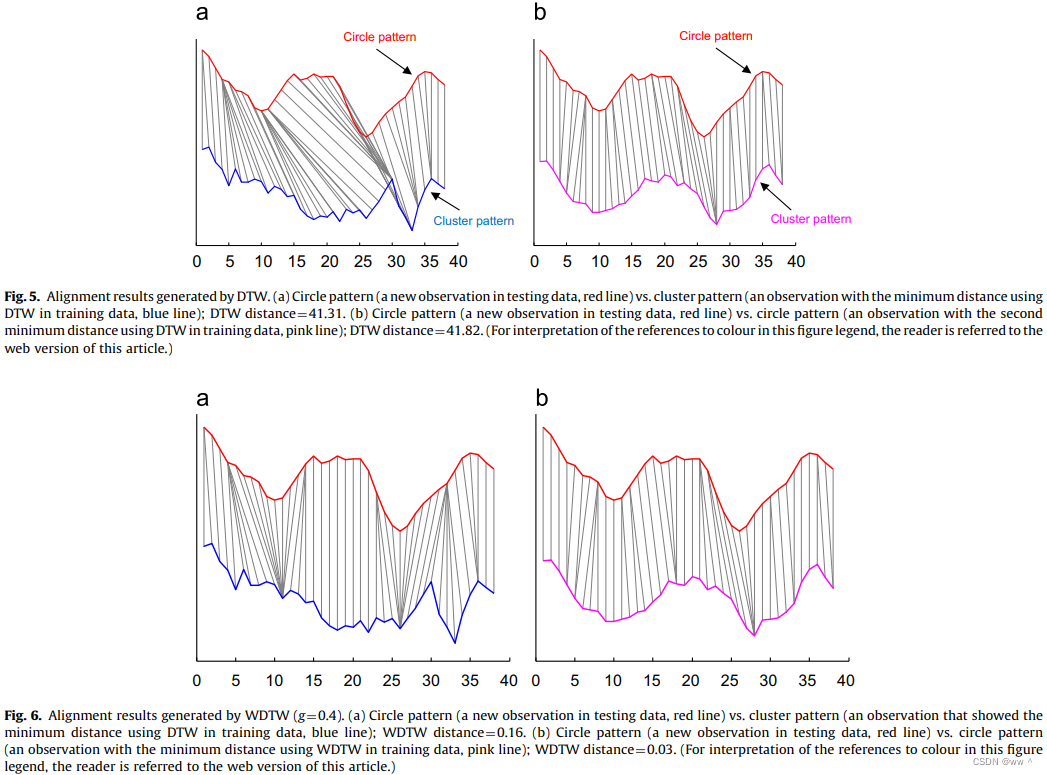
Fig. 5 和 Fig. 6 显示了使用 DTW 和 WDTW 进行次品图案分类的结果。红色线表示待测序列,蓝线和粉线都是训练数据集中的序列。
Fig. 5(a) 显示 在训练数据集中与待测序列最小的 DTW 距离为 41.31,Fig. 5(b) 显示第二小的 DTW 距离为41.82。使用 DTW 时,待测序列中的某些点会和另一个序列中更远的点相匹配。因此,circle 图案 可能会错分类到 cluster 图案。
但是,WDTW 会给相位差异更大的点赋予更高的代价(惩罚),从而防止某个序列中的点与另一个序列中更远的点相匹配。Fig. 6 显示,使用 WDTW,circle 图案 会正确地分类到 circle。
例 2:‘‘UCR Time Series Data Mining Archive’’
Proposed algorithm for time series classification
Weighted dynamic time warping (WDTW)
关键思想:相位差异越小,权重越小(惩罚越少)。邻近点比更远的点更重要。
在 WDTW 算法中,在建立 m×n 矩阵时,![]() 和
和![]() 两个点之间的距离计算公式为
两个点之间的距离计算公式为![]() ,其中,
,其中,![]() 是两个点之间的一个权重值(正数)。在计算 序列 A 中的
是两个点之间的一个权重值(正数)。在计算 序列 A 中的![]() 点 与 序列 B 中的
点 与 序列 B 中的![]() 点之间的距离时,权重值由其相位差
点之间的距离时,权重值由其相位差![]() 决定。两个序列之间的最佳距离 为 矩阵内所有可能路径中距离最小的路径,如下所示:
决定。两个序列之间的最佳距离 为 矩阵内所有可能路径中距离最小的路径,如下所示:
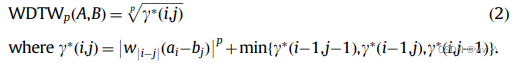
当两个序列的长度分别为 m 和 n 时,WDTW 和 DTW 的时间复杂度相同,都是 O(mn)。
WDTW 的一些性质:
![]()

[3] G.B. Folland, Real Analysis. Modern Techniques and their Applications, Wiley, New York, 1999.
![]()
![]()
![]()

[15] D. Lemire, Faster retrieval with a two-pass dynamic-time-warping lower bound, Pattern Recognition 42 (2009) 2169–2180.

[17] M.D. Morse, J.M. Patel, An efficient and accurate method for evaluating time series similarity, in: Proceedings of the ACM SIGMOD International on Information and Knowledge Management, 2006, pp. 14–23.
Modified logistic weight function (MLWF)
logistics function 是 最受欢迎的 仅使用一个等式 的 经典对称函数。不过,该函数的标准形似在设置边界的阈值时不够灵活。本文提出一种改进版的logistics函数,权重值![]() 由下式定义:
由下式定义:
![]()
其中:i = 1, ... , m, m 为 序列的长度。![]() 表示 序列的中点(midpoint)。
表示 序列的中点(midpoint)。![]() 是权重参数所需的上限。
是权重参数所需的上限。![]() 是一个经验值,控制着函数的 曲率/斜率(curvature/slope),即 对相位差较大的点的惩罚等级;
是一个经验值,控制着函数的 曲率/斜率(curvature/slope),即 对相位差较大的点的惩罚等级;![]() 值最小为 0,无上限。
值最小为 0,无上限。
MLWF 的 4 种特殊情况:
(1) 常数权重(Constant weight):所有点的权重相同。可以通过设置 g = 0 来实现。
(2) 线性权重(Linear weight):权重与距离线性相关。当 g = 0.05 时,![]() 基本呈线性增长。
基本呈线性增长。
(3) Sigmoid weight:使用不同的 g 值,可以形成不同的 sigmoid 图案。
(4) Two distinct weights:前一半用一个权重值,后一半用另一个权重值。当 g = 3 时基本可以达到这种效果。
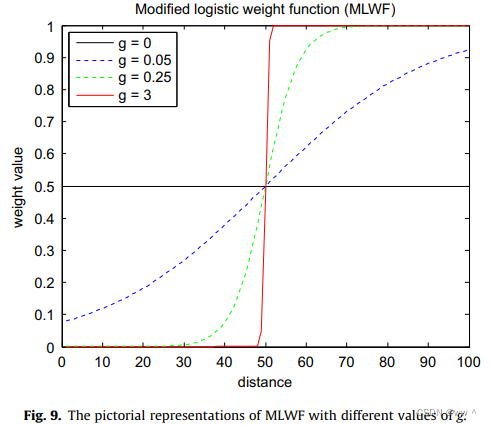
实际上,原始 DTW 和 欧氏距离,都是 WDTW 的特殊情况。当![]() 是一个常数(g = 0)时,WDTW 的效果和 原始 DTW 一样。当
是一个常数(g = 0)时,WDTW 的效果和 原始 DTW 一样。当 ![]() 变小(g变大)时,相位相近的两个点之间的距离接近于欧氏距离,此时它们都不允许点与点进行非线性匹配。
变小(g变大)时,相位相近的两个点之间的距离接近于欧氏距离,此时它们都不允许点与点进行非线性匹配。
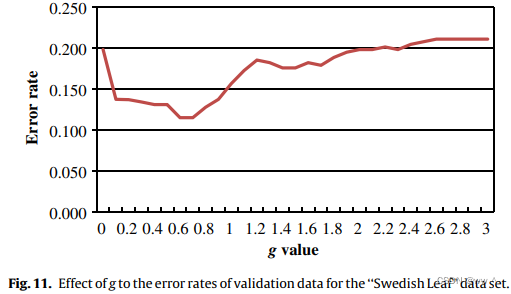
基于本研究的经验值,g 的最佳值是 0.01 - 0.6。
Weighted derivative dynamic time warping (WDDTW)
DDTW:derivative dynamic time warping,导数动态时间规整。
为了解释 y 轴上的变异性,DTW 可能会扭曲 x 轴。为解决该问题,DDTW 将 原始点 转换成 更高级的特征,该特征包含了序列的形状信息。转换 序列A 中的 点![]() 的公式为:
的公式为:![]() ,
,![]() ,
,![]() 。其中,m 是 序列A 的长度。
。其中,m 是 序列A 的长度。
DDTW 的 权重版为:![]() 。其中,
。其中,![]() 和
和![]() 分别是 序列 A 和 B 经过转换后的序列,
分别是 序列 A 和 B 经过转换后的序列,![]() 。
。
Experimental results
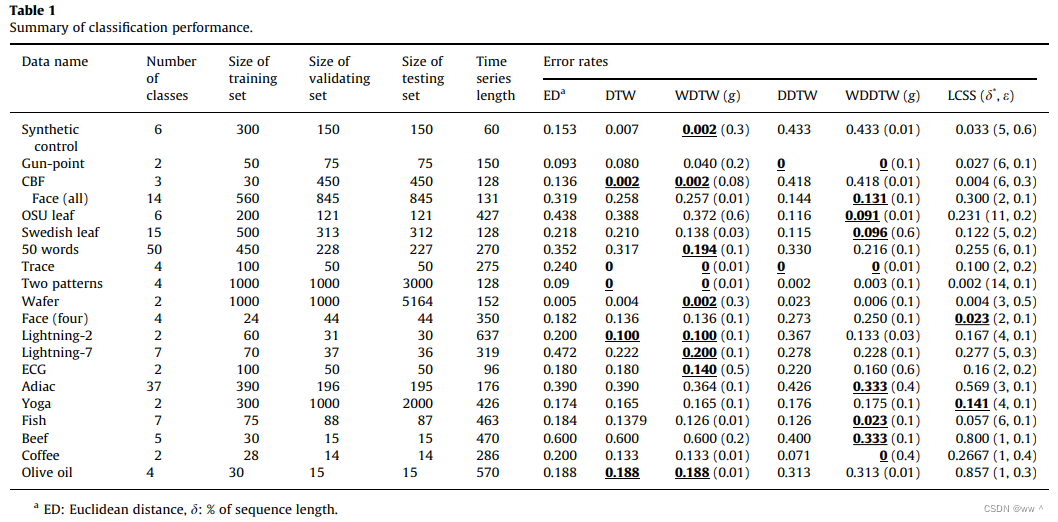
Performance comparison for time series classification
![]()
Effect of parameter values in WDTW

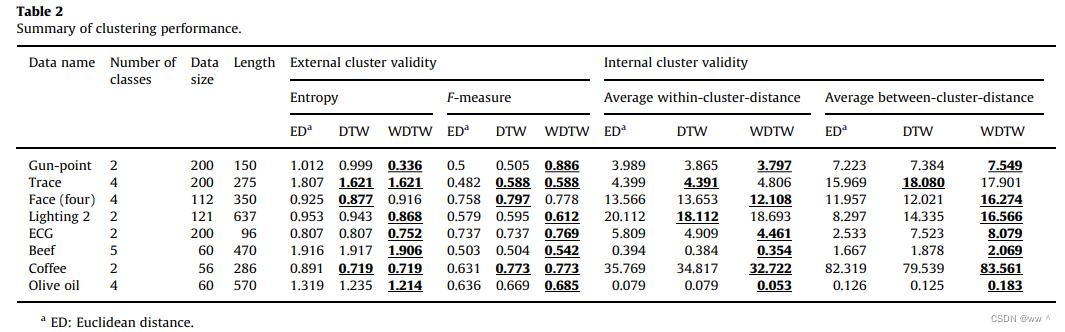
Performance comparison for time series clustering

Conclusion
















 3471
3471











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









